
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис.
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•среды и языка программирования,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•накопление погрешностей результатов вычислений (рис.
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см. § 2. 7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Отладка может будет утомительной и мучительной, если вы не подготовите свою программу к отладке. В духе «пейте, дети, молоко — будете здоровы», в этой статье предлагаются подходы к написанию кода, который легче отладить, способы предотвращения проблем и некоторые подводные камни.
Используйте правильные инструменты
Само собой разумеется, что вы всегда должны использовать лучшие из доступных инструментов. Если вы ищите ошибки сегментации, используйте отладчик, он облегчит ваши страдания. Если вы имеете дело со странными проблемами памяти (или трудно диагностируемыми ошибками сегментации), используйте Valgrind на Linux или Purify для Windows.
Проблемы отладки
Первое, что приходит на ум при отладке, это вопрос: «Мой код слишком сложный?» Иногда мы находим решение проблемы и понимаем, что оно слишком сложное для реализации. Настолько сложное, на самом деле, что может быть проще решить эту проблему по-другому. Когда я вижу, как кто-то пытается отладить сложный код, первое, о чем я хочу спросить: «Есть ли более простое решение?». Часто, когда вы напишите плохой код, у вас появляется представление о том, как должен выглядеть хороший код. Помните, что вы не должны хранить код только потому, что вы его написали!
Хитрость заключается в умении определить, пытаетесь ли вы решить исходную задачу или найти конкретное решение. Если это решение, то вполне возможно, что ваши проблемы не связаны с исходной задачей вообще — может быть, вы слишком много думаете о задаче или неправильно к ней подходите. Например, недавно мне пришлось обработать файл и импортировать некоторые данные для доступа к базе данных для создания прототипа инструмента анализа. Моим первым побуждением было написать скрипт на Ruby, который обращается непосредственно к Access и вставляет все данные в базу с помощью SQL запросов. Когда я посмотрел на поддержку этого в Ruby, я быстро понял, что мое «решение» проблемы займет намного больше времени, чем я предполагал. И я поступил по-другому, написал скрипт, который просто выводит значения в csv файл, и мои данные полностью импортировались за час.
Плохой код
Люди часто не хотят избавляться от плохого кода, который они написали, и переписывают его. Одна из причин — это то, что написанный код кажется завершенной работой, и избавляясь от него, вы как бы движетесь в обратном направлении. Но при отладке, переписывание кода может показаться более привлекательным, потому что вы экономите время при отладке, потратив немного больше времени на кодирование. Хитрость заключается в том, чтобы избежать удаления кода, чтобы не начинать всю программу снова (если только она не вся насквозь ужасна). Перепишите только те части, которые действительно в этом нуждаются.
Ваш второй проект, вероятно, будет понятнее и с меньшим количеством ошибок, чем первый, и вам, возможно, не придется возвращаться и переписывать код, потому что вы можете выяснить, как он должен работать.
С другой стороны, когда вы абсолютно уверены, что код, который выглядит ужасно, подходит для использования, вы захотите обосновать это в комментариях, чтобы кому-то (или вам) не пришлось возвращаться и исправлять его.
Минимизируйте потенциальные проблемы, избегая синдрома “копировать/вставить”
Нет ничего более ужасного, чем осознать, что вы отлаживаете одну и ту же проблему несколько раз. Всякий раз, когда вы копируете и вставляете большие куски кода, вы подвергаетесь нападению неизвестных демонов, населяющих этот код. Если вы еще не занялись отладкой, то, вероятно, придется. И если вы забыли, что вы скопировали код куда-то в другое место, вы, вероятно, будете отлаживать один и тот же код несколько раз. Есть и другие причины избегать синдрома “копировать/вставить”, еще хуже, чем отладить один и тот же код дважды, — это найти ошибку только в одном куске скопированного кода.
Лучший способ избежать синдрома “копировать/вставить” заключается в использовании в вашем коде функции для инкапсуляции столько раз, сколько это возможно. Некоторых вещей не так легко избежать в C++. Вам придётся писать много циклов независимо от того, что вы делаете, так что вы не можете абстрагироваться от всех циклов. Но если у вас одно и то же тело цикла в нескольких местах, это может быть признаком того, что такой код следует вывести в отдельную функцию. В качестве бонуса, это делает другие будущие изменения в коде проще и позволяет повторно использовать функцию без надобности поиска куска кода для копирования.
Когда копировать код
Хотя копировать код, как правило, опасно, бывают случаи, когда это может быть лучшим решением. Например, если вам нужно иногда сделать небольшую корректировку куска кода, а большая его часть должна оставаться такой же, то копирование, вставка и тщательное редактирование может иметь смысл. При копировании кода можно избежать новых ошибок. Само собой разумеется, что вы должны тщательно отладить код перед копированием!
Вторая причина для копирования кода — это длинные имена переменных и плохой текстовый редактор. Самое лучшее решение, как правило, это хороший текстовый редактор с завершением по ключевым словам (автокомплит зарезервированных слов).
Найдите маленькие проблемы раньше, чтобы потом найти большие проблемы
Одним из преимуществ выделения кода в функции является то, что вы можете отдельно проверить эти функции. Это означает, что иногда можно избежать отладки больших проблем, вызванных ошибками в простых первоначальных функциях. Нет ничего хуже, чем написать правильный код, дать ему, по-вашему мнению, работающую функцию (или класс), только для того, чтобы узнать, что она не работает должным образом. Такое модульное тестирование требует определенной дисциплины и понимания того, что с вашим кодом может пойти не так.
Еще одно преимущество раннего тестирования — особенно, если вы пишете все или некоторые из ваших тестов заранее, до кода — это то, что вы будете уделять больше внимания конкретным интерфейсам вашего класса. Если вы не можете проверить обработку ошибок, потому что вы используете assert вместо исключений или кодов ошибок, это может быть признаком того, что вам стоит использовать какие-нибудь отчеты об ошибках, а не assert-ы. (Конечно, так будет не всегда — бывают моменты, когда вам просто надо убедиться, что ваши assert-ы работают правильно. ) Помимо отчетов об ошибках, написание тестов — это время когда вы можете в первый раз проверить интерфейс вашего кода, который обычно так же важен, как и тестирование работы кода. Если интерфейс вашего класса неуклюжий или ваши функции невозможно понять, не говоря уже о списках аргументов, настало время переосмыслить то, что вы делаете, прежде чем писать остальной код.
Предупреждения компилятора
Многие потенциальные ошибки могут быть обнаружены компилятором. Некоторые из таких ошибок включают в себя использование неинициализированных переменных, случайно заменив проверку на равенство с заданием в условном выражении, или, в C++ — ошибки, связанные с смешением типов, таких как указатели и целые. Так как об этом говорилось ранее, я предлагаю вам самостоятельно найти информацию о предупреждениях компилятора.
Printf лжет
Поскольку ввод/вывод, как правило, буферизуется операционной системой, использование printf в процессе отладки рискованно. По возможности используйте отладчик, чтобы выяснить, в каких строках кода — ошибка, вместо того чтобы находить место путем вставки printf в код. (И остерегайтесь одиноких printf, которые остались после отладки и проскальзывают в финальной версии).
