
Cacti
Сначала был MRTG (Multi Router Traffic Grapher) — программа для организации сервиса мониторинга сети и измерения данных с течением времени. Еще в 1990-х, его автор Тобиас Отикер (Tobias Oetiker) счел нужным написать простой инструмент для построения графиков, использующий кольцевую базу данных, изначально используемый для отображения пропускной способности маршрутизатора в локальной сети. Так MRTG породил RRDTool, набор утилит для работы с RRD (Round-robin Database, кольцевой базой данных), позволяющий хранить, обрабатывать и графически отображать динамическую информацию, такую как сетевой трафик, загрузка процессора, температура и так далее. Сейчас RRDTool используется в огромном количестве инструментов с открытым исходным кодом. Cacti — это современный флагман среди программного обеспечения с открытым исходным кодом в области графического представления сети, и он выводит принципы MRTG на принципиально новый уровень.
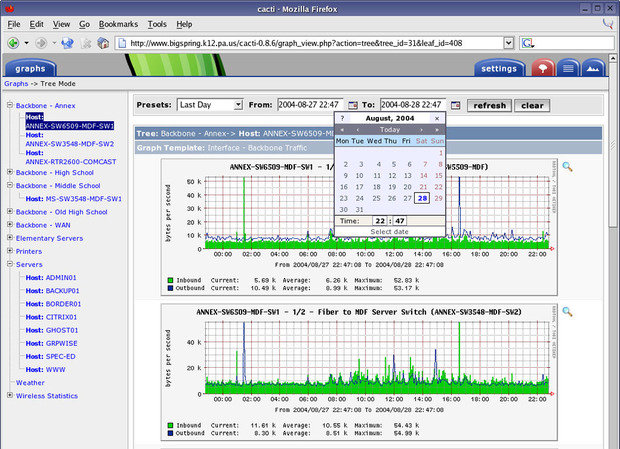
От использования диска до скорости вентилятора в источнике питания, если показатель можно отслеживать, Cacti сможет отобразить его и сделать эти данные легкодоступными.
Cacti — это бесплатная программа, входящее в LAMP-набор серверного программного обеспечения, которое предоставляет стандартизированную программную платформу для построения графиков на основе практически любых статистических данных. Если какое-либо устройство или сервис возвращает числовые данные, то они, скорее всего, могут быть интегрированы в Cacti. Существуют шаблоны для мониторинга широкого спектра оборудования — от Linux- и Windows-серверов до маршрутизаторов и коммутаторов Cisco, — в основном все, что общается на SNMP (Simple Network Management Protocol, простой протокол сетевого управления). Существуют также коллекции шаблонов от сторонних разработчиков, которые еще больше расширяют и без того огромный список совместимых с Cacti аппаратных средств и программного обеспечения.
Несмотря на то, что стандартным методом сбора данных Cacti является протокол SNMP, также для этого могут быть использованы сценарии на Perl или PHP. Фреймворк программной системы умело разделяет на дискретные экземпляры сбор данных и их графическое отображение, что позволяет с легкостью повторно обрабатывать и реорганизовывать существующие данные для различных визуальных представлений. Кроме того, вы можете выбрать определенные временные рамки и отдельные части графиков просто кликнув на них и перетащив.
Так, например, вы можете быстро просмотреть данные за несколько прошлых лет, чтобы понять, является ли текущее поведение сетевого оборудования или сервера аномальным, или подобные показатели появляются регулярно. А используя Network Weathermap, PHP-плагин для Cacti, вы без чрезмерных усилий сможете создавать карты вашей сети в реальном времени, показывающие загруженность каналов связи между сетевыми устройствами, реализуемые с помощью графиков, которые появляются при наведении указателя мыши на изображение сетевого канала. Многие организации, использующие Cacti, выводят эти карты в круглосуточном режиме на 42-дюймовые ЖК-мониторы, установленные на стене, позволяя ИТ-специалистам мгновенно отслеживать информацию о загруженности сети и состоянии канала.
Таким образом, Cacti — это инструментарий с обширными возможностями для графического отображения и анализа тенденций производительности сети, который можно использовать для мониторинга практически любой контролируемой метрики, представляемой в виде графика. Данное решение также поддерживает практически безграничные возможности для настройки, что может сделать его чересчур сложным при определенных применениях.
Nagios
Nagios — это состоявшаяся программная система для мониторинга сети, которая уже многие годы находится в активной разработке. Написанная на языке C, она позволяет делать почти все, что может понадобится системным и сетевым администраторам от пакета прикладных программ для мониторинга. Веб-интерфейс этой программы является быстрым и интуитивно понятным, в то время его серверная часть — чрезвычайно надежной.
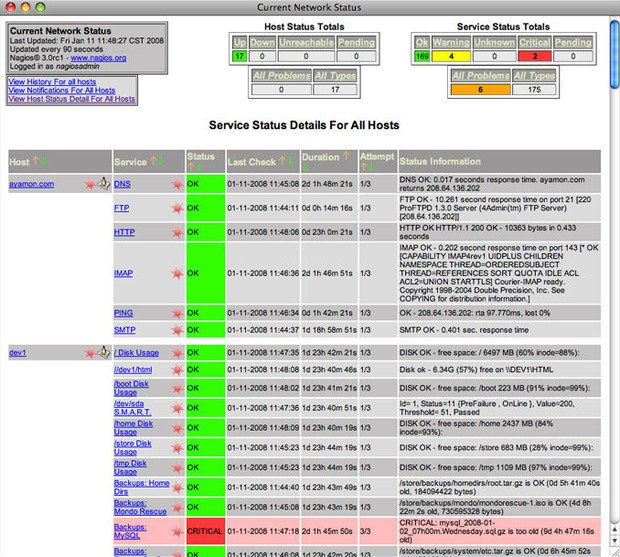
Nagios может стать проблемой для новичков, но довольно сложная конфигурация также является преимуществом этого инструмента, так как он может быть адаптирован практически к любой задаче мониторинга.
Как и Cacti, очень активное сообщество поддерживает Nagios, поэтому различные плагины существуют для огромного количества аппаратных средств и программного обеспечения. От простейших ping-проверок до интеграции со сложными программными решениями, такими как, например, написанным на Perl бесплатным программным инструментарием WebInject для тестирования веб-приложений и веб сервисов. Nagios позволяет осуществлять постоянный мониторинг состояния серверов, сервисов, сетевых каналов и всего остального, что понимает протокол сетевого уровня IP. К примеру, вы можете контролировать использование дискового пространства на сервере, загруженность ОЗУ и ЦП, использования лицензии FLEXlm, температуру воздуха на выходе сервера, задержки в WAN и Интеренет-канале и многое другое.
Очевидно, что любая система мониторинга серверов и сети не будет полноценной без уведомлений. У Nagios с этим все в порядке: программная платформа предлагает настраиваемый механизм уведомлений по электронной почте, через СМС и мгновенные сообщения большинства популярных Интернет-мессенджеров, а также схему эскалации, которая может быть использована для принятия разумных решений о том, кто, как и при каких обстоятельствах должен быть уведомлен, что при правильной настройке поможет вам обеспечить многие часы спокойного сна. А веб-интерфейс может быть использован для временной приостановки получения уведомлений или подтверждения случившейся проблемы, а также внесения заметок администраторами.
Кроме того, функция отображения демонстрирует все контролируемые устройства в логическом представлении их размещения в сети, с цветовым кодированием, что позволяет показать проблемы по мере их возникновения.
Недостатком Nagios является конфигурация, так как ее лучше всего выполнять через командную строку, что значительно усложняет обучение новичков. Хотя люди, знакомые со стандартными файлами конфигурации Linux/Unix, особых проблем испытать не должны.
Возможности Nagios огромны, но усилия по использованию некоторых из них не всегда могут стоить затраченных на это усилий. Но не позволяйте сложностям запугать вас: преимущества системы раннего предупреждения, предоставляемые этим инструментом для столь многих аспектов сети, сложно переоценить.
