
Методы, обеспечивающие надежную доставку цифровых данных по ненадежным каналам связи

Устранение ошибок передачи, вызванных атмосферой Земли ( слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется в компакт-дисках и DVD. Типичные ошибки включают отсутствие пикселей (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
В теории информации и теории кодирования с приложениями в информатике и телекоммуникациях, обнаружение и исправление ошибок или контроль ошибок — это методы, которые обеспечивают надежную доставку цифровых данных по ненадежным каналам связи. Многие каналы связи подвержены канальному шуму, и поэтому во время передачи от источника к приемнику могут возникать ошибки. Методы обнаружения ошибок позволяют обнаруживать такие ошибки, а исправление ошибок во многих случаях позволяет восстановить исходные данные.
Определения
Обнаружение ошибок — это обнаружение ошибок, вызванных шумом или другими помехами во время передачи от передатчика к приемнику. Исправление ошибок — это обнаружение ошибок и восстановление исходных безошибочных данных.
История
Современная разработка кодов исправления ошибок приписывается Ричарду Хэммингу в 1947 году. Описание кода Хэмминга появилось в Математической теории коммуникации Клода Шеннона и было быстро обобщено Марселем Дж. Э. Голэем.
Введение
Все схемы обнаружения и исправления ошибок добавляют некоторые избыточность (т. е. некоторые дополнительные данные) сообщения, которые получатели могут использовать для проверки согласованности доставленного сообщения и для восстановления данных, которые были определены как поврежденные. Схемы обнаружения и исправления ошибок могут быть систематическими или несистематическими. В систематической схеме передатчик отправляет исходные данные и присоединяет фиксированное количество контрольных битов (или данных четности), которые выводятся из битов данных некоторым детерминированным алгоритмом. Если требуется только обнаружение ошибок, приемник может просто применить тот же алгоритм к полученным битам данных и сравнить свой вывод с полученными контрольными битами; если значения не совпадают, в какой-то момент во время передачи произошла ошибка. В системе, которая использует несистематический код, исходное сообщение преобразуется в закодированное сообщение, несущее ту же информацию и имеющее по крайней мере такое же количество битов, как и исходное сообщение.
Хорошие характеристики контроля ошибок требуют, чтобы схема была выбрана на основе характеристик канала связи. Распространенные модели каналов включают в себя модели без памяти, в которых ошибки возникают случайно и с определенной вероятностью, и динамические модели, в которых ошибки возникают в основном в пакетах . Следовательно, коды обнаружения и исправления ошибок можно в целом различать между обнаружением / исправлением случайных ошибок и обнаружением / исправлением пакетов ошибок. Некоторые коды также могут подходить для сочетания случайных ошибок и пакетных ошибок.
Если характеристики канала не могут быть определены или сильно изменяются, схема обнаружения ошибок может быть объединена с системой для повторных передач ошибочных данных. Это известно как автоматический запрос на повторение (ARQ) и наиболее широко используется в Интернете. Альтернативный подход для контроля ошибок — это гибридный автоматический запрос на повторение (HARQ), который представляет собой комбинацию ARQ и кодирования с исправлением ошибок.
Типы исправления ошибок
Существует три основных типа исправления ошибок.
Автоматический повторный запрос (ARQ)
Автоматический повторный запрос (ARQ) — это метод контроля ошибок для передачи данных, который использует коды обнаружения ошибок, сообщения подтверждения и / или отрицательного подтверждения и тайм-ауты для обеспечения надежной передачи данных. Подтверждение — это сообщение, отправленное получателем, чтобы указать, что он правильно получил кадр данных.
Обычно, когда передатчик не получает подтверждения до истечения тайм-аута (т. Е. В течение разумного периода времени после отправки фрейм данных), он повторно передает фрейм до тех пор, пока он либо не будет правильно принят, либо пока ошибка не останется сверх заранее определенного количества повторных передач.
Три типа протоколов ARQ: Stop-and-wait ARQ, Go-Back-N ARQ и Selective Repeat ARQ.
ARQ is подходит, если канал связи имеет переменную или неизвестную пропускную способность, например, в случае с Интернетом. Однако ARQ требует наличия обратного канала, что приводит к возможному увеличению задержки из-за повторных передач и требует обслуживания буферов и таймеров для повторных передач, что в случае перегрузка сети может вызвать нагрузку на сервер и общую пропускную способность сети.
Например, ARQ используется на коротковолновых радиоканалах в форме ARQ-E, или в сочетании с мультиплексированием как ARQ-M.
Прямое исправление ошибок
Прямое исправление ошибок (FEC) — это процесс добавления избыточных данных, таких как исправление ошибок code (ECC) в сообщение, чтобы оно могло быть восстановлено получателем, даже если в процессе передачи или при хранении был внесен ряд ошибок (в зависимости от возможностей используемого кода). Так как получатель не должен запрашивать у отправителя повторную передачу данных, обратный канал не требуется при прямом исправлении ошибок, и поэтому он подходит для симплексной связи, например вещание. Коды с исправлением ошибок часто используются в нижнем уровне связи, а также для надежного хранения на таких носителях, как CD, DVD, жесткие диски и RAM.
Коды с исправлением ошибок обычно различают между сверточными кодами и блочными кодами. :
- Сверточные коды обрабатываются побитно. Они особенно подходят для аппаратной реализации, а декодер Витерби обеспечивает оптимальное декодирование.