Тем не менее, бывают случаи, когда вам действительно нужно отслеживать состояние в лог-файле — возможно, вам просто нужно собрать слишком много данных, и вам нужны данные от запуска программы до момента появления ошибки. Чтобы обеспечить сбор всех данных, обязательно сбросьте его: вы можете использовать fflush в C, или оператор endl в C++. fflush принимает указатель файла, в который вы пишете, например, чтобы сбросить stderr, можно было бы написать fflush( stderr);
Проверяйте вспомогательные функции
Вроде очевидно, но это то, что легко забыть в запале работы: всегда проверяйте работу вспомогательных функций, особенно когда казалось бы простой код, а не работает. Если возможно, изолируйте вспомогательные функцию и проверьте каждую отдельно. Нет ничего хуже, чем осознать, что первоначально вы были правы, но ваше предположение о вспомогательной функции было неверно.
Когда ошибка не приводит к немедленному эффекту
Даже если вспомогательная функция не является непосредственным источником проблемы, ее побочные эффекты могут привести к скрытым проблемам. Например, если у вас есть вспомогательная функция, которая может возвращать NULL и вы передаете ее выход в библиотечную функцию, имеющую дело с Cи-строками, вы можете увидеть ошибку разыменования указателя NULL в strcat, но настоящая ошибка была в глючной функции, которую вы написали ранее (или то, что вы не проверили NULL после его вызова).
Помните, что код может быть использован в более чем одном месте
Еще одна проблема, которая может произойти при отладке — это то, что вы обнаруживаете появление проблемы в какой-либо функции, устанавливаете точку останова внутри этой функции, а затем обнаруживаете, что существуют сотни вызовов этой же функции в коде. Или еще хуже, вы не замечаете этого, тратите уйму времени пытаясь выяснить, что происходит, или думаете, что причина проблемы в том, что функция вызывается неправильно. (Когда, на самом деле, она вызывается правильно, но с аргументами, отличными от точки, в которой произошла ошибка
Наиболее очевидным решением является проверка стека вызовов после установки точки останова или установка точки останова прямо перед вызовом, который на самом деле и является проблемой. К сожалению, это не помогает в тех случаях, когда 1000 вызовов работают корректно, а ошибка происходит на 1001-м. Потенциальные решения включают в себя подсчет количества вызовов функции, а затем нужное количество раз пропускать точку останова, установленную внутри функции, или с использованием статических переменных, таких как счетчик.
Приготовьте отладчик! Пишем приложение с ошибками, затем учимся их находить и дебажить

Иногда в приложении встречаются ошибки, которые нельзя увидеть даже после запуска. Например, код компилируется, проект запускается, но результат далёк от желаемого: приложение падает или вдруг появляется какая-то ошибка (баг). В таких случаях приходится «запасаться логами», «брать в руки отладчик» и искать ошибки.
Часто процесс поиска и исправления бага состоит из трёх шагов:
- Воспроизведение ошибки — вы понимаете, какие действия нужно сделать в приложении, чтобы повторить ошибку.
- Поиск места ошибки — определяете класс и метод, в котором ошибка происходит.
- Исправление ошибки.
Если приложение не падает и чтение логов ничего не даёт, то найти точное место ошибки в коде помогает дебаггер (отладчик) — инструмент среды разработки.
Чтобы посмотреть на логи и воспользоваться дебаггером, давайте напишем простое тестовое (и заведомо неправильное) приложение, которое даст нам все возможности для поиска ошибок.