Icinga
Icinga начиналась как ответвление от системы мониторинга Nagios, но недавно была переписана в самостоятельное решение, известное как Icinga 2. На данный момент обе версии программы находятся в активной разработке и доступны к использованию, при этом Icinga 1. x совместима с большим количеством плагинами и конфигурацией Nagios. Icinga 2 разрабатывалась менее громоздкой, с ориентацией на производительность, и более удобной в использовании. Она предлагает модульную архитектуру и многопоточный дизайн, которых нет ни в Nagios, ни в Icinga 1.
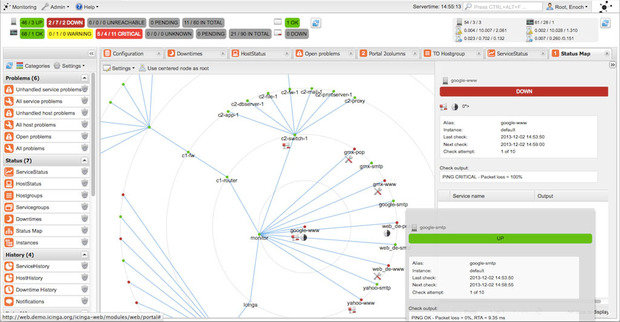
Icinga предлагает полноценную программную платформу для мониторинга и системы оповещения, которая разработана такой же открытой и расширяемой, как и Nagios, но с некоторыми отличиями в веб-интерфейсе.
Как и Nagios, Icinga может быть использована для мониторинга всего, что говорит на языке IP, настолько глубоко, насколько вы можете использовать SNMP, а также настраиваемые плагины и дополнения.
Существует несколько вариаций веб-интерфейса для Icinga, но главным отличием этого программного решения для мониторинга от Nagios является конфигурация, которая может быть выполнена через веб-интерфейс, а не через файлы конфигурации. Для тех, кто предпочитает управлять своей конфигурацией вне командной строки, эта функциональность станет настоящим подарком.
Icinga интегрируется со множеством программных пакетов для мониторинга и графического отображения, таких как PNP4Nagios, inGraph и Graphite, обеспечивая надежную визуализацию вашей сети. Кроме того, Icinga имеет расширенные возможности отчетности.
NeDi
Если вам когда-либо приходилось для поиска устройств в вашей сети подключаться через протокол Telnet к коммутаторам и выполнять поиск по MAC-адресу, или вы просто хотите, чтобы у вас была возможность определить физическое местоположение определенного оборудования (или, что, возможно, еще более важно, где оно было расположено ранее), тогда вам будет интересно взглянуть на NeDi.
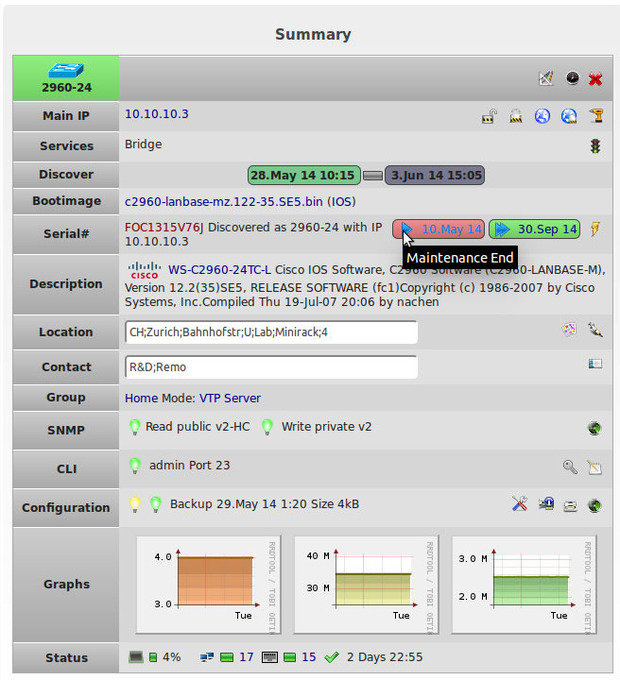
NeDi постоянно просматривает сетевую инфраструктуру и каталогизирует устройства, отслеживая все, что обнаружит.
NeDi — это бесплатное программное обеспечение, относящее к LAMP, которое регулярно просматривает MAC-адреса и таблицы ARP в коммутаторах вашей сети, каталогизируя каждое обнаруженное устройство в локальной базе данных. Данный проект не является столь хорошо известным, как некоторые другие, но он может стать очень удобным инструментом при работе с корпоративными сетями, где устройства постоянно меняются и перемещаются.
Обнаружение запускается процессом cron с заданными интервалами. Конфигурация простая, с единственным конфигурационным файлом, который позволяет значительно повысить количество настроек, в том числе возможность пропускать устройства на основе регулярных выражений или заданных границ сети. NeDi, обычно, использует протоколы Cisco Discovery Protocol или Link Layer Discovery Protocol для обнаружения новых коммутаторов и маршрутизаторов, а затем подключается к ним для сбора их информации. Как только начальная конфигурация будет установлена, обнаружение устройств будет происходить довольно быстро.
До определенного уровня NeDi может интегрироваться с Cacti, поэтому существует возможность связать обнаружение устройств с соответствующими графиками Cacti.
Ntop
Проект Ntop — сейчас для «нового поколения» более известный как Ntopng — прошел долгий путь развития за последнее десятилетие. Но назовите его как хотите — Ntop или Ntopng, — в результате вы получите первоклассный инструмент для мониторинга сетевого траффика в паре с быстрым и простым веб-интерфейсом. Он написан на C и полностью самодостаточный. Вы запускаете один процесс, настроенный на определенный сетевой интерфейс, и это все, что ему нужно.
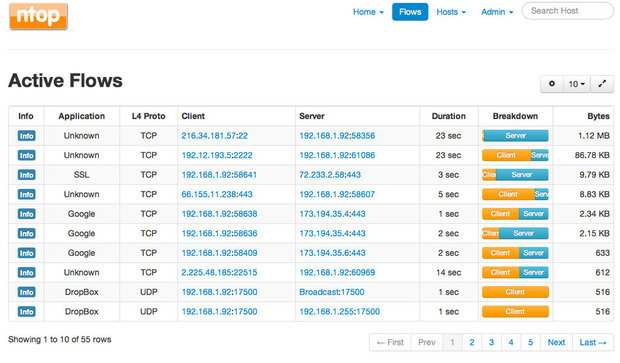
Ntop — это инструмент для анализа пакетов с легким веб-интерфейсом, который показывает данные в реальном времени о сетевом трафике. Информация о потоке данных через хост и о соединении с хостом также доступны в режиме реального времени.
Ntop предоставляет легко усваиваемые графики и таблицы, показывающие текущий и прошлый сетевой трафик, включая протокол, источник, назначение и историю конкретных транзакций, а также хосты с обоих концов. Кроме того, вы найдете впечатляющий набор графиков, диаграмм и карт использования сети в реальном времени, а также модульную архитектуру для огромного количества надстроек, таких как добавление мониторов NetFlow и sFlow. Здесь вы даже сможете обнаружить Nbox — аппаратный монитор, который встраивает в Ntop.
Кроме того, Ntop включает API-интерфейс для скриптового языка программирования Lua, который может быть использован для поддержки расширений. Ntop также может хранить данные хоста в файлах RRD для осуществления постоянного сбора данных.
Одним из самых полезных применений Ntopng является контроль трафика в конкретном месте. К примеру, когда на вашей карте сети часть сетевых каналов подсвечены красным, но вы не знаете почему, вы можете с помощью Ntopng получить поминутный отчет о проблемном сегменте сети и сразу узнать, какие хосты ответственны за проблему.
Пользу от такой видимости сети сложно переоценить, а получить ее очень легко. По сути, вы можете запустить Ntopng на любом интерфейсе, который был настроен на уровне коммутатора, для мониторинга другого порта или VLAN. Вот и все.
Zabbix
Zabbix — это полномасштабный инструмент для сетевого и системного мониторинга сети, который объединяет несколько функций в одной веб-консоли. Он может быть сконфигурирован для мониторинга и сбора данных с самых разных серверов и сетевых устройств, обеспечивая обслуживание и мониторинг производительности каждого объекта.