- Блочные коды обрабатываются на поблочной основе. Ранними примерами блочных кодов являются коды повторения, коды Хэмминга и многомерные коды контроля четности. За ними последовал ряд эффективных кодов, из которых коды Рида – Соломона являются наиболее известными из-за их широкого распространения в настоящее время. Турбокоды и коды с низкой плотностью проверки четности (LDPC) — это относительно новые конструкции, которые могут обеспечить почти оптимальную эффективность.
Теорема Шеннона — важная теорема при прямом исправлении ошибок и описывает максимальную информационную скорость, на которой возможна надежная связь по каналу, имеющему определенную вероятность ошибки или отношение сигнал / шум (SNR). Этот строгий верхний предел выражается в единицах пропускной способности канала . Более конкретно, в теореме говорится, что существуют такие коды, что с увеличением длины кодирования вероятность ошибки на дискретном канале без памяти может быть сделана сколь угодно малой при условии, что кодовая скорость меньше чем емкость канала. Кодовая скорость определяется как доля k / n из k исходных символов и n кодированных символов.
Фактическая максимальная разрешенная кодовая скорость зависит от используемого кода исправления ошибок и может быть ниже. Это связано с тем, что доказательство Шеннона носило только экзистенциальный характер и не показало, как создавать коды, которые одновременно являются оптимальными и имеют эффективные алгоритмы кодирования и декодирования.
Гибридные схемы
Гибридный ARQ — это комбинация ARQ и прямого исправления ошибок. Существует два основных подхода:
- Сообщения всегда передаются с данными четности FEC (и избыточностью для обнаружения ошибок). Получатель декодирует сообщение, используя информацию о четности, и запрашивает повторную передачу с использованием ARQ только в том случае, если данных четности было недостаточно для успешного декодирования (идентифицировано посредством неудачной проверки целостности).
- Сообщения передаются без данных четности (только с информация об обнаружении ошибок). Если приемник обнаруживает ошибку, он запрашивает информацию FEC от передатчика с помощью ARQ и использует ее для восстановления исходного сообщения.
Последний подход особенно привлекателен для канала стирания при использовании код бесскоростного стирания.
Схемы обнаружения ошибок
Обнаружение ошибок чаще всего реализуется с использованием подходящей хэш-функции (или, в частности, контрольной суммы, циклической проверка избыточности или другой алгоритм). Хеш-функция добавляет к сообщению тег фиксированной длины, который позволяет получателям проверять доставленное сообщение, повторно вычисляя тег и сравнивая его с предоставленным.
Существует огромное количество различных конструкций хеш-функций. Однако некоторые из них имеют особенно широкое распространение из-за их простоты или их пригодности для обнаружения определенных видов ошибок (например, производительности циклического контроля избыточности при обнаружении пакетных ошибок ).
Кодирование с минимальным расстоянием
Код с исправлением случайных ошибок на основе кодирования с минимальным расстоянием может обеспечить строгую гарантию количества обнаруживаемых ошибок, но может не защитить против атаки прообразом.
Коды повторения
A код повторения — это схема кодирования, которая повторяет биты по каналу для достижения безошибочной связи. Учитывая поток данных, которые необходимо передать, данные делятся на блоки битов. Каждый блок передается определенное количество раз. Например, чтобы отправить битовую комбинацию «1011», четырехбитовый блок можно повторить три раза, таким образом получая «1011 1011 1011». Если этот двенадцатибитовый шаблон был получен как «1010 1011 1011» — где первый блок не похож на два других, — произошла ошибка.
Код повторения очень неэффективен и может быть подвержен проблемам, если ошибка возникает в одном и том же месте для каждой группы (например, «1010 1010 1010» в предыдущем примере будет определено как правильное). Преимущество кодов повторения состоит в том, что они чрезвычайно просты и фактически используются в некоторых передачах номеров станций.
Бит четности
Бит четности — это бит, который добавляется к группе исходные биты, чтобы гарантировать, что количество установленных битов (т. е. битов со значением 1) в результате будет четным или нечетным. Это очень простая схема, которую можно использовать для обнаружения одного или любого другого нечетного числа (т. Е. Трех, пяти и т. Д.) Ошибок в выводе. Четное количество перевернутых битов сделает бит четности правильным, даже если данные ошибочны.
Расширениями и вариантами механизма битов четности являются проверки с продольным избыточным кодом, проверки с поперечным избыточным кодом и аналогичные методы группирования битов.
Контрольная сумма
Контрольная сумма сообщения — это модульная арифметическая сумма кодовых слов сообщения фиксированной длины слова (например, байтовых значений). Сумма может быть инвертирована посредством операции дополнения до единиц перед передачей для обнаружения непреднамеренных сообщений с нулевым значением.
Схемы контрольных сумм включают биты четности, контрольные цифры и проверки продольным избыточным кодом. Некоторые схемы контрольных сумм, такие как алгоритм Дамма, алгоритм Луна и алгоритм Верхоффа, специально разработаны для обнаружения ошибок, обычно вносимых людьми при записи или запоминание идентификационных номеров.
Проверка циклическим избыточным кодом
Проверка циклическим избыточным кодом (CRC) — это незащищенная хэш-функция, предназначенная для обнаружения случайных изменений цифровых данных в компьютерных сетях. Он не подходит для обнаружения злонамеренно внесенных ошибок. Он характеризуется указанием порождающего полинома, который используется в качестве делителя в полиномиальном делении над конечным полем, принимая входные данные в качестве дивиденд. остаток становится результатом.