Это будет приложение, которое сравнивает два числа. Если числа равны, то будет выводиться результат «Равно», и наоборот. Начнём с простых шагов:
- Открываем Android Studio.
- Создаём проект с шаблоном Empty Activity.
- Выбираем язык Java, так как его, как правило, знают больше людей, чем Kotlin.
Нам автоматически откроются две вкладки: activity_main. xml и MainActivity. java. Сначала нарисуем макет: просто замените всё, что есть в activity_main. xml, на код ниже:
Можете запустить проект и посмотреть, что получилось:
Теперь оживим наше приложение. Скопируйте в MainActivity этот код:
В этом коде всё просто:
- Находим поля ввода, поле с текстом и кнопку.
- Вешаем на кнопку слушатель нажатий.
- По нажатию на кнопку получаем числа из полей ввода и сравниваем их.
- В зависимости от результата выводим «Равно» или «Не равно».
Запустим приложение и введём буквы вместо чисел:
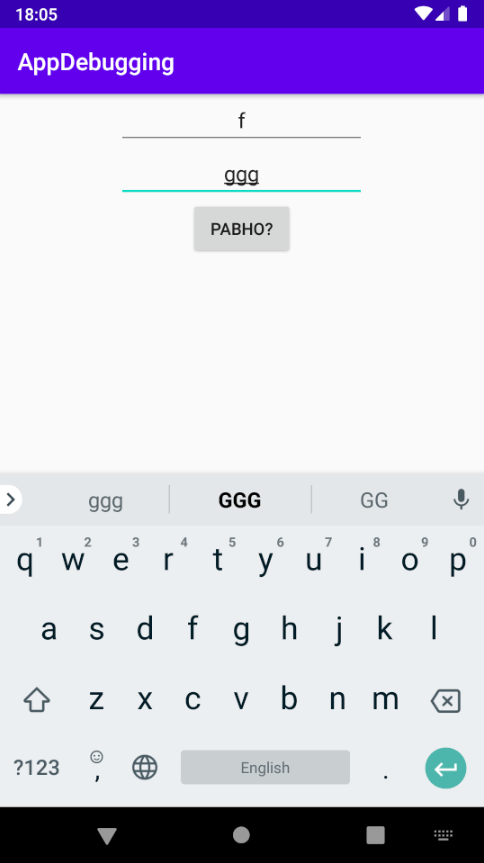
Нажмём на кнопку, и приложение упадёт! Время читать логи. Открываем внизу слева вкладку «6: Logcat» и видим:
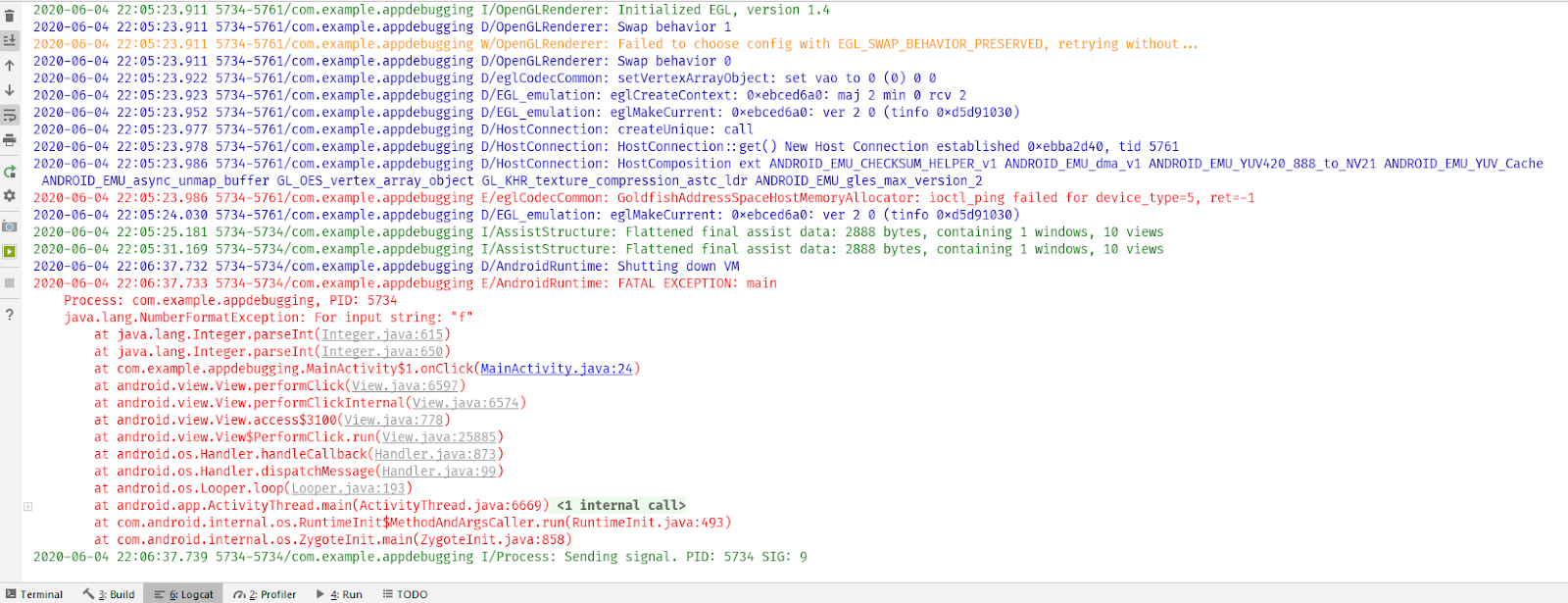
Читать логи просто: нужно найти красный текст и прочитать сообщение системы. В нашем случае это java. lang. NumberFormatException: For input string: «f». Указан тип ошибки NumberFormatException, который говорит, что возникла какая-то проблема с форматированием числа. И дополнение: For input string: «f». Введено “f”. Уже можно догадаться, что программа ждёт число, а мы передаём ей символ. Далее в красном тексте видно и ссылку на проблемную строку: at com. example. appdebugging. MainActivity$1. onClick(MainActivity. java:26). Проблема в методе onClick класса MainActivity, строка 24. Можно просто кликнуть по ссылке и перейти на указанную строку:
firstInt. first.
Конечно, метод parseInt может принимать только числовые значения, но никак не буквенные! Даже в его описании это сказано — и мы можем увидеть, какой тип ошибки этот метод выбрасывает (NumberFormatException).

Здесь мы привели один из примеров. Типов ошибок может быть огромное количество, все мы рассматривать не будем. Но все ошибки в Logcat’е указываются по похожему принципу:
- красный текст;
- тип ошибки — в нашем случае это NumberFormatException;
- пояснение — у нас это For input string: «f»;
- ссылка на строку, на которой произошла ошибка — здесь видим MainActivity.java:26.
Исправим эту ошибку и обезопасим себя от некорректного ввода. Добавим в наши поля ввода android:inputType=»number», а остальной код оставим без изменений:
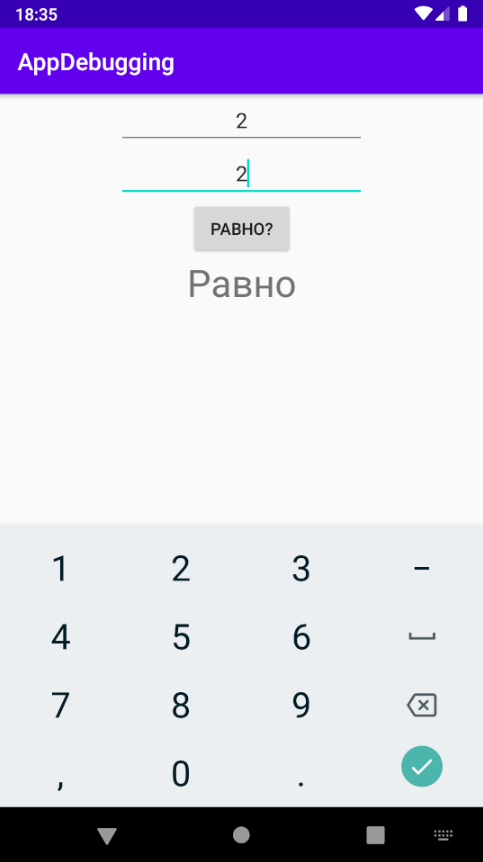
Теперь можем вводить только числа. Проверим, как работает равенство: введём одинаковые числа в оба поля. Всё в порядке:
На равенство проверили. Введём разные числа:
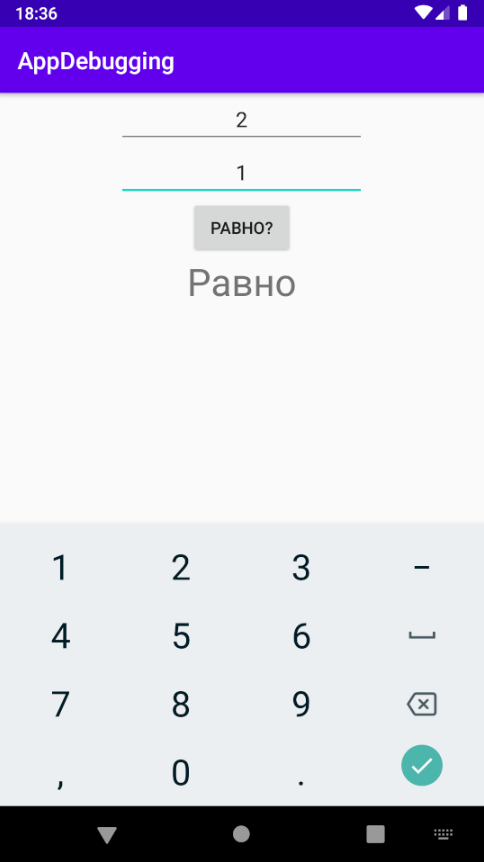
Тоже равно. То есть приложение работает, ничего не падает, но результат не совсем тот, который требуется. Наверняка вы и без дебаггинга догадались, в чём ошибка, потому что приложение очень простое, всего несколько строк кода. Но такие же проблемы возникают в приложениях и на миллион строк. Поэтому пройдём по уже известным нам этапам дебаггинга:
- Воспроизведём ошибку: да, ошибка воспроизводится стабильно с любыми двумя разными числами.
- Подумаем, где может быть ошибка: наверняка там, где сравниваются числа. Туда и будем смотреть.
- Исправим ошибку: сначала найдём её с помощью дебаггера, а когда поймём, в чём проблема, — будем исправлять.