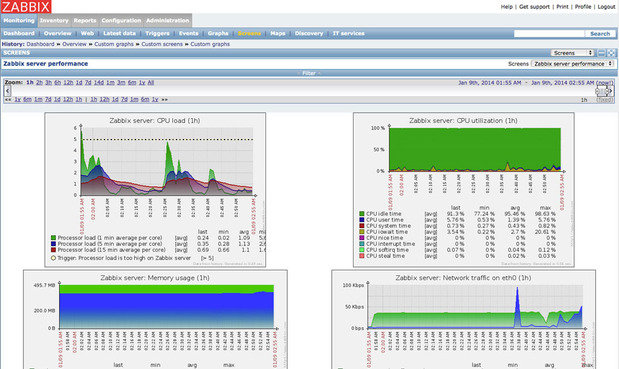
Zabbix позволяет производить мониторинг серверов и сетей с помощью широкого набора инструментов, включая мониторинг гипервизоров виртуализации и стеков веб-приложений.
В основном, Zabbix работает с программными агентами, запущенными на контролируемых системах. Но это решение также может работать и без агентов, используя протокол SNMP или другие возможности для осуществления мониторинга. Zabbix поддерживает VMware и другие гипервизоры виртуализации, предоставляя подробные данные о производительности гипервизора и его активности. Особое внимание также уделяется мониторингу серверов приложений Java, веб-сервисов и баз данных.
Zabbix позволяет настраивать панели мониторинга и веб-интерфейс, чтобы сфокусировать внимание на наиболее важных компонентах сети. Уведомления и эскалации проблем могут основываться на настраиваемых действиях, которые применяются к хостам или группам хостов. Действия могут даже настраиваться для запуска удаленных команд, поэтому некий ваш сценарий может запускаться на контролируемом хосте, если наблюдаются определенные критерии событий.
Программа отображает в виде графиков данные о производительности, такие как пропускная способность сети и загрузка процессора, а также собирает их для настраиваемых систем отображения. Кроме того, Zabbix поддерживает настраиваемые карты, экраны и даже слайд-шоу, отображающие текущий статус контролируемых устройств.
Zabbix может быть сложным для реализации на начальном этапе, но разумное использование автоматического обнаружения и различных шаблонов может частично облегчить трудности с интеграцией. В дополнение к устанавливаемому пакету, Zabbix доступен как виртуальное устройство для нескольких популярных гипервизоров.
Observium
Observium — это программа для мониторинга сетевого оборудования и серверов, которое имеет огромный список поддерживаемых устройств, использующих протокол SNMP. Как программное обеспечение, относящееся к LAMP, Observium относительно легко устанавливается и настраивается, требуя обычных установок Apache, PHP и MySQL, создания базы данных, конфигурации Apache и тому подобного. Он устанавливается как собственный сервер с выделенным URL-адресом.
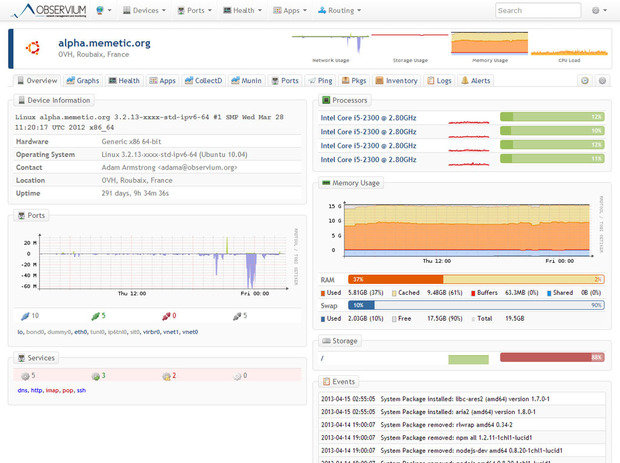
Observium сочетает в себе мониторинг систем и сетей с анализом тенденций производительности. Он может быть настроен для отслеживания практически любых показателей.
Все эта собранная информация доступна через легкий в использовании пользовательский интерфейс, который предоставляет продвинутые возможности для статистического отображения данных, а также в виде диаграмм и графиков. Вы можете получить что угодно: от времени отклика ping и SNMP до графиков пропускной способности, фрагментации, количества IP-пакетов и т. В зависимости от устройства, эти данные могут быть доступны вплоть для каждого обнаруженного порта.
Что касается серверов, то для них Observium может отобразить информацию о состоянии центрального процессора, оперативной памяти, хранилища данных, свопа, температуры и т. из журнала событий. Вы также можете включить сбор данных и графическое отображение производительности для различных сервисов, включая Apache, MySQL, BIND, Memcached, Postfix и другие.
Observium отлично работает как виртуальная машина, поэтому может быстро стать основным инструментом для получения информации о состоянии серверов и сетей. Это отличный способ добавить автоматическое обнаружение и графическое представление в сеть любого размера.
Мониторинг сети своими руками
Слишком часто ИТ-администраторы считают, что они ограничены в своих возможностях. Независимо от того, имеем ли мы дело с пользовательским программным приложением или «неподдерживаемой» частью аппаратного обеспечения, многие из нас считают, что если система мониторинга не сможет сразу же справиться с ним, то получить в этой ситуации необходимые данные невозможно. Это, конечно же, не так. Приложив немного усилий, вы сможете почти все сделать более видимым, учтенным и контролируемым.

В качестве примера можно привести пользовательское приложение с базой данных на серверной части, например, интернет-магазин. Ваш менеджмент хочет увидеть красивые графики и диаграммы, оформленные то в одном виде, то в другом. Если вы уже используете, скажем, Cacti, у вас есть несколько возможностей вывести собранные данные в требуемом формате. Вы можете, к примеру, написать простой скрипт на Perl или PHP для запуска запросов в базе данных и передачи этих расчетов в Cacti либо же использовать SNMP-вызов к серверу базы данных, используя частный MIB (Management Information Base, база управляющей информации). Так или иначе, но задача может быть выполнена, и выполнена легко, если у вас есть необходимый для этого инструментарий.
Получить доступ к большинству из приведенных в данной статье бесплатных утилит для мониторинга сетевого оборудования не должно быть сложно. У них есть пакетные версии, доступные для загрузки для наиболее популярных дистрибутивов Linux, если только они изначально в него не входят. В некоторых случаях они могут быть предварительно сконфигурированы как виртуальный сервер. В зависимости от размера вашей инфраструктуры, конфигурирование и настройка этих инструментов может занять довольно много времени, но как только они заработают, они станут надежной опорой для вас. В крайнем случае, стоит хотя бы протестировать их.
Независимо от того, какую из этих вышеперечисленных систем вы используете, чтобы следить за своей инфраструктурой и оборудованием, она предоставит вам как минимум функциональные возможности еще одного системного администратора. Она хоть не может ничего исправить, но будет следить буквально за всем в вашей сети круглые сутки и семь дней в неделю. Предварительно потраченное время на установку и настройку окупятся с лихвой. Кроме того, обязательно запустите небольшой набор автономных средств мониторинга на другом сервере, чтобы наблюдать за основным средством мониторинга. Это то случай, когда всегда лучше следить за наблюдателем.
Появились вопросы или нужна консультация? Обращайтесь!

Вечный параноик, Антон Кочуков.