CRC имеет свойства, которые делают его хорошо подходящим для обнаружения пакетных ошибок. CRC особенно легко реализовать на оборудовании и поэтому обычно используются в компьютерных сетях и устройствах хранения, таких как жесткие диски.
. Бит четности может рассматриваться как 1-битный частный случай. CRC.
Криптографическая хеш-функция
Выходные данные криптографической хеш-функции, также известные как дайджест сообщения, могут обеспечить надежную гарантию целостности данных, независимо от того, происходят ли изменения данных случайно (например, из-за ошибок передачи) или злонамеренно. Любая модификация данных, скорее всего, будет обнаружена по несоответствию хеш-значения. Кроме того, с учетом некоторого хэш-значения, как правило, невозможно найти некоторые входные данные (кроме заданных), которые дадут такое же хеш-значение. Если злоумышленник может изменить не только сообщение, но и значение хеш-функции, то для дополнительной безопасности можно использовать хэш-код с ключом или код аутентификации сообщения (MAC). Не зная ключа, злоумышленник не может легко или удобно вычислить правильное ключевое значение хеш-функции для измененного сообщения.
Код исправления ошибок
Для обнаружения ошибок можно использовать любой код исправления ошибок. Код с минимальным расстоянием Хэмминга, d, может обнаруживать до d — 1 ошибок в кодовом слове. Использование кодов с коррекцией ошибок на основе минимального расстояния для обнаружения ошибок может быть подходящим, если требуется строгое ограничение на минимальное количество обнаруживаемых ошибок.
Коды с минимальным расстоянием Хэмминга d = 2 являются вырожденными случаями кодов с исправлением ошибок и могут использоваться для обнаружения одиночных ошибок. Бит четности является примером кода обнаружения одиночной ошибки.
Приложения
Приложения, которым требуется низкая задержка (например, телефонные разговоры), не могут использовать автоматический запрос на повторение (ARQ); они должны использовать прямое исправление ошибок (FEC). К тому времени, когда система ARQ обнаружит ошибку и повторно передаст ее, повторно отправленные данные прибудут слишком поздно, чтобы их можно было использовать.
Приложения, в которых передатчик сразу же забывает информацию, как только она отправляется (например, большинство телекамер), не могут использовать ARQ; они должны использовать FEC, потому что при возникновении ошибки исходные данные больше не доступны.
Приложения, использующие ARQ, должны иметь канал возврата ; приложения, не имеющие обратного канала, не могут использовать ARQ.
Приложения, требующие чрезвычайно низкого уровня ошибок (например, цифровые денежные переводы), должны использовать ARQ из-за возможности неисправимых ошибок с помощью FEC.
Надежность и инженерная проверка также используют теорию кодов исправления ошибок.
Интернет
В типичном стеке TCP / IP ошибка управление осуществляется на нескольких уровнях:
- Каждый кадр Ethernet использует CRC-32 обнаружение ошибок. Фреймы с обнаруженными ошибками отбрасываются оборудованием приемника.
- Заголовок IPv4 содержит контрольную сумму , защищающую содержимое заголовка. Пакеты с неверными контрольными суммами отбрасываются в сети или на приемнике.
- Контрольная сумма не указана в заголовке IPv6, чтобы минимизировать затраты на обработку в сетевой маршрутизации и поскольку предполагается, что текущая технология канального уровня обеспечивает достаточное обнаружение ошибок (см. также RFC 3819 ).
- UDP, имеет дополнительную контрольную сумму, покрывающую полезную нагрузку и информацию об адресации в заголовки UDP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком . Контрольная сумма не является обязательной для IPv4 и требуется для IPv6. Если не указано, предполагается, что уровень канала передачи данных обеспечивает желаемый уровень защиты от ошибок.
- TCP обеспечивает контрольную сумму для защиты полезной нагрузки и адресной информации в заголовках TCP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком и в конечном итоге повторно передаются с использованием ARQ либо явно (например, как через тройное подтверждение ) или неявно из-за тайм-аута .
Телекоммуникации в дальнем космосе
Разработка кодов исправления ошибок была тесно связана с историей полетов в дальний космос из-за сильного ослабления мощности сигнала на межпланетных расстояниях и ограниченной мощности на борту космических зондов. В то время как ранние миссии отправляли свои данные в незашифрованном виде, начиная с 1968 года, цифровая коррекция ошибок была реализована в форме (субоптимально декодированных) сверточных кодов и кодов Рида – Маллера. Код Рида-Мюллера хорошо подходил к шуму, которому подвергался космический корабль (примерно соответствуя кривой ), и был реализован для космического корабля Mariner и использовался в миссиях между 1969 и 1977 годами.
Миссии «Вояджер-1 » и «Вояджер-2 «, начатые в 1977 году, были разработаны для доставки цветных изображений и научной информации с Юпитера и Сатурна. Это привело к повышенным требованиям к кодированию, и, таким образом, космический аппарат поддерживался (оптимально Витерби-декодированный ) сверточными кодами, которые могли быть сцеплены с внешним Голеем (24,12, 8) код. Корабль «Вояджер-2» дополнительно поддерживал реализацию кода Рида-Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
Консультативный комитет по космическим информационным системам в настоящее время рекомендует использовать коды исправления ошибок, как минимум, аналогичные RSV-коду Voyager 2. Составные коды все больше теряют популярность в космических миссиях и заменяются более мощными кодами, такими как Турбо-коды или LDPC-коды.