И здесь на помощь приходит отладчик. Для начала поставим точки останова сразу в трёх местах:
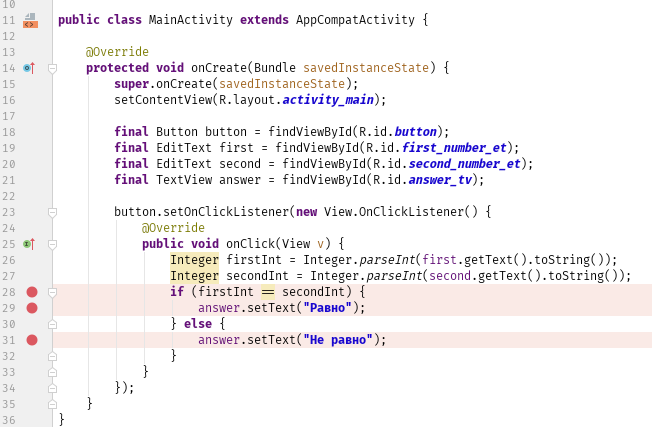
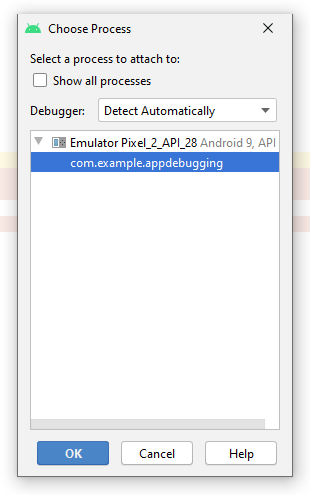
Чтобы поставить или снять точку останова, достаточно кликнуть левой кнопкой мыши справа от номера строки или поставить курсор на нужную строку, а затем нажать CTRL+F8. Почему мы хотим остановить программу именно там? Чтобы посмотреть, правильные ли числа сравниваются, а затем определить, в какую ветку в нашем ветвлении заходит программа дальше. Запускаем программу с помощью сочетания клавиш SHIFT+F9 или нажимаем на кнопку с жучком:
Появится дополнительное окно, в котором нужно выбрать ваш девайс и приложение:
Вы в режиме дебага. Обратите внимание на две вещи:
- Точки останова теперь помечены галочками. Это значит, что вы находитесь на экране, где стоят эти точки, и что дебаггер готов к работе.
- Открылось окно дебага внизу: вкладка «5: Debug». В нём будет отображаться необходимая вам информация.
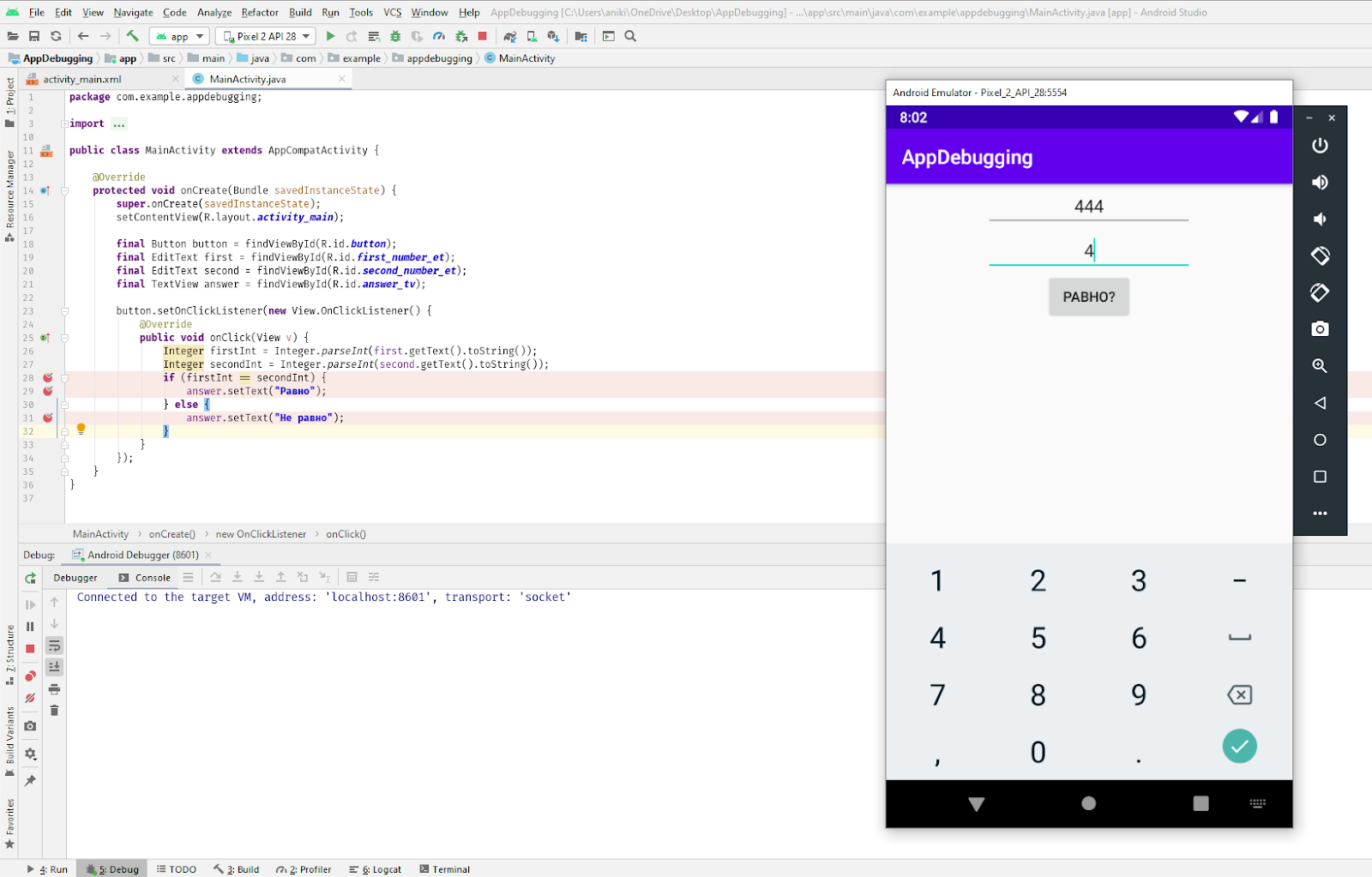
Введём неравные числа и нажмём кнопку «РАВНО?». Программа остановилась на первой точке:
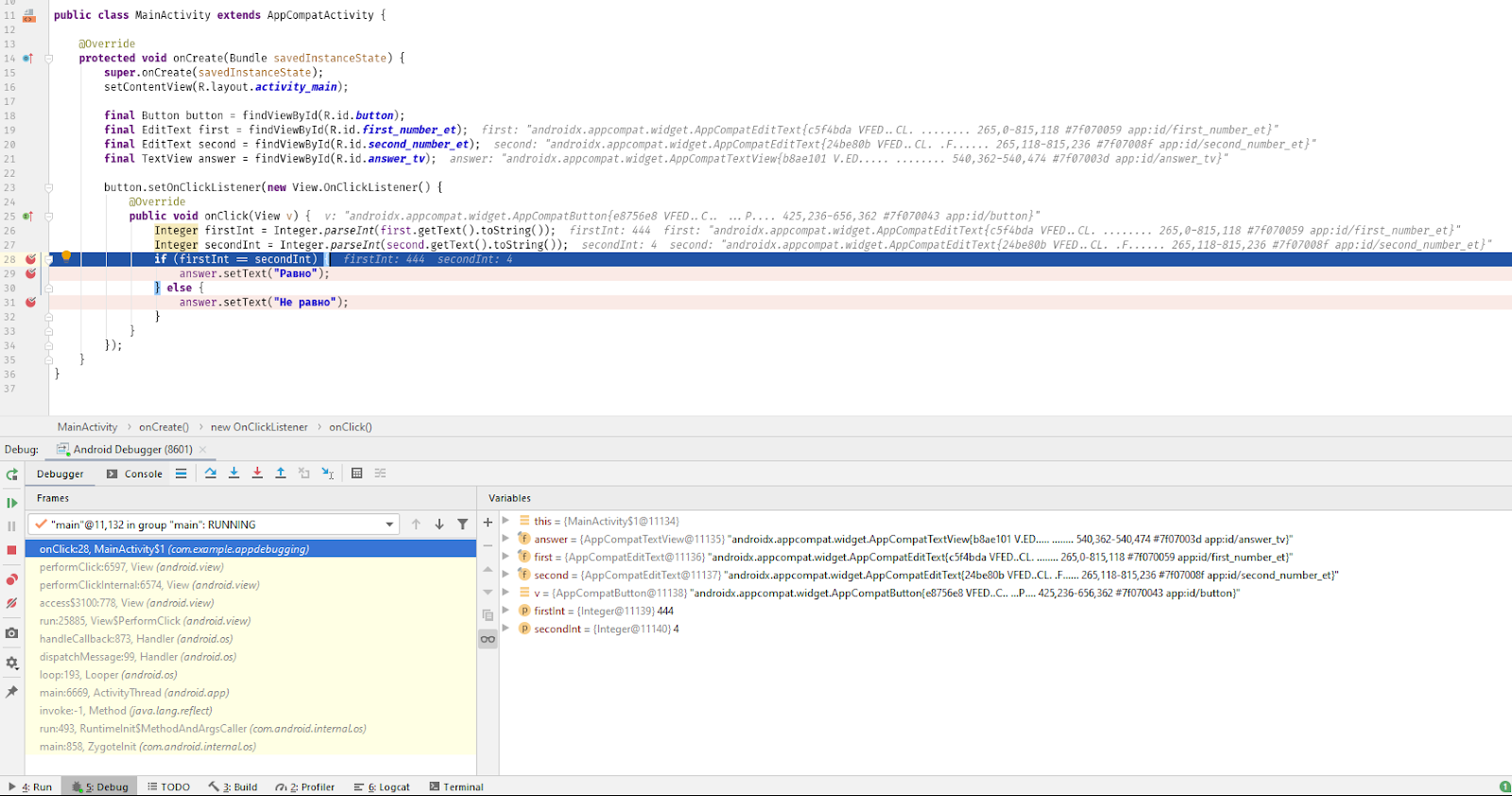
- Сразу подсвечивается синим строка, где программа остановлена: в окне кода на 28-й строке и в левом окне отладчика (там даже можно увидеть, какой метод вызван, — onClick).