SolarWinds Network Bandwidth Analyzer
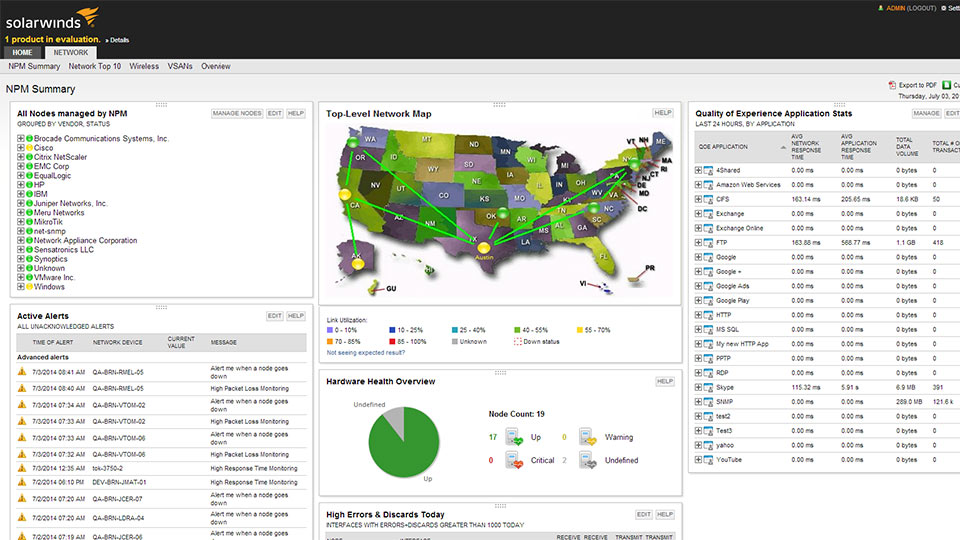
Данное решение позиционируется производителем как программный пакет из двух продуктов — Network Performance Monitor (базовое решение) и NetFlow Traffic Analyzer (модульное расширение). Как заявляется, они имеют схожие, но все же отличающиеся функциональные возможности для анализа сетевого трафика, дополняющие друг друга при совместном использовании сразу двух продуктов.
Network Performance Monitor, как следует из названия, осуществляет мониторинг производительности сети и станет для вас заманчивым выбором, если вы хотите получить общее представление о том, что происходит в вашей сети. Покупая это решение, вы платите за возможность контролировать общую работоспособность вашей сети: опираясь на огромное количество статистических данных, таких как скорость и надежность передачи данных и пакетов, в большинстве случаев вы сможете быстро идентифицировать неисправности в работе вашей сети. А продвинутые интеллектуальные возможности программы по выявлению потенциальных проблем и широкие возможности по визуальному представлению результатов в виде таблиц и графиков с четкими предупреждениями о возможных проблемах, еще больше облегчат эту работу.
Модульное расширение NetFlow Traffic Analyzer больше сконцентрировано на анализе самого трафика. В то время, как функциональность базового программного решения Network Performance Monitor больше предназначена для получения общего представления о производительности сети, в NetFlow Traffic Analyzer фокус внимания направлен на более детальный анализ процессов, происходящих в сети. В частности, эта часть программного пакета позволит проанализировать перегрузки или аномальные скачки полосы пропускания и предоставит статистику, отсортированную по пользователям, протоколам или приложениям. Обратите внимание, что данная программа доступна только для среды Windows.
Wireshark
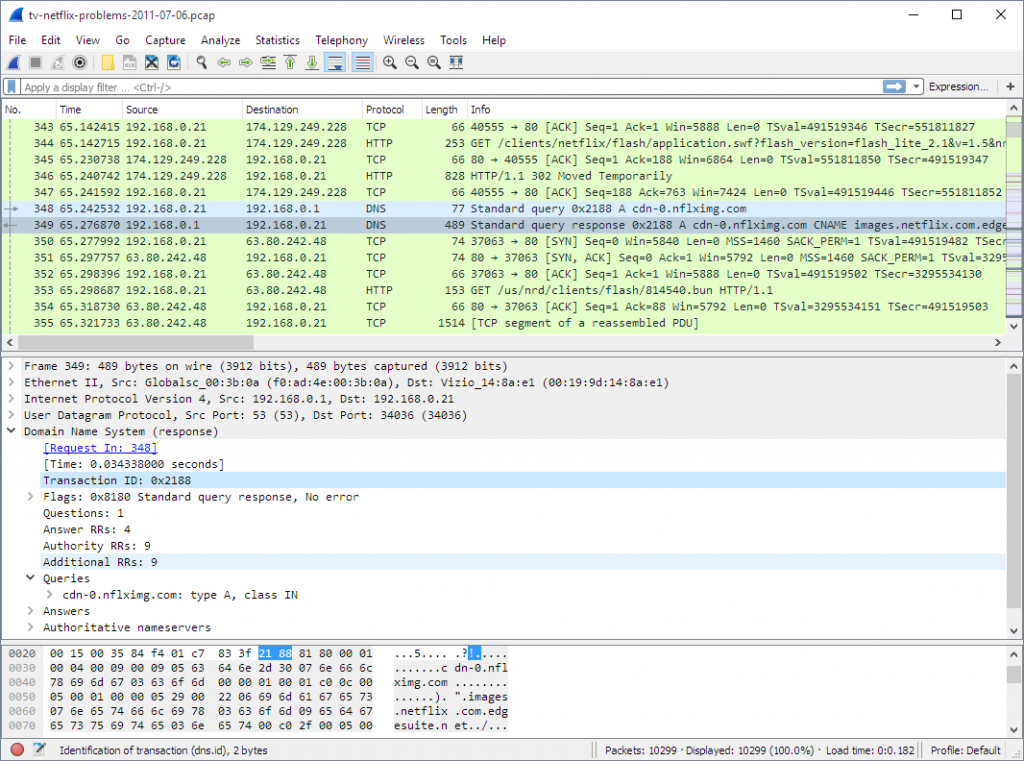
WireShark является относительно новым инструментом в большой семье решений для сетевой диагностики, но за это время он уже успел завоевать себе признание и уважение со стороны ИТ-профессионалов. С анализом трафика WireShark справляется превосходно, прекрасно выполняя для вас свою работу. Разработчики смогли найти золотую середину между исходными данными и визуальным представлением этих данных, поэтому в WireShark вы не найдете перекосов в ту или иную сторону, которым грешат большинство других решений для анализа сетевого трафика. WireShark прост, совместим и портативен. Используя WireShark, вы получаете именно то, что ожидаете, и получаете это быстро.
WireShark имеет прекрасный пользовательский интерфейс, множество опций для фильтрации и сортировки, и, что многие из нас смогут оценить по достоинству, анализ трафика WireShark прекрасно работает с любым из трех самых популярных семейств операционных систем — *NIX, Windows и macOS. Добавьте ко всему вышеперечисленному тот факт, что WireShark — программный продукт с открытым исходным кодом и распространяется бесплатно, и вы получите прекрасный инструмент для проведения быстрой диагностики вашей сети.
Tcpdump
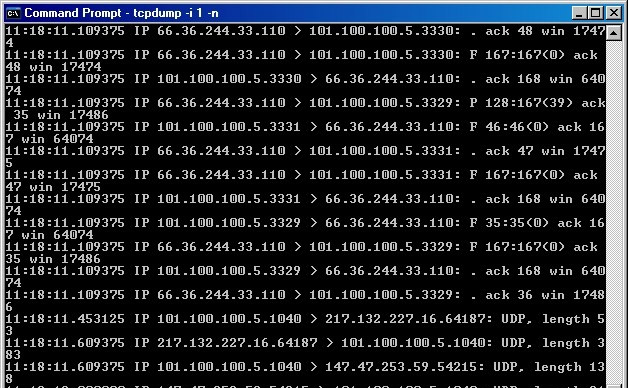
Анализатор трафика tcpdump выглядит как некий древний инструмент, и, если уж быть до конца откровенными, с точки зрения функциональности работает он также. Несмотря на то, что со своей работой он справляется и справляется хорошо, причем используя для этого минимум системных ресурсов, насколько это вообще возможно, многим современным специалистам будет сложно разобраться в огромном количестве «сухих» таблиц с данными. Но бывают в жизни ситуации, когда использование столь обрезанных и неприхотливых к ресурсам решений может быть полезно. В некоторых средах или на еле работающих ПК минимализм может оказаться единственным приемлемым вариантом.
Изначально программное решение tcpdump разработано для среды *NIX, но на данный момент он также работает с несколькими портами Windows. Он обладает всей базовой функциональностью, которую вы ожидаете увидеть в любом анализаторе трафика — захват, запись и т. , — но требовать чего-то большего от него не стоит.