Различные виды выполняемых космических и орбитальных миссий. предполагают, что попытки найти универсальную систему исправления ошибок будут постоянной проблемой. Для полетов вблизи Земли характер шума в канале связи отличается от того, который испытывает космический корабль в межпланетной миссии. Кроме того, по мере того как космический корабль удаляется от Земли, проблема коррекции шума становится все более сложной.
Спутниковое вещание
Спрос на пропускную способность спутникового транспондера продолжает расти, чему способствует желание предоставлять телевидение (включая новые каналы и телевидение высокой четкости ) и данные IP. Доступность транспондеров и ограничения полосы пропускания ограничили этот рост. Емкость транспондера определяется выбранной схемой модуляции и долей мощности, потребляемой FEC.
Хранение данных
Коды обнаружения и исправления ошибок часто используются для повышения надежности носителей данных. «Дорожка четности» присутствовала на первом устройстве хранения данных на магнитной ленте в 1951 году. «Оптимальный прямоугольный код», используемый в записи с групповым кодированием, не только обнаруживает, но и корректирует однобитовые записи. ошибки. Некоторые форматы файлов, особенно архивные форматы, включают контрольную сумму (чаще всего CRC32 ) для обнаружения повреждений и усечения и могут использовать избыточность и / или четность files для восстановления поврежденных данных. Коды Рида-Соломона используются в компакт-дисках для исправления ошибок, вызванных царапинами.
Современные жесткие диски используют коды CRC для обнаружения и коды Рида – Соломона для исправления незначительных ошибок при чтении секторов, а также для восстановления данных из секторов, которые «испортились», и сохранения этих данных в резервных секторах. Системы RAID используют различные методы исправления ошибок для исправления ошибок, когда жесткий диск полностью выходит из строя. Файловые системы, такие как ZFS или Btrfs, а также некоторые реализации RAID, поддерживают очистку данных и восстановление обновлений, что позволяет удалять поврежденные блоки. обнаружены и (надеюсь) восстановлены, прежде чем они будут использованы. Восстановленные данные могут быть перезаписаны точно в том же физическом месте, чтобы освободить блоки в другом месте на том же оборудовании, или данные могут быть перезаписаны на заменяющее оборудование.
Память с исправлением ошибок
Память DRAM может обеспечить более надежную защиту от программных ошибок, полагаясь на коды исправления ошибок. Такая память с исправлением ошибок, известная как память с защитой ECC или EDAC, особенно желательна для критически важных приложений, таких как научные вычисления, финансы, медицина и т. Д., А также для приложений дальнего космоса из-за повышенное излучение в космосе.
Контроллеры памяти с исправлением ошибок традиционно используют коды Хэмминга, хотя некоторые используют тройную модульную избыточность.
Чередование позволяет распределить эффект одного космического луча, потенциально нарушающего множество физически соседние биты в нескольких словах путем связывания соседних битов с разными словами. До тех пор, пока нарушение единичного события (SEU) не превышает пороговое значение ошибки (например, одиночная ошибка) в любом конкретном слове между доступами, оно может быть исправлено (например, путем исправления однобитовой ошибки code), и может сохраняться иллюзия безошибочной системы памяти.
Помимо оборудования, обеспечивающего функции, необходимые для работы памяти ECC, операционные системы обычно содержат соответствующие средства отчетности, которые используются для предоставления уведомлений при прозрачном восстановлении программных ошибок. Увеличение количества программных ошибок может указывать на то, что модуль DIMM нуждается в замене, и такая обратная связь не была бы легко доступна без соответствующих возможностей отчетности. Одним из примеров является подсистема EDAC ядра Linux (ранее известная как Bluesmoke), которая собирает данные из компонентов компьютерной системы, поддерживающих проверку ошибок; Помимо сбора и отправки отчетов о событиях, связанных с памятью ECC, он также поддерживает другие ошибки контрольного суммирования, в том числе обнаруженные на шине PCI.
Некоторые системы также поддерживают очистку памяти.