- В правом, основном окне отладчика, всё гораздо интереснее. Здесь можно увидеть инстансы наших вью (answer, first, second), в конце которых серым текстом даже отображаются их id. Но интереснее всего посмотреть на firstInt и secondInt. Там записаны значения, которые мы сейчас будем сравнивать.
Как видим, значения именно такие, какие мы и ввели. Значит, проблема не в получении чисел из полей. Давайте двигаться дальше — нам нужно посмотреть, в правильную ли ветку мы заходим. Для этого можно нажать F8 (перейти на следующую строку выполнения кода). А если следующая точка останова далеко или в другом классе, можно нажать F9 — программа просто возобновит работу и остановится на следующей точке. В интерфейсе эти кнопки находятся здесь:
Остановить дебаггер, если он больше не нужен, можно через CTRL+F2 или кнопку «Стоп»:
В нашем случае неважно, какую кнопку нажимать (F9 или F8). Мы сразу переходим к следующей точке останова программы:
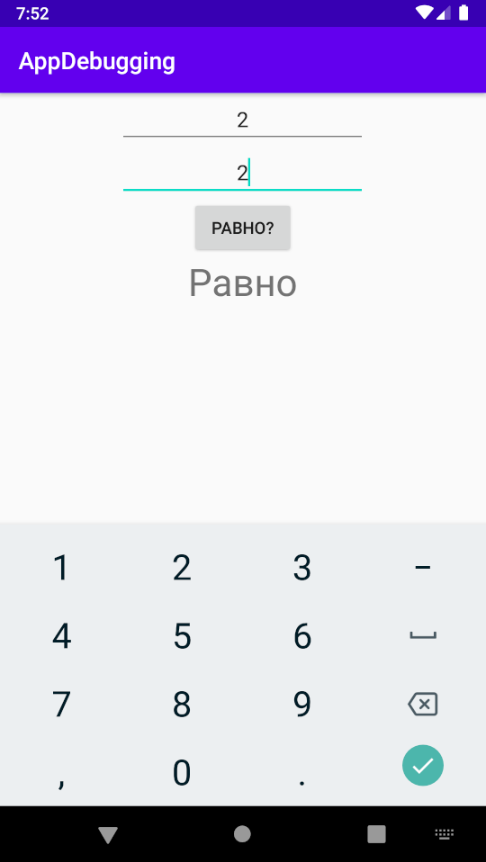
Ветка правильная, то есть логика программы верна, числа firstInt и secondInt не изменились. Зато мы сразу видим, что подпись некорректная! Вот в чём была ошибка. Исправим подпись и проверим программу ещё раз.