Kismet
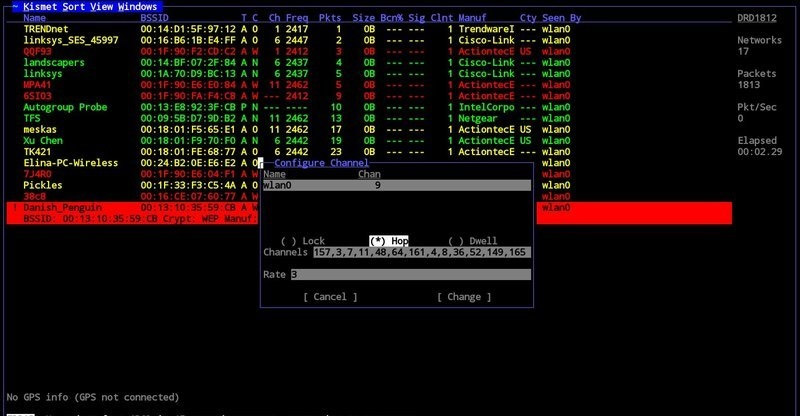
Анализатор трафика Kismet — еще один пример программного обеспечения с открытым исходным кодом, заточенного для решения конкретных задач. Kismet не просто анализирует сетевой трафик, он предоставляет вам гораздо более расширенные функциональные возможности. К примеру, он способен проводить анализ трафика скрытых сетей и даже беспроводных сетей, которые не транслируют свой идентификатор SSID! Подобный инструмент для анализа трафика может быть чрезвычайно полезен, когда в вашей беспроводной сети есть что-то, вызывающее проблемы, но быстро найти их источник вы не можете. Kismet поможет вам обнаружить неавторизированную сеть или точку доступа, которая работает, но имеет не совсем правильные настройки.
Многие из нас знают не понаслышке, что задача становится более сложной, когда дело доходит до анализа трафика беспроводных сетей, поэтому наличие под рукой такого специализированного инструмента, как Kismet, не только желательно, но и, зачастую, необходимо. Анализатор трафика Kismet станет прекрасным выбором для вас, если вы постоянно имеете дело с большим количеством беспроводного трафика и беспроводных устройств, и вы нуждаетесь в хорошем инструменте для анализа трафика беспроводной сети. Kismet доступен для сред * NIX, Windows под Cygwin и macOS.
EtherApe
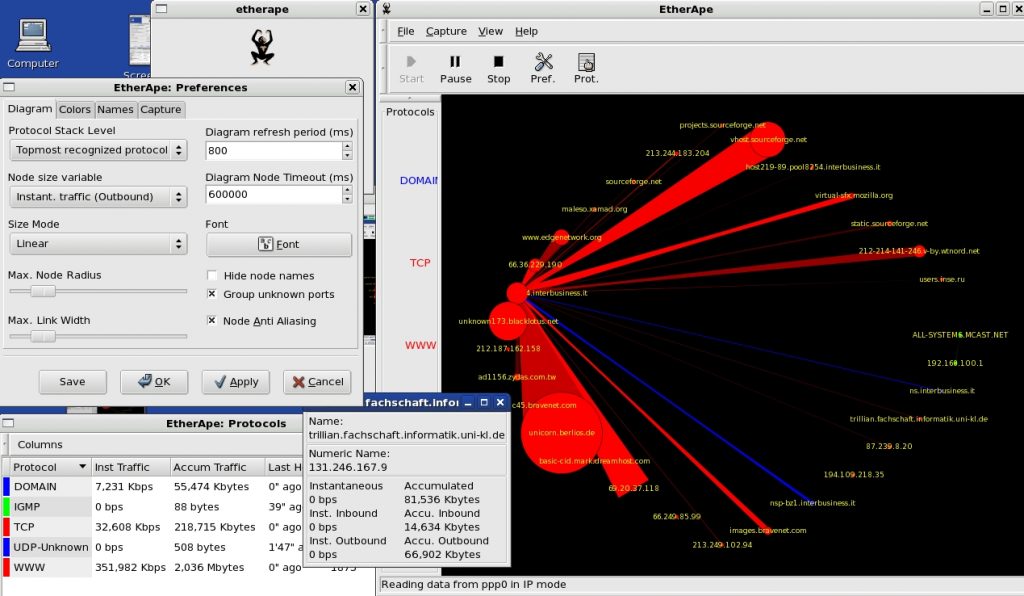
По своим функциональным возможностям EtherApe во многом приближается к WireShark, и он также является программным обеспечением с открытым исходным кодом и распространяется бесплатно. Однако то, чем он действительно выделяется на фоне других решений — это ориентация на графику. И если вы, к примеру, результаты анализа трафика WireShark просматриваете в классическом цифровом виде, то сетевой трафик EtherApe отображается с помощью продвинутого графического интерфейса, где каждая вершина графа представляет собой отдельный хост, размеры вершин и ребер указывают на размер сетевого трафика, а цветом отмечаются различные протоколы. Для тех людей, кто отдает предпочтение визуальному восприятию статистической информации, анализатор EtherApe может стать лучшим выбором. Доступен для сред *NIX и macOS.
Cain and Abel
У данного программного обеспечения с весьма любопытным названием возможность анализа трафика является скорее вспомогательной функцией, чем основной. Если ваши задачи выходят далеко за пределы простого анализа трафика, то вам стоит обратить внимание на этот инструмент. С его помощью вы можете восстанавливать пароли для ОС Windows, производить атаки для получения потерянных учетных данных, изучать данные VoIP в сети, анализировать маршрутизацию пакетов и многое другое. Это действительно мощный инструментарий для системного администратора с широкими полномочиями. Работает только в среде Windows.
NetworkMiner
Решение NetworkMiner — еще одно программное решение, чья функциональность выходит за рамки обычного анализа трафика. В то время как другие анализаторы трафика сосредотачивают свое внимание на отправке и получении пакетов, NetworkMiner следит за теми, кто непосредственно осуществляет эту отправку и получение. Этот инструмент больше подходит для выявления проблемных компьютеров или пользователей, чем для проведения общей диагностики или мониторинга сети как таковой. NetworkMiner разработан для ОС Windows.
KisMAC
KisMAC — название данного программного продукта говорит само за себя — это Kismet для macOS. В наши дни Kismet уже имеет порт для операционной среды macOS, поэтому существование KisMAC может показаться излишним, но тут стоит обратить внимание на тот факт, что решение KisMAC фактически имеет свою собственную кодовую базу и не является непосредственно производным от анализатора трафика Kismet. Особо следует отметить, что KisMAC предлагает некоторые возможности, такие как нанесение на карту местоположения и атака деаутентификации на macOS, которые Kismet сам по себе не предоставляет. Эти уникальные особенности в определенных ситуациях могут перевесить чашу весов в пользу именно этого программного решения.
«Сети»
Программное обеспечение для работы с сетями
Оценкам Загрузкам
Программа, которая позволит превратить компьютер, подключенный к сети в точку доступа.
Speed-O-Meter — программа для измерения скорости доступа в интернет.
Пакет, позволяющий быстро подключать компьютер к существующим локальным сетям или создавать собственные сети, не нуждающиеся в конфигурировании.
Простая и очень мощная программа, которая предназначена для учета интернет-трафика.
DUTraffic — удобный и функциональный монитор удалённого доступа, позволяющий вести подробную статистику сеансов, автоматически запускать программы при выходе в интернет (например, почтовый клиент и браузер) и закрывать их при разрыве связи.
Небольшая утилита для обеспечения дополнительной защиты беспроводной WiFi сети от взлома.
Virtual WiFi Router — это программа, позволяющая превратить ваш компьютер или ноутбук в точку доступа Wi-Fi.
Программа, предназначенная для установки и настройки маршрутизаторов компании MikroTik.
Virtual Router — простой и бесплатный виртуальный роутер для создания беспроводных сетей.
Самая популярная программа для организации сетевой игры в различных играх на ПК.
Connectify
2021. 40136
Программа, которая позволяет создать из вашего ПК роутер, к которому можно подключать устройства с Wi-Fi модулем.