Дополнительная литература
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Виды ошибок
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Методы отладки программного обеспечения
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
Метод индукции
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:
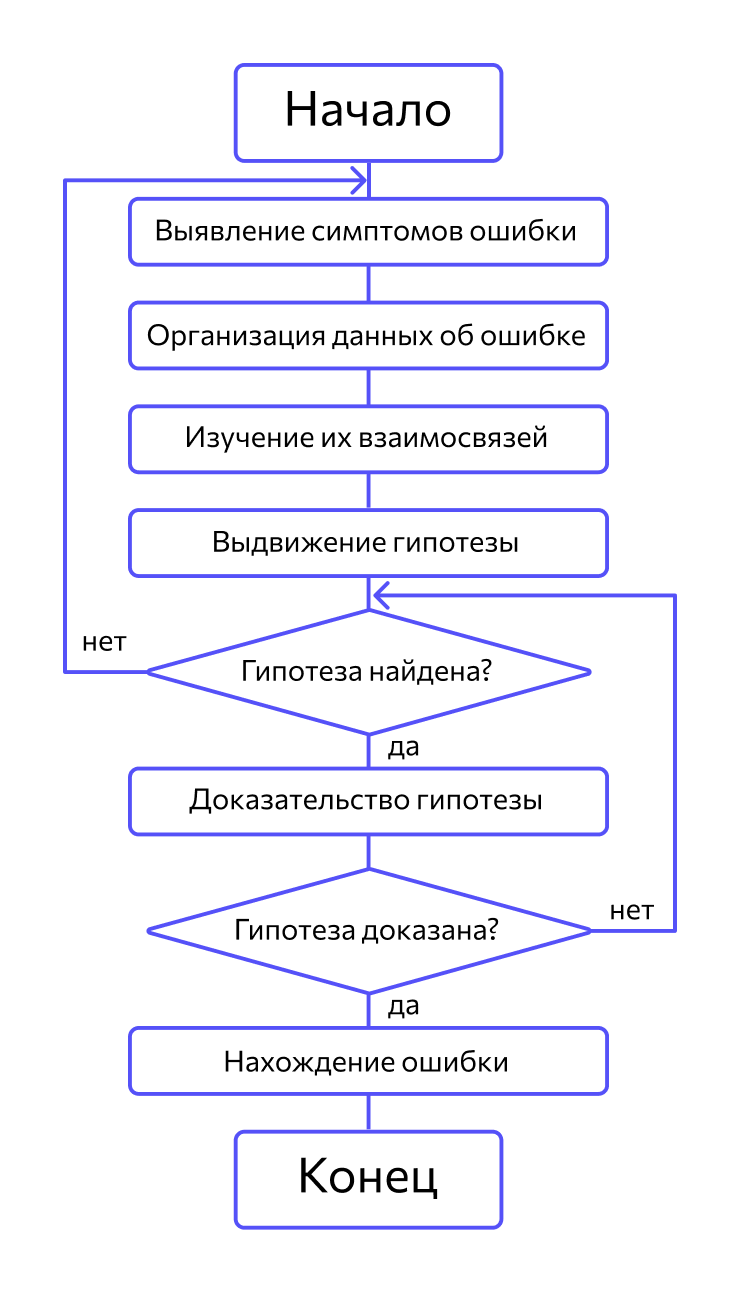
Алгоритм отладки по методу индукции
Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Метод дедукции
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.
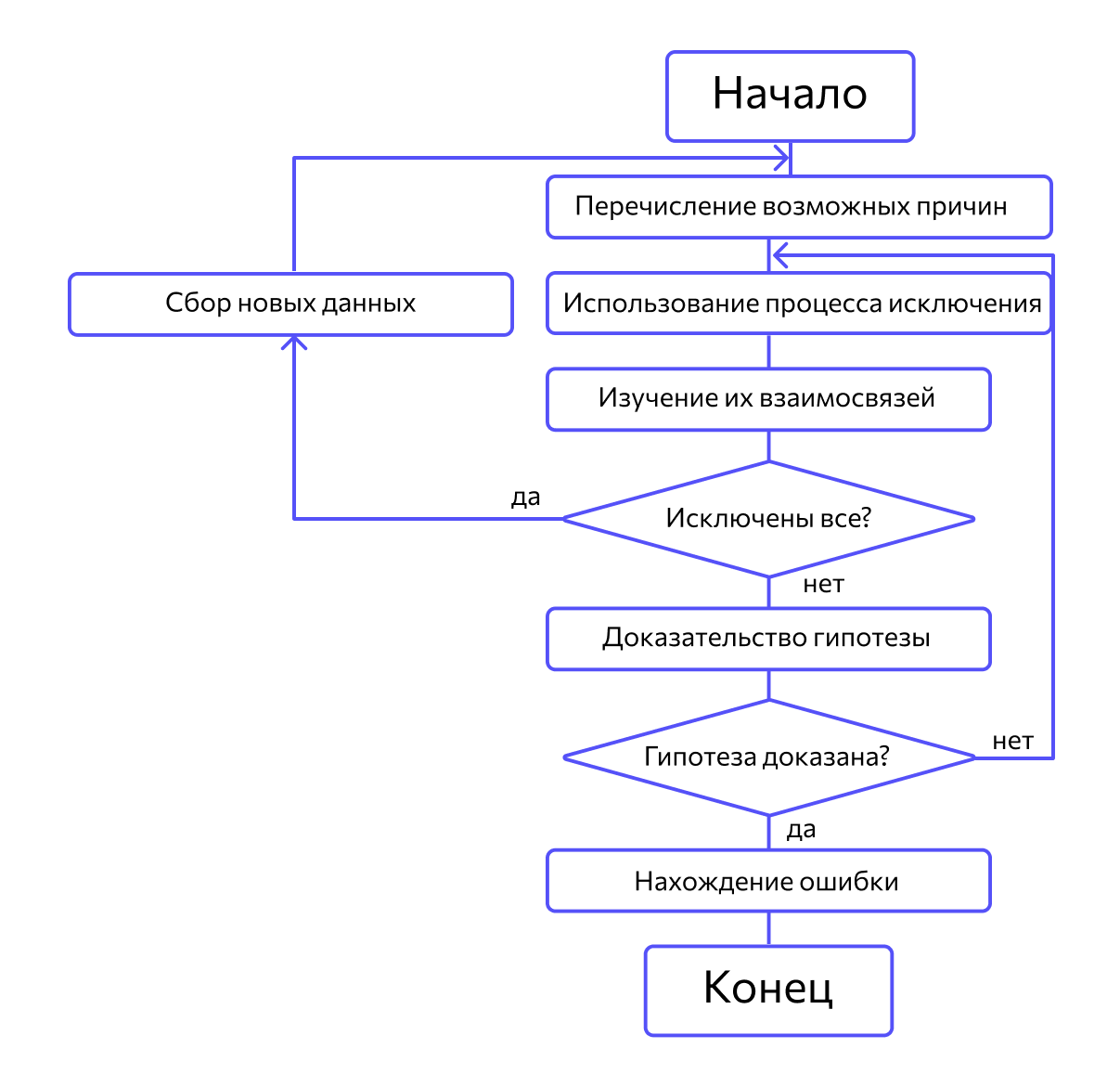
Отладка по методу дедукции
Метод обратного прослеживания
Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Как выполняется отладка в современных IDE
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Шаг с заходом (step into)
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Шаг с обходом (step over)
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
Шаг с выходом (step out)
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Автоматическое исправление ошибок — это автоматическое исправление ошибок программного обеспечения без вмешательства человека-программиста. Это также обычно называют автоматическим генерированием исправлений, автоматическим исправлением ошибок или автоматическим исправлением программ. Типичная цель таких методов — автоматически генерировать правильные исправления для устранения ошибок в программах, не вызывая регрессию программного обеспечения.