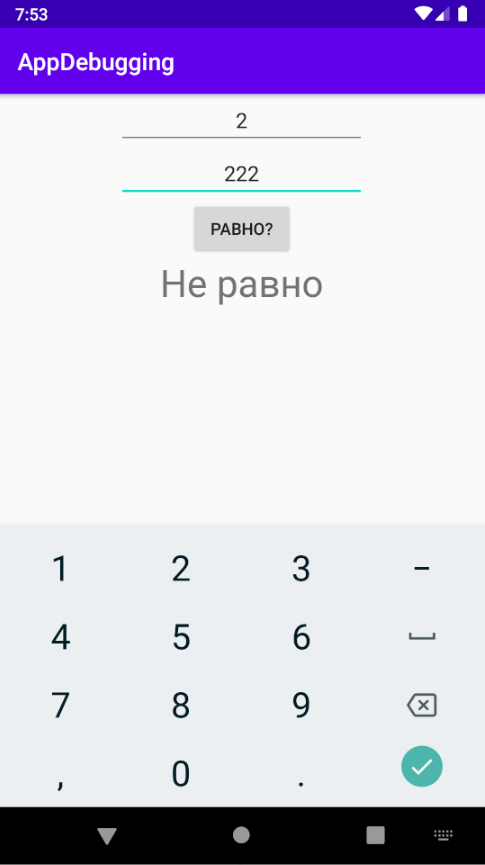
Мы уже починили два бага: падение приложения с помощью логов и некорректную логику (с помощью отладчика). Хеппи пас (happy path) пройден. То есть основная функциональность при корректных данных работает. Но нам надо проверить не только хеппи пас — пользователь может ввести что угодно. И программа может нормально работать в большинстве случаев, но вести себя странно в специфических состояниях. Давайте введём числа побольше и посмотрим, что будет:
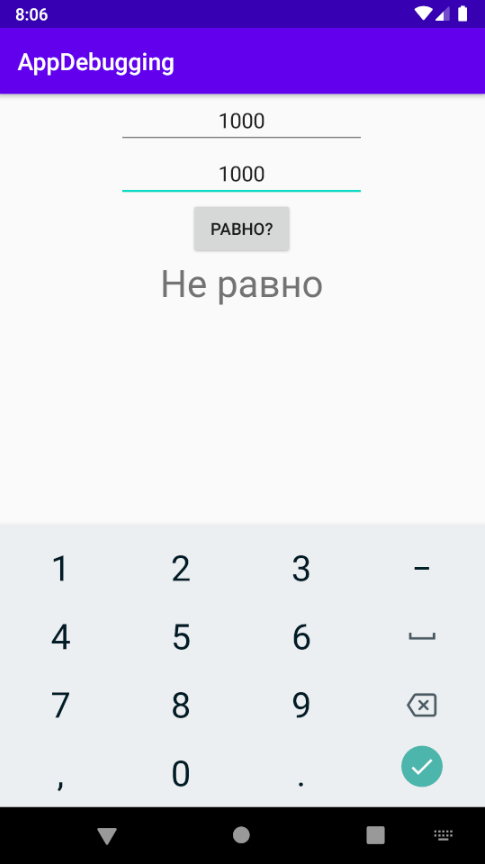
Не сработало — программа хочет сказать, что 1000 не равна 1000, но это абсурд. Запускаем приложение в режиме отладки. Точка останова уже есть. Смотрим в отладчик:
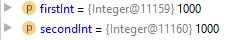
Числа одинаковые, что могло пойти не так? Обращаем внимание на тип переменной — Integer. Так вот в чём проблема! Это не примитивный тип данных, а ссылочный. Ссылочные типы нельзя сравнивать через ==, потому что будут сравниваться ссылки объектов, а не они сами. Но для Integer в Java есть нюанс: Integer может кешироваться до 127, и если мы вводим по единице в оба поля числа до 127, то фактически сравниваем просто int. А если вводим больше, то получаем два разных объекта. Адреса у объектов не совпадают, а именно так Java сравнивает их.
Есть два решения проблемы:
- Изменить тип Integer на примитив int.
- Сравнивать как объекты.
Не рекомендуется менять тип этих полей в реальном приложении: числа могут приходить извне, и тип лучше оставлять прежним. Изменим то, как мы сравниваем числа:
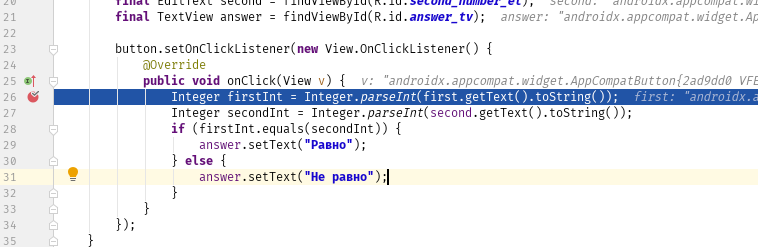
firstInt. secondInt
answer. answer.
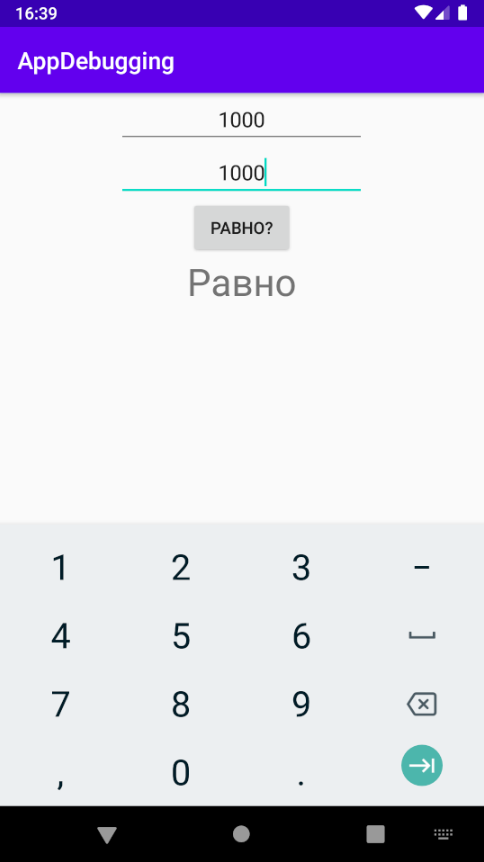
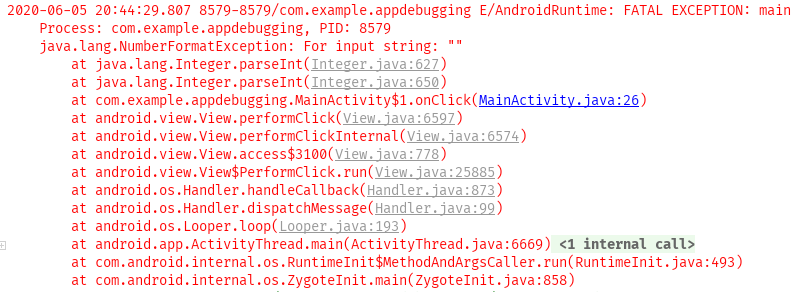
Опять NumberFormatException, при этом строка пустая. Давайте поставим точку останова на 26-й строке и заглянем с помощью отладчика глубже.