Программа, позволяющая замерять скорость передачи данных в локальной сети.
Набор инструментов, предназначенных для работы с беспроводными сетями.
«Тестирование»
Программы для тестирования сети позволяют не только определить скорость обмена информацией между компьютером и сетевым ресурсом (и показать их в цифровом или графическом виде), но и существенно обезопасить ваш ПК. Такие программы способны к сбору данных, определенной привязке, оценке собранных данных. На основании полученной информации, программы для тестирования могут выявить уязвимости и оценить их опасность.
Аналог программы traceroute работающей под операционной системой Linux.
2ip Firewall Tester
Маленькая программа, позволяющая протестировать, насколько хорошо ваш файрволл защищает компьютер от сетевых атак.
Программа предназначена для проверки и сканирования офисной и домашней сети.
Высокоскоростной графический «трассировщик». Чтобы узнать какой путь проходит информация из интернета к вашему компьютеру вам необходимо просто перетащить в окно программы мышкой ссылку из вашего браузера.
Программа для фильтрации и анализа сетевых пакетов, а также для мониторинга состояния сети.
Пакет бенчмарков, которые используются для сравнения мощности игровых компьютеров и компьютеров для работы с 3D.
Проводим сканирование сети самостоятельно
В свете последних событий в мире много компаний перешли на удаленный режим работы. При этом для сохранения эффективности бизнес-процессов на сетевые периметры были вынесены приложения, которые не предназначены для прямого размещения на периметре, например внутрикорпоративные веб-приложения, на эту тему недавно было наше исследование. Если между службами ИТ и ИБ нет тесной связи, возникают ситуации, когда на сетевом периметре появилось бизнес-приложение, о котором у службы ИБ нет информации.
Решением подобных проблем может быть периодическое исследование периметра организации. Для решения задачи подходят сетевые сканеры, поисковики по интернету вещей, сканеры уязвимостей и услуги по анализу защищенности. Далее в статье рассмотрим виды и параметры сканирования, их преимущества и недостатки, инструменты, которые часто используются, и методы обработки результатов.
Ping-сканирование
Объединим TCP-сканирование и UDP-сканирование под общим названием — сканирование портов. Сканирование этими методами определяет доступные порты на узлах, а затем на основе полученных данных делается предположение о типе используемой операционной системы или конкретного приложения, запущенного на конечном узле. Под сканированием портов понимают пробные попытки подключения к внешним узлам. Рассмотрим основные методы, реализованные в автоматизированных сетевых сканерах:
- TCP SYN,
- TCP CONNECT,
- UDP scan.
Метод TCP SYN — наиболее популярен, используется в 95% случаев. Его называют сканированием с установкой полуоткрытого соединения, так как соединение не устанавливается до конца. На исследуемый порт посылается сообщение SYN, затем идет ожидание ответа, на основании которого определяется статус порта. Ответы SYN/ACK говорят о том, что порт прослушивается (открыт), а ответ RST говорит о том, что не прослушивается.
Если после нескольких запросов не приходит никакого ответа, то сетевой трафик до порта узла назначения фильтруется средствами межсетевого экранирования (далее будем использовать термин «порт фильтруется»). Также порт помечается как фильтруемый, если в ответ приходит сообщение ICMP с ошибкой достижимости (Destination Unreachable) и определенными кодами и флагами.
Метод TCP CONNECT менее популярен, чем TCP SYN, но все-таки часто встречается на практике. При реализации метода TCP CONNECT производится попытка установить соединение по протоколу TCP к нужному порту с процедурой handshake. Процедура заключается в обмене сообщениями для согласования параметров соединения, то есть служебными сообщениями SYN, SYN/ACK, ACK, между узлами. Соединение устанавливается на уровне операционной системы, поэтому существует шанс, что оно будет заблокировано средством защиты и попадет в журнал событий.
UDP-сканирование медленнее и сложнее, чем TCP-сканирование. Из-за специфики сканирования UDP-портов о них часто забывают, ведь полное время сканирование 65 535 UDP-портов со стандартными параметрами на один узел занимает у большинства автоматизированных сканеров до 18 часов. Это время можно уменьшить за счет распараллеливания процесса сканирования и рядом других способов. Следует уделять внимание поиску UDP-служб, потому что UDP-службы реализуют обмен данными с большим числом инфраструктурных сервисов, которые, как правило, вызывают интерес злоумышленников.
Для точности определения статуса порта и самой службы, запущенной на UDP-порте, используется специальная полезная нагрузка, наличие которой должно вызвать определенную реакцию у исследуемого приложения.
Процесс выявления уязвимостей
Под уязвимостью будем понимать слабое место узла в целом или его отдельных программных компонентов, которое может быть использовано для реализации атаки. В стандартной ситуации наличие уязвимостей объясняется ошибками в программном коде или используемой библиотеке, а также ошибками конфигурации.
Уязвимость регистрируется в MITRE CVE, а подробности публикуются в NVD. Уязвимости присваивается идентификатор CVE, а также общий балл системы оценки уязвимости CVSS, отражающий уровень риска, который уязвимость представляет для конечной системы. Подробно об оценке уязвимостей написано в нашей статье. Централизованный список MITRE CVE — ориентир для сканеров уязвимостей, ведь задача сканирования — обнаружить уязвимое программное обеспечение.
Ошибка конфигурации — тоже уязвимость, но подобные уязвимости нечасто попадают в базу MITRE; впрочем, они все равно попадают в базы знаний сканеров с внутренними идентификаторами. В базы знаний сканеров попадают и другие типы уязвимостей, которых нет в MITRE CVE, поэтому при выборе инструмента для сканирования важно обращать внимание на экспертизу его разработчика. Сканер уязвимостей будет опрашивать узлы и сравнивать собранную информацию с базой данных уязвимостей или списком известных уязвимостей. Чем больше информации у сканера, тем точнее результат.
Рассмотрим параметры сканирования, виды сканирования и принципы обнаружения уязвимостей при помощи сканеров уязвимостей.
Параметры сканирования
За месяц периметр организации может неоднократно поменяться. Проводя сканирование периметра в лоб можно затратить время, за которое результаты станут нерелевантными. При сильном увеличении скорости сканирования сервисы могут «упасть». Надо найти баланс и правильно выбрать параметры сканирования. От выбора зависят потраченное время, точность и релевантность результатов. Всего можно сканировать 65 535 TCP-портов и столько же UDP-портов. По нашему опыту, среднестатистический периметр компании, который попадает в пул сканирования, составляет две полных сети класса «С» с маской 24.
- количество портов,
- глубина сканирования,
- скорость сканирования,
- параметры определения уязвимостей.
По количеству портов сканирование можно разделить на три вида — сканирование по всему списку TCP- и UDP-портов, сканирование по всему списку TCP-портов и популярных UDP-портов, сканирование популярных TCP- и UDP-портов. Как определить популярности порта? В утилите nmap на основе статистики, которую собирает разработчик утилиты, тысяча наиболее популярных портов определена в конфигурационном файле. Коммерческие сканеры также имеют преднастроенные профили, включающие до 3500 портов.
Если в сети используются сервисы на нестандартных портах, их также стоит добавить в список сканируемых. Для регулярного сканирования мы рекомендуем использовать средний вариант, при котором сканируются все TCP-порты и популярные UDP-порты. Такой вариант наиболее сбалансирован по времени и точности результатов. При проведении тестирования на проникновение или полного аудита сетевого периметра рекомендуется сканировать все TCP- и UDP-порты.
Важная ремарка: не получится увидеть реальную картину периметра, сканируя из локальной сети, потому что на сканер будут действовать правила межсетевых экранов для трафика из внутренней сети. Сканирование периметра необходимо проводить с одной или нескольких внешних площадок; в использовании разных площадок есть смысл, только если они расположены в разных странах.
Под глубиной сканирования подразумевается количество данных, которые собираются о цели сканирования. Сюда входит операционная система, версии программного обеспечения, информация об используемой криптографии по различным протоколам, информация о веб-приложениях. При этом имеется прямая зависимость: чем больше хотим узнать, тем дольше сканер будет работать и собирать информацию об узлах.