Спецификация
Автоматическое исправление ошибок выполняется в соответствии со спецификацией ожидаемого поведения, которая может быть, например, формальной спецификацией или набором тестов.
Набор тестов — пары ввода / вывода определяют функциональность программы, возможно, зафиксированную в , утверждения могут использоваться как тестовый оракул для управления поиском. Фактически, этот оракул можно разделить между оракулом ошибок, который выявляет ошибочное поведение, и оракулом регрессии, который инкапсулирует функциональность, которую должен сохранить любой метод восстановления программы. Обратите внимание, что набор тестов обычно неполный и не охватывает все возможные случаи. Следовательно, проверенный патч часто может выдавать ожидаемые выходные данные для всех входных данных в наборе тестов, но неправильные выходные данные для других входных данных. Существование таких проверенных, но некорректных исправлений является серьезной проблемой для методов генерации и проверки. Недавние успешные методы автоматического исправления ошибок часто полагаются на дополнительную информацию, отличную от набора тестов, такую как информация, полученная из предыдущих исправлений, выполненных человеком, для дальнейшего выявления правильных исправлений среди проверенных исправлений.
Другой способ указать ожидаемое поведение — это использовать формальные спецификации Проверка на соответствие полным спецификациям, которые определяют поведение всей программы, включая функциональные возможности, менее распространена, потому что такие спецификации обычно недоступны на практике, а стоимость вычислений такой проверки является непомерно высокой. Однако для определенных классов ошибок часто доступны неявные частичные спецификации. Например, существуют целевые методы исправления ошибок, подтверждающие, что исправленная программа больше не может вызывать ошибки переполнения в том же пути выполнения.
Подходы генерации и проверки компилируют и тестируют каждый патч-кандидат для сбора всех проверенных патчей, которые дают ожидаемые результаты для всех входных данных в наборе тестов. Такой метод обычно начинается с набора тестов программы, т. Е. Набора из тестовых случаев, по крайней мере один из которых выявляет ошибку. GenProg — одна из первых систем генерации и проверки ошибок. Эффективность методов генерации и-Validate остается спорным, так как они обычно не обеспечивают патч корректности гарантии. Тем не менее, опубликованные результаты новейших современных методов в целом обнадеживают. Например, для систематически собранных 69 реальных ошибок в восьми крупных программах на языке C современная система исправления ошибок Prophet генерирует правильные исправления для 18 из 69 ошибок.
Один способ исправить генерировать патчи-кандидаты — применить операторы мутации к исходной программе. Операторы мутации манипулируют исходной программой, возможно, через ее представление абстрактного синтаксического дерева или более грубое представление, такое как работа на уровне инструкции или блоке -уровень. Более ранние подходы к генетическому усовершенствованию работают на уровне операторов и выполняют простые операции удаления / замены, такие как удаление существующего оператора или замена существующего оператора другим оператором в том же исходном файле. В последних подходах используются более мелкие операторы на уровне абстрактного синтаксического дерева для создания более разнообразного набора исправлений-кандидатов.
Другой способ создания исправлений-кандидатов состоит в использовании шаблонов исправлений. Шаблоны исправлений обычно представляют собой предварительно определенные изменения для исправления определенных классов ошибок. Примеры шаблонов исправлений включают вставку условного оператора , чтобы проверить, является ли значение переменной нулевым, чтобы исправить исключение нулевого указателя, или изменение целочисленной константы на единицу, чтобы исправить отдельные ошибки. Также возможно автоматическое извлечение шаблонов исправлений для подходов генерации и проверки.
Многие методы генерации и проверки полагаются на понимание избыточности: код исправления можно найти в другом месте приложения. Эта идея была представлена в системе Genprog, где два оператора, добавление и замена узлов AST, были основаны на коде, взятом из другого места (то есть добавлении существующего узла AST). Эта идея была подтверждена эмпирически двумя независимыми исследованиями, которые показали, что значительная часть коммитов (3–17%) состоит из существующего кода. Помимо того факта, что код для повторного использования существует где-то еще, также было показано, что контекст потенциальных ингредиентов для восстановления полезен: часто контекст донора аналогичен контексту получателя.