Нажмём F8 — и перейдём в глубины операционной системы:
Интересно! Давайте обернём код в try/catch и посмотрим ошибке в лицо. Если что, поправим приложение. Выделяем код внутри метода onClick() и нажимаем Ctrl+Alt+T:
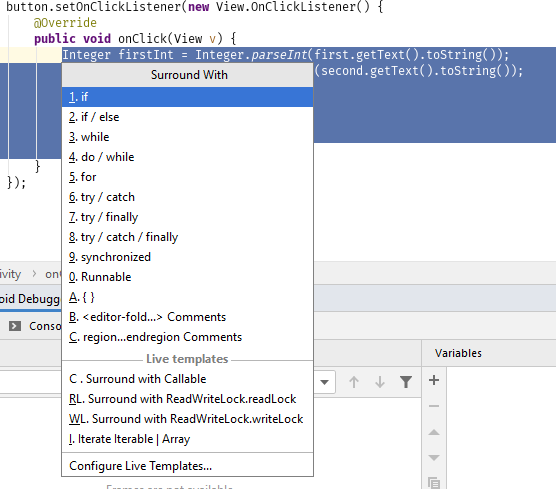
Выбираем try / catch, среда разработки сама допишет код. Поставим точку останова. Получим:
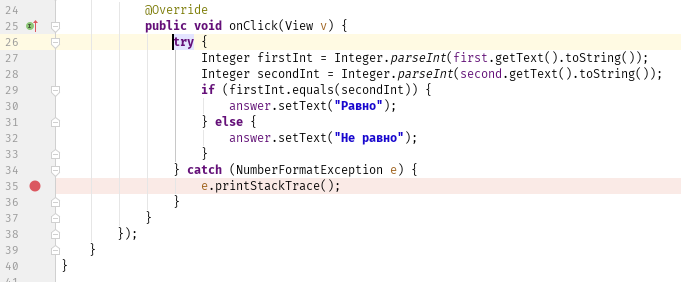
Запускаем приложение и ловим ошибку:
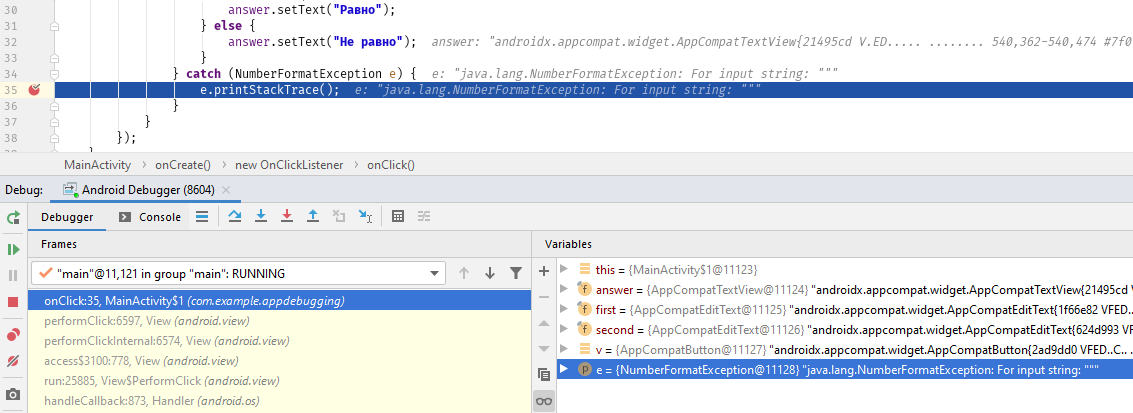
Действительно, как и в логах, — NumberFormatException. Метод parseInt выбрасывает исключение, если в него передать пустую строку. Как обрабатывать такую проблему — решать исключительно вам. Два самых простых способа:
- Проверять получаемые строки first.getText().toString() и second.getText().toString() на пустые значения. И если хоть одно значение пустое — говорить об этом пользователю и не вызывать метод parseInt.
- Или использовать уже готовую конструкцию try / catch:
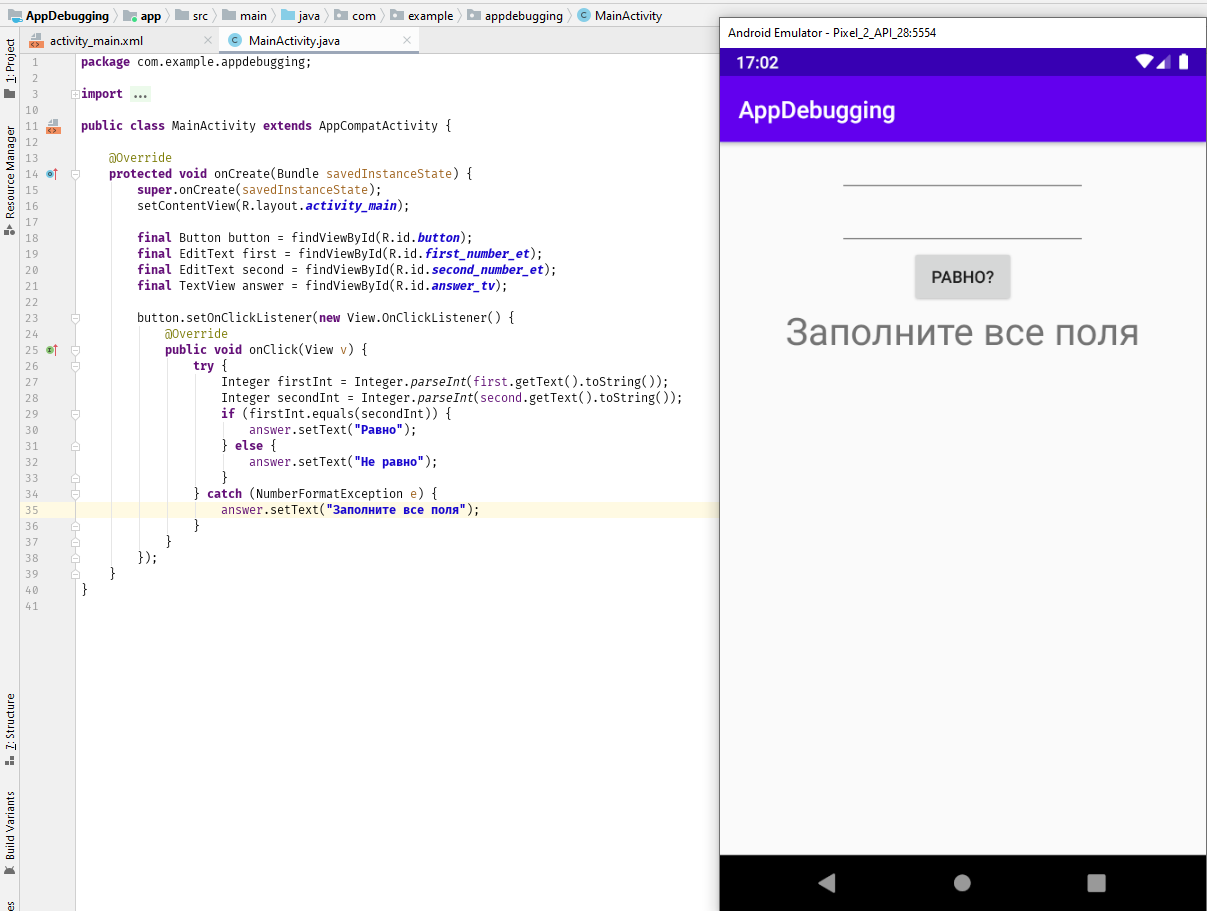
Теперь-то точно всё в порядке! Хотя профессиональным тестировщикам это приложение никто не отдавал: поищете ещё ошибки? 🙂
Несколькими тысячами строк кода позже, тот же самый проект может оказаться отягощенным ошибками, из-за которых добавление новых функций становится головной болью, и падает энтузиазм программистов. Лучшие разработчики знают, как найти и устранить ошибки, и придерживаются лучших практик в разработке программного обеспечения, чтобы свести к минимуму, в первую очередь, возникновение ошибок.
Ни один программист никогда не напишет абсолютно верный код, но с некоторой практикой и решимостью вполне возможно писать чистый код, сдерживать ошибки и разрабатывать надежные программные системы.

Инструмент номер один для отладки кода – это опробованный и верный способ вставки операторов печати. В качестве равнозначной замены, для случаев, когда операторов печати много, и ими трудно управлять, может быть использована система протоколирования вместо операторов печати. Во многих языках программирования для этого есть в свободном доступе специальные библиотеки, как, например, библиотека logging, встроенная в Python.
