 — Основы JavaScript")
Рассмотрим популярные инструменты для анализа кода Python и подробно расскажем об их специфике и основных принципах работы.

Автор: Валерий Шагур, teacher assistance на курсе Программирование на Python
Высокая стоимость ошибок в программных продуктах предъявляет повышенные
требования к качеству кода. Каким критериям должен соответствовать хороший код?
Отсутствие ошибок, расширяемость, поддерживаемость, читаемость и наличие документации. Недостаточное внимание к любому из этих критериев может привести к появлению новых ошибок или снизить вероятность обнаружения уже существующих. Небрежно написанный или чересчур запутанный код, отсутствие документации напрямую влияют на время исправления найденного бага, ведь разработчику приходится заново вникать в код. Даже такие, казалось бы, незначительные вещи как неправильные имена переменных или отсутствие форматирования могут сильно влиять на читаемость и понимание кода.
Командная работа над проектом еще больше повышает требования к качеству кода, поэтому важным условием продуктивной работы команды становится описание формальных требований к написанию кода. Это могут быть соглашения, принятые в языке программирования, на котором ведется разработка, или собственное (внутрикорпоративное) руководство по стилю. Выработанные требования к оформлению кода не исключают появления «разночтений» среди разработчиков и временных затрат на их обсуждение. Кроме этого, соблюдение выработанных требований ложится на плечи программистов в виде дополнительной нагрузки. Все это привело к появлению инструментов для проверки кода на наличие стилистических и логических ошибок. О таких инструментах для языка программирования Python мы и поговорим в этой статье.
Анализаторы и автоматическое форматирование кода
Весь инструментарий, доступный разработчикам Python, можно условно разделить на две группы по способу реагирования на ошибки. Первая группа сообщает о найденных ошибках, перекладывая задачу по их исправлению на программиста. Вторая — предлагает пользователю вариант исправленного кода или автоматически вносит изменения.
И первая, и вторая группы включают в себя как простые утилиты командной строки для решения узкоспециализированных задач (например, проверка docstring или сортировка импортов), так и богатые по возможностям библиотеки, объединяющие в себе более простые утилиты. Средства анализа кода из первой группы принято называть линтерами (linter). Название происходит от lint — статического анализатора для языка программирования Си и со временем ставшего нарицательным. Программы второй группы называют форматировщиками (formatter).
Даже при поверхностном сравнении этих групп видны особенности работы с ними. При применении линтеров программисту, во-первых, необходимо писать код с оглядкой, дабы позже не исправлять найденные ошибки. И во вторых, принимать решение по поводу обнаруженных ошибок — какие требуют исправления, а какие можно проигнорировать. Форматировщики, напротив, автоматизируют процесс исправления ошибок, оставляя программисту возможность осуществлять контроль.
Часть 1
Часть 2
Соглашения принятые в статье и общие замечания
Прежде чем приступить к обзору программ, мы хотели бы обратить ваше внимание на несколько важных моментов.