При выборе скорости необходимо руководствоваться пропускной способностью канала, с которого происходит сканирование, пропускной способностью канала, который сканируется, и возможностями сканера. Существуют пороговые значения, превышение которых не позволяет гарантировать точность результатов, сохранение работоспособности сканируемых узлов и отдельных служб. Не забывайте учитывать время, за которое необходимо успеть провести сканирование.
Параметры определения уязвимостей — наиболее обширный раздел параметров сканирования, от которого зависит скорость сканирования и объем уязвимостей, которые могут быть обнаружены. Например, баннерные проверки не займут много времени. Имитации атак будут проведены только для отдельных сервисов и тоже не займут много времени. Самый долгий вид — веб-сканирование.
Полное сканирование сотни веб-приложений может длиться неделями, так как зависит от используемых словарей и количества входных точек приложения, которые необходимо проверить. Важно понимать, что из-за особенностей реализации веб-модулей и веб-сканеров инструментальная проверка веб-уязвимостей не даст стопроцентной точности, но может очень сильно замедлить весь процесс.
Веб-сканирование лучше проводить отдельно от регулярного, тщательно выбирая приложения для проверки. Для глубокого анализа использовать инструменты статического и динамического анализа приложений или услуги тестирования на проникновение. Мы не рекомендуем использовать опасные проверки при проведении регулярного сканирования, поскольку существует риск нарушения работоспособности сервисов. Подробно о проверках см. далее, в разделе про работу сканеров.
Инструментарий
Если вы когда-нибудь изучали журналы безопасности своих узлов, наверняка замечали, что интернет сканирует большое количество исследователей, онлайн-сервисы, ботнеты. Подробно описывать все инструменты нет смысла, перечислим некоторые сканеры и сервисы, которые используются для сканирования сетевых периметров и интернета. Каждый из инструментов сканирования служит своей цели, поэтому при выборе инструмента должно быть понимание, зачем он используется. Иногда правильно применять несколько сканеров для получения полных и точных результатов.
Сетевые сканеры: Masscan, Zmap, nmap. На самом деле утилит для сканирования сети намного больше, однако для сканирования периметра вряд ли вам понадобятся другие. Эти утилиты позволяют решить большинство задач, связанных со сканированием портов и служб.
Поисковики по интернету вещей, или онлайн-сканеры — важные инструменты для сбора информации об интернете в целом. Они предоставляют сводку о принадлежности узлов к организации, сведения о сертификатах, активных службах и иную информацию. С разработчиками этого типа сканеров можно договориться об исключении ваших ресурсов из списка сканирования или о сохранении информации о ресурсах только для корпоративного пользования. Наиболее известные поисковики: Shodan, Censys, Fofa.
Для решения задачи не обязательно применять сложный коммерческий инструмент с большим числом проверок: это излишне для сканирования пары «легких» приложений и сервисов. В таких случаях будет достаточно бесплатных сканеров. Бесплатных веб-сканеров много, и тяжело выделить наиболее эффективные, здесь выбор, скорее, дело вкуса; наиболее известные: Skipfish, Nikto, ZAP, Acunetix, SQLmap.
Для выполнения минимальных задач сканирования и обеспечения «бумажной» безопасности могут подойти бюджетные коммерческие сканеры с постоянно пополняемой базой знаний уязвимостей, а также поддержкой и экспертизой от вендора, сертификатами ФСТЭК. Наиболее известные: XSpider, RedCheck, Сканер-ВС.
При тщательном ручном анализе будут полезны инструменты Burp Suite, Metasploit и OpenVAS. Недавно вышел сканер Tsunami компании Google.
Отдельной строкой стоит упомянуть об онлайн-поисковике уязвимостей Vulners. Это большая база данных контента информационной безопасности, где собирается информация об уязвимостях с большого количества источников, куда, кроме типовых баз, входят вендорские бюллетени безопасности, программы bug bounty и другие тематические ресурсы. Ресурс предоставляет API, через который можно забирать результаты, поэтому можно реализовать баннерные проверки своих систем без фактического сканирования здесь и сейчас. Либо использовать Vulners vulnerability scanner, который будет собирать информацию об операционной системе, установленных пакетах и проверять уязвимости через API Vulners. Часть функций ресурса платные.
Средства анализа защищенности
Все коммерческие системы защиты поддерживают основные режимы сканирования, которые описаны ниже, интеграцию с различными внешними системами, такими как SIEM-системы, patch management systems, CMBD, системы тикетов. Коммерческие системы анализа уязвимостей могут присылать оповещения по разным критериям, а поддерживают различные форматы и типы отчетов. Все разработчики систем используют общие базы уязвимостей, а также собственные базы знаний, которые постоянно обновляются на основе исследований.
Основные различия между коммерческими средствами анализа защищенности — поддерживаемые стандарты, лицензии государственных структур, количество и качество реализованных проверок, а также направленность на тот или иной рынок сбыта, например поддержка сканирования отечественного ПО. Статья не призвана представить качественное сравнение систем анализа уязвимостей. На наш взгляд, у каждой системы есть свои преимущества и недостатки. Для анализа защищенности подходят перечисленные средства, можно использовать их комбинации: Qualys, MaxPatrol 8, Rapid 7 InsightVM, Tenable SecurityCenter.
Как работают системы анализа защищенности
Режимы сканирования реализованы по трем схожим принципам:
- Аудит, или режим белого ящика.
- Комплаенс, или проверка на соответствие техническим стандартам.
- Пентест, или режим черного ящика.
Основной интерес при сканировании периметра представляет режим черного ящика, потому что он моделирует действия внешнего злоумышленника, которому ничего не известно об исследуемых узлах. Ниже представлена краткая справка обо всех режимах.
Аудит — режим белого ящика, который позволяет провести полную инвентаризацию сети, обнаружить все ПО, определить его версии и параметры и на основе этого сделать выводы об уязвимости систем на детальном уровне, а также проверить системы на использование слабых паролей. Процесс сканирования требует определенной степени интеграции с корпоративной сетью, в частности необходимы учетные записи для авторизации на узлах.
Авторизованному пользователю, в роли которого выступает сканер, значительно проще получать детальную информацию об узле, его программном обеспечении и конфигурационных параметрах. При сканировании используются различные механизмы и транспорты операционных систем для сбора данных, зависящие от специфики системы, с которой собираются данные. Список транспортов включает, но не ограничивается WMI, NetBios, LDAP, SSH, Telnet, Oracle, MS SQL, SAP DIAG, SAP RFC, Remote Engine с использованием соответствующих протоколов и портов.
Комплаенс — режим проверки на соответствие каким-либо стандартам, требованиям или политикам безопасности. Режим использует схожие с аудитом механизмы и транспорты. Особенность режима — возможность проверки корпоративных систем на соответствие стандартам, которые заложены в сканеры безопасности. Примерами стандартов являются PCI DSS для платежных систем и процессинга, СТО БР ИББС для российских банков, GDPR для соответствия требованиям Евросоюза. Другой пример — внутренние политики безопасности, которые могут иметь более высокие требования, чем указанные в стандартах. Кроме того, существуют проверки установки обновлений и другие пользовательские проверки.
Пентест — режим черного ящика, в котором у сканера нет никаких данных, кроме адреса цели или доменного имени. Рассмотрим типы проверок, которые используются в режиме:
- баннерные проверки,
- имитация атак,
- веб-проверки,
- проверки конфигураций,
- опасные проверки.
Баннерные проверки основываются на том, что сканер определяет версии используемого программного обеспечения и операционной системы, а затем сверяет эти версии со внутренней базой уязвимостей. Для поиска баннеров и версий используются различные источники, достоверность которых также различается и учитывается внутренней логикой работы сканера. Источниками могут быть баннеры сервиса, журналы, ответы приложений и их параметры и формат. При анализе веб-серверов и приложений проверяется информация со страниц ошибок и запрета доступа, анализируются ответы этих серверов и приложений и другие возможные источники информации. Сканеры помечают уязвимости, обнаруженные баннерной проверкой, как подозрения на уязвимость или как неподтвержденную уязвимость.