Операторы печати – это самый быстрый, простой и непосредственный для программиста способ инспектирования значений данных и типов переменных. Правильно размещенные операторы печати позволяют программисту отслеживать поток данных на участке кода и быстро определять источник ошибки.
Не имеет значения, сколько передовых технологий используется, скромный оператор печати должен быть первым инструментом, к которому обращается программист, когда пытается отладить участок кода.
Отладчики исходного кода доводят метод отладки с помощью операторов печати до его логического завершения. Они позволяют программисту отследить по шагам выполнение кода строка за строкой и инспектировать все, что угодно, начиная от значений переменных и заканчивая состоянием виртуальной машины.
Большинство языков программирования имеют множество доступных отладчиков, которые предлагают различные возможности, включая графические интерфейсы, настройки точек останова для приостановки выполнения программы, и выполнение произвольного кода внутри среды исполнения.
Применение отладчика может быть излишним во многих ситуациях, но при надлежащем использовании, отладчик может стать мощным и эффективным инструментом. Для лучшего понимания возможностей отладчика, познакомьтесь с отладчиком Python pdb.
Использование какой-либо системы отслеживания ошибок является жизненно важным условием для нетривиальных проектов по созданию программного обеспечения. Типичная ситуация, которая складывается, когда не используют систему отслеживания ошибок, такова: программисты вынуждены разбираться в старых е-мейлах или переписке в чате в поисках информации об ошибках, или того хуже — единственным хранилищем информации об ошибках является память программиста.
Когда такое случается, некоторые ошибки неизбежно остаются неисправленными, и что более важно, их труднее обнаружить и устранить другие, связанные с ними ошибки.
Простой текстовый файл может служить начальной системой отслеживания ошибок для проекта. С ростом объема кода количество ошибок выйдет за рамки текстового файла.
Существует большой выбор систем отслеживания ошибок в программном обеспечении, как коммерческих, так и с открытым исходным кодом. Самым важным критерием в выборе такой системы является доступность для сотрудников-непрограммистов, которым нужно работать с файлом ошибок.
В некоторых языках программирования верификатор может проводить статический анализ кода для обнаружения проблемных мест до того, как код будет откомпилирован или выполнен, а в других языках верификатор полезен для проверки синтаксиса и стиля написания.
Исполнение программы верификации внутри редактора во время написания кода или прогон кода через верификатор до компиляции и выполнения помогает программистам находить и исправлять неисправности до того, как они переросли в ошибки в исполняемом программном обеспечении.
Использование верификации позволяет значительно сэкономить время по отслеживанию источника неисправности, вызванных синтаксическими ошибками, опечатками, и некорректными типами данных. Чтобы получить более полное представление о возможностях верификатора, посмотрите Pyflakes, верификатор для Python.
Также как и использование системы отслеживания ошибок, применение системы контроля версии – это самая лучшая практика в разработке программного обеспечения, которая не может быть игнорирована при разработке любого проекта значительного размера.
Системы контроля версии, такие как Git, Mercurial и SVN, позволяют разным версиям базы кода быть разделенными, основываясь на том, над чем работают или кто разрабатывает код. Разные версии могут быть объединены вместе, поэтому несколько программистов могут работать с базой кода в одно то же время, не создавая ошибки, которые могли бы повлиять на ход работы остальных разработчиков.
Системы контроля версий играют ключевую роль еще и потому, что позволяют программистам откатить изменения до более ранней версии кода, просто возвратившись в состояние базы до появления ошибок, не допуская при этом других ошибок, за исправление которых пришлось бы дорого поплатиться.
Плохо спроектированный код – это главный источник трудно исправляемых ошибок. Если код легко понять, и он может быть «выполнен» в уме или на бумаге, есть большая вероятность, что программисты смогут быстро находить и исправлять ошибки.
Самый лучший способ добиться этого – писать функции, выполняющие что-то одно. А вот участок кода с большим количеством функций имеет большую склонность к возникновению ошибок, которые сложно отслеживать.
Проектирование компонентов программного обеспечения, которые осуществляет только одну функцию, часто называется модульным дизайном. Модульность помогает программистам рассматривать системы программного обеспечения в двух измерениях. Во-первых, модульность создает уровень абстракции, позволяющий думать о модуле системы без понимания всех деталей его работы.
Например, программист, разрабатывающий систему электронной коммерции, мог бы, рассматривая модуль обработки кредитной карты, видеть, как он связан с остальным кодом, не вдаваясь в детали самой обработки кредитной карты. С другой стороны, детали модуля (в нашем примере того, который занимается обработкой кредитной карты) могут быть рассмотрены и поняты без обращения к не имеющему отношение к этому модулю коду.
Модульные тесты и другие типы автоматизированных тестов идут рука об руку с модульным программированием.
Автоматизированный код – это участок кода, который выполняет программу с определенными входными параметрами и проверяет, соответствует ли поведение программы ожидаемому.
Модульные тесты проверяют функционирование отдельных функций или методов класса, в то время как функциональные тесты проверяют специфичное поведение всей программы, а интеграционные тесты проверяют большие части системы или всю систему в целом.
Существует много фреймворков для тестирования, которые делают написание тестов легче. Многие из известных фреймворков, используемых сегодня, были получены из библиотеки JUnit, написанной Кентом Бентом (Kent Bent), одним из первых сторонников идеи разработки через тестирование. Стандартная библиотека Python включает свою версию JUnit под именем PyUni или просто unittest.
Если верить легендам программирования Брайану Кернигану и Робу Пайку (Brain Kernighan и Rob Pike), отладка по типу «Резиновая уточка» возникла в университетском компьютерном центре, где студенты должны были садиться напротив плюшевого мишки и объяснять ему их ошибки, прежде чем обращаться за помощью к живому человеку.
Этот метод отладки оказался настолько эффективным, что быстро распространился во всем мире разработки программного обеспечения, и также как простой оператор печати, продолжает существовать по сей день, несмотря на то, что есть, казалось бы, более сложные инструменты. Практически все может заменить плюшевого мишку: резиновые уточки, как терпеливые слушатели, тоже пользуются спросом.
Важной частью этого метода является то, что нужно объяснять код и проблему вслух в простых и понятных терминах. Есть подобная методика, которая также полезна – вести журнал программирования, в который нужно записывать мысли о коде до и после его реализации.
Написание документации демонстрирует понимание программной системы, и часто указывает на те части системы, которые не до конца понятны и являются вероятным источником ошибок.
Программирование – это, прежде всего, искусство. И также как для любого другого вида искусства, путь к мастерству в нем вымощен трудолюбием и стремлением учиться. Работа по изучению программирования никогда не заканчивается. Всегда есть что-то новое для изучения и новые способы по улучшению.
Какими из этих 10 средств отладки вы пользуетесь сейчас? Какими вы могли бы начать пользоваться с сегодняшнего дня? Какие из этих инструментов требуют времени на практику и освоения новых навыков?
Программисты пользуются преимуществом, которым только некоторые другие мастера могут когда-либо воспользоваться: самые лучшие инструменты и знания о программировании свободно и бесплатно доступны для всех, кто заинтересован в этом вопросе. Вы можете стать профи в отладке кода: все, что вы должны сделать для этого – просто взять инструменты по отладке и приступить к работе.