На основе синтеза
Существуют техники ремонта, основанные на символическом исполнении. Например, Semfix использует символьное выполнение для извлечения исправления ограничения. Анжеликс ввел концепцию ангельского леса, чтобы иметь дело с многострочными патчами.
При определенных предположениях проблему ремонта можно сформулировать как проблему синтеза. SemFix и Nopol используют компонентный синтез. Dynamoth использует динамический синтез. S3 основан на синтаксическом синтезе. SearchRepair преобразует потенциальные исправления в формулу SMT и запрашивает исправления-кандидаты, которые позволяют пропатченной программе пройти все предоставленные тестовые примеры.
Управляемые данными
методы машинного обучения могут повысить эффективность систем автоматического исправления ошибок. Один из примеров таких методов основан на прошлых успешных исправлениях от разработчиков-людей, собранных из репозиториев с открытым исходным кодом в GitHub и SourceForge. Затем он использует полученную информацию для распознавания и определения приоритета потенциально правильных исправлений среди всех сгенерированных исправлений-кандидатов. Как вариант, патчи можно добывать напрямую из существующих источников. Примеры подходов включают добычу патчей из донорских приложений или с веб-сайтов QA.
SequenceR использует последовательное обучение в исходном коде для создания однострочных патчей. Он определяет архитектуру нейронной сети, которая хорошо работает с исходным кодом, с механизмом копирования, который позволяет создавать патчи с токенами, которых нет в изученном словаре. Эти токены взяты из кода ремонтируемого класса Java.
Другое
Целевые методы автоматического исправления ошибок генерируют исправления для определенных классов ошибок, таких как исключение нулевого указателя целочисленное переполнение, буфер переполнение, утечка памяти и т. д. Такие методы часто используют шаблоны эмпирических исправлений для исправления ошибок в целевой области. Например, вставьте условный оператор , чтобы проверить, является ли значение переменной нулевым, или вставьте отсутствующие операторы освобождения памяти. По сравнению с методами генерации и проверки, целевые методы, как правило, имеют лучшую точность исправления ошибок, но значительно сужены.
Использование
Существует несколько вариантов использования автоматического исправления ошибок:
- в среде разработки: когда разработчик обнаруживает ошибку, она активирует функцию для поиска патча (например, нажав кнопку). Этот поиск может даже происходить в фоновом режиме, когда IDE упреждающе ищет решения потенциальных проблем, не дожидаясь явных действий разработчика.
- на сервере непрерывной интеграции: при сбое сборки во время непрерывного поиска исправлений можно попытаться выполнить, как только сборка не удалась. Если поиск успешен, патч передается разработчику до того, как она начнет работу над ним или до того, как она найдет решение. Когда синтезированный патч предлагается разработчикам в качестве запроса на вытягивание, помимо изменений кода должно быть предоставлено объяснение (например, заголовок и описание запроса на извлечение). Эксперимент показал, что сгенерированные исправления могут быть приняты разработчиками с открытым исходным кодом и объединены в репозиторий кода.
- во время выполнения: когда сбой происходит во время выполнения, можно выполнить поиск двоичного исправления и применить онлайн. Примером такой системы восстановления является ClearView, которая выполняет восстановление кода x86 с помощью двоичных исправлений x86. Система Itzal отличается от Clearview: в то время как поиск исправлений происходит во время выполнения, в производственной среде производимые исправления находятся на уровне исходного кода. Система BikiniProxy выполняет оперативное исправление ошибок Javascript, возникающих в браузере.
Область поиска
По сути, автоматическое исправление ошибок — это поисковая деятельность, основанная на дедуктивных или эвристических методах. Область поиска автоматического исправления ошибок состоит из всех изменений, которые могут быть внесены в программу. Были проведены исследования, чтобы понять структуру этого поискового пространства. Qi et al. показал, что исходная фитнес-функция Genprog не лучше случайного поиска для управления поиском. Martinez et al. исследовал дисбаланс между возможными ремонтными действиями, показав его значительное влияние на поиск. Исследование Лонга и др. Показало, что правильные участки могут считаться редкими в пространстве поиска и что неправильных участков с переобучением гораздо больше (см. Также обсуждение переобучения ниже).
Если явно перечислить все возможные варианты в алгоритме восстановления, это определяет пространство разработки для восстановления программы. Каждый вариант выбирает алгоритм, задействованный в какой-то момент в процессе исправления (например, алгоритм локализации неисправности), или выбирает конкретную эвристику, которая дает разные исправления. Например, в области проектирования восстановления программы с помощью генерации и проверки существует одна точка вариации в отношении степени детализации изменяемых элементов программы: выражение, оператор, блок и т. Д.
Ограничения автоматического исправления ошибок
Методы автоматического исправления ошибок, основанные на наборе тестов, не обеспечивают гарантии правильности исправлений, поскольку набор тестов является неполным и не охватывает все случаи. Слабый набор тестов может привести к тому, что методы генерации и проверки будут создавать проверенные, но неправильные исправления, которые имеют негативные последствия, такие как устранение желаемых функций, вызывая утечки памяти и вводя уязвимости безопасности. Один из возможных подходов состоит в том, чтобы расширить набор тестов, которые не прошли проверку, путем автоматической генерации дополнительных тестовых примеров, которые затем помечаются как пройденные или не выполненные. Чтобы свести к минимуму усилия человека по присвоению ярлыков, можно обучить автоматический тестовый оракул, который постепенно учится автоматически классифицировать тестовые случаи как пройденные или неуспешные и вовлекающий пользователя, сообщающего об ошибках, только в неопределенных случаях. Иногда при ремонте программ на основе набора тестов инструменты генерируют исправления, которые проходят набор тестов, но на самом деле являются некорректными, это называется проблемой «переобучения». «Переобучение» в этом контексте относится к тому факту, что патч переоснащается тестовым входам. Существуют различные виды переобучения: неполное исправление означает, что исправлены только некоторые ошибочные входные данные, введение регрессии означает, что некоторые ранее работавшие функции нарушены после исправления (потому что они были плохо протестированы). Ранние прототипы для автоматического ремонта сильно страдали от переоснащения: в тесте Manybugs C Qi et al. сообщил, что 104/110 вероятных патчей GenProg переоснащены; по тесту Java Defects4J Мартинес и др. сообщили, что 73/84 правдоподобных исправлений переобучены. В контексте репарации на основе синтеза Le et al. получено более 80% исправлений переобучения.
Еще одно ограничение систем генерации и проверки — это взрывное пространство поиска. Для программы необходимо изменить большое количество операторов, и для каждого оператора существует большое количество возможных модификаций. Современные системы решают эту проблему, предполагая, что для исправления ошибки достаточно небольшой модификации, что приводит к сокращению пространства поиска.
Ограничение подходов, основанных на символьном анализе, состоит в том, что программы реального мира часто преобразуются в трудноразрешимые большие формулы, особенно для модификации операторов с побочными эффектами.
Тесты
Тесты ошибок обычно сосредоточиться на одном конкретном языке программирования. В языке C тест Manybugs, собранный авторами GenProg, содержит 69 реальных дефектов и широко используется для оценки многих других инструментов исправления ошибок для C.
В Java основным тестом является Defects4J, первоначально исследованный Мартинесом. et al., и в настоящее время широко используется в большинстве исследовательских работ по восстановлению программ для Java. Существуют альтернативные тесты, такие как тест Quixbugs, который содержит оригинальные ошибки для исправления программ. Другие тесты ошибок Java включают Bugs.jar, основанные на прошлых коммитах, и BEARS, который является эталоном сбоев при непрерывной интеграции.
Примеры инструментов
Автоматическое исправление ошибок — активная тема исследований в области компьютерных наук. Существует множество реализаций различных методов исправления ошибок, особенно для программ C и Java. Обратите внимание, что большинство из этих реализаций являются исследовательскими прототипами для демонстрации своих методов, то есть неясно, готовы ли их текущие реализации для промышленного использования или нет.
- ClearView: инструмент для создания и проверки бинарных исправлений для развернутых систем. Он оценивается по 10 случаям уязвимости безопасности. Более позднее исследование показывает, что он генерирует правильные исправления как минимум для 4 из 10 случаев.
- GenProg: оригинальный инструмент для создания и проверки ошибок. Он был тщательно изучен в контексте теста ManyBugs.
- SemFix: первый инструмент для исправления ошибок на основе решателя для C.
- CodePhage: первый инструмент для исправления ошибок, который напрямую передает код в программах для создания патча для программы C. Обратите внимание, что хотя он генерирует исправления C, он может извлекать код из двоичных программ без исходного кода.
- LeakFix: инструмент, который автоматически устраняет утечки памяти в программах на C.
- Prophet: Первый инструмент генерации и проверки, использующий методы машинного обучения для извлечения полезных знаний из прошлых человеческих патчей и распознавания правильных патчей. Он оценивается на том же тесте, что и GenProg, и генерирует правильные исправления (т. Е. Эквивалентные человеческим исправлениям) в 18 из 69 случаев.
- SearchRepair: инструмент для замены ошибочного кода с помощью фрагментов кода из других источников. Он оценивается в тесте IntroClass и генерирует исправления гораздо более высокого качества в этом тесте, чем GenProg, RSRepair и AE.
- Angelix: улучшенный инструмент для исправления ошибок на основе решателя. Он оценивается на тесте GenProg. В 10 из 69 случаев он генерирует заплатки, которые эквивалентны человеческим.
- Learn2Fix: первый полуавтоматический инструмент для исправления ошибок. Расширяет GenProg для изучения условий, при которых наблюдается семантическая ошибка, путем систематических запросов к пользователю, сообщающему об ошибке. Работает только для программ, которые принимают и производят целые числа.
Java
- PAR: инструмент создания и проверки, использующий набор вручную определенных шаблонов исправлений. В более позднем исследовании высказывались опасения по поводу возможности обобщения шаблонов исправлений в PAR.
- NOPOL: инструмент на основе решателя, ориентированный на изменение операторов условий.
- QACrashFix: инструмент, который исправляет ошибки сбоя Java путем исправления майнинга с веб-сайта вопросов и ответов.
- Astor: библиотека автоматического восстановления для Java, содержащая jGenProg, Java-реализацию GenProg.
- NpeFix: инструмент автоматического восстановления для NullPointerException в Java, доступен на Github.