Имитация атаки — это безопасная попытка эксплуатации уязвимости на узле. Имитации атаки имеют низкий шанс на ложное срабатывание и тщательно тестируются. Когда сканер обнаруживает на цели сканирования характерный для уязвимости признак, проводится эксплуатация уязвимости. При проверках используют методы, необходимые для обнаружения уязвимости; к примеру, приложению посылается нетипичный запрос, который не вызывает отказа в обслуживании, а наличие уязвимости определяется по ответу, характерному для уязвимого приложения.
Другой метод: при успешной эксплуатации уязвимости, которая позволяет выполнить код, сканер может направить исходящий запрос типа PING либо DNS-запрос от уязвимого узла к себе. Важно понимать, что не всегда уязвимости удается проверить безопасно, поэтому зачастую в режиме пентеста проверки появляются позже, чем других режимах сканирования.
Веб-проверки — наиболее обширный и долгий вид проверок, которым могут быть подвергнуты обнаруженные веб-приложения. На первом этапе происходит сканирование каталогов веб-приложения, обнаруживаются параметры и поля, где потенциально могут быть уязвимости. Скорость такого сканирования зависит от используемого словаря для перебора каталогов и от размера веб-приложения.
На этом же этапе собираются баннеры CMS и плагинов приложения, по которым проводится баннерная проверка на известные уязвимости. Следующий этап — основные веб-проверки: поиск SQL Injection разных видов, поиск недочетов системы аутентификации и хранения сессий, поиск чувствительных данных и незащищенных конфигураций, проверки на XXE Injection, межсайтовый скриптинг, небезопасную десериализацию, загрузку произвольных файлов, удаленное исполнение кода и обход пути. Список может быть шире в зависимости от параметров сканирования и возможностей сканера, обычно при максимальных параметрах проверки проходят по списку OWASP Top Ten.
Проверки конфигураций направлены на выявление ошибок конфигураций ПО. Они выявляют пароли по умолчанию либо перебирают пароли по короткому заданному списку с разными учетными записями. Выявляют административные панели аутентификации и управляющие интерфейсы, доступные принтеры, слабые алгоритмы шифрования, ошибки прав доступа и раскрытие конфиденциальной информации по стандартным путям, доступные для скачивания резервные копии и другие подобные ошибки, допущенные администраторами IT-систем и систем ИБ.
В число опасных проверок попадают те, использование которых потенциально приводит к нарушению целостности или доступности данных. Сюда относят проверки на отказ в обслуживании, варианты SQL Injection с параметрами на удаление данных или внесение изменений. Атаки перебора паролей без ограничений попыток подбора, которые приводят к блокировке учетной записи. Опасные проверки крайне редко используются из-за возможных последствий, однако поддерживаются сканерами безопасности как средство эмуляции действий злоумышленника, который не будет переживать за сохранность данных.
Устранение уязвимостей
Первым шагом к правильной технической реализации процесса устранения уязвимостей является грамотное представление результатов сканирования, с которыми придется работать. Если используется несколько разнородных сканеров, правильнее всего будет анализировать и объединять информацию по узлам в одном месте. Для этого рекомендуется использовать аналитические системы, где также будет храниться вся информация об инвентаризации. Базовым способом для устранения уязвимости является установка обновлений. Можно использовать и другой способ — вывести сервис из состава периметра (при этом все равно необходимо установить обновления безопасности).
Можно применять компенсирующие меры по настройке, то есть исключать использование уязвимого компонента или приложения. Еще вариант — использовать специализированные средства защиты, такие как IPS или application firewall. Конечно, правильнее не допускать появления нежелательных сервисов на сетевом периметре, но такой подход не всегда возможен в силу различных обстоятельств, в особенности требований бизнеса.
Приоритет устранения уязвимостей
Приоритет устранения уязвимостей зависит от внутренних процессов в организации. При работе по устранению уязвимостей для сетевого периметра важно четкое понимание, для чего сервис находится на периметре, кто его администрирует и кто является его владельцем. В первую очередь можно устранять уязвимости на узлах, которые отвечают за критически важные бизнес-функции компании. Естественно, такие сервисы нельзя вывести из состава периметра, однако можно применить компенсирующие меры или дополнительные средства защиты. С менее значимыми сервисами проще: их можно временно вывести из состава периметра, не спеша обновить и вернуть в строй.
Другой способ — приоритет устранения по опасности или количеству уязвимостей на узле. Когда на узле обнаруживается 10–40 подозрений на уязвимость от баннерной проверки — нет смысла проверять, существуют ли они там все, в первую очередь это сигнал о том, что пора обновить программное обеспечение на этом узле. Когда возможности для обновления нет, необходимо прорабатывать компенсирующие меры. Если в организации большое количество узлов, где обнаруживаются уязвимые компоненты ПО, для которых отсутствуют обновления, то пора задуматься о переходе на программного обеспечение, еще находящееся в цикле обновления (поддержки). Возможна ситуация, когда для обновления программного обеспечения сначала требуется обновить операционную систему.
Моральное устаревание диагностических инструментов
В современном мире диагностика, увы не очень показательна. Во-первых, потому, что она базируется на протоколах 40-летней давности (RFC 792 — от 1981-го года) и превращается в лупу в эпоху электронных микроскопов. А во-вторых, у этих протоколов есть большие проблемы в части безопасности. Если какой-то маршрутизатор полностью отвечает RFC 792, то его можно элементарно атаковать с помощью DDoS атаки (чем хакеры в нулевых и баловались). Поэтому, даже эти протоколы работают плохо благодаря закрученным гайкам.
Прямым следствием этих ограничений является типичный сценарий решения сетевых проблем:
Пользователь обращается к провайдеру и говорит, что с сайтом А у него проблемы и плохая связь. Провайдер обычно всегда говорит: у нас всё хорошо, проблемы у сайта.
Когда пользователь обращается в поддержку сайта, то ему там говорят то же самое – у нас всё хорошо, обратитесь к провайдеру.
В итоге, проблема конечно же не решается.
Ниже мы всё-таки попробуем определиться, где именно проблема.
К сожалению для статьи, и к счастью для автора, у автора всё в порядке с интернетом. Потому, примеров «смотрите – слева всё плохо, а справа всё хорошо» практически не будет. Но, где возможно – я всё-таки попробую что-нибудь сломать для наглядности.
Маршруты интернета
В первой части статьи я рассказывал, что трафик ходит по маршрутам. Их два : BGP и IP. Один поверх другого. BGP — определяет маршрут через физические маршрутизаторы, а IP — уже логическая составляющая пути. На этом этапе диагностика затруднена тем, что :
- Вводная по BGP это TTTLDR.
- Благодаря таким технологиям, как AnyCast, IP 11.22.33.44 на маршруте может физически находиться в любом месте, и в двух+ местах одновременно : AnyCast позволяет указать, что за этот IP отвечает сервер в Нью-Йорке и в Москве. При пинге этого IP вы не можете однозначно утверждать, что вы пингуете именно Московский сервер.
- Так же есть MPLS и иное туннелирование. Разобрать маршруты тоннелей, простыми инструментами не получится.
- Пакет «туда» и пакет «обратно» может пойти разными путями.
- Пакет «туда» может пойти по нескольким путям в разное время. Инструментов для диагностики ECMP на домашних OS немного, они сложнее простого tracert, а иногда, стоят дорого.
Будем работать с тем что есть. А есть у нас команда traceroute.
На windows она выполняется из Пуск/cmd и ввести tracert. Так же есть графическая утилита WinMTR. Она дает больше полезной информации и, в некоторых случаях, будем пользоваться ей.
Можно не запускать cmd и там выполнять команды, а делать это windows-style:
Пуск/выполнить cmd /k tracert -d что-нибудь
Ключевые правила диагностики:
- Если вы не можете продемонстрировать и повторить проблему, то никто не сможет.
- Данные нужно собирать за несколько временных периодов – как минимум, за период, когда проблем нет, и за период, когда проблемы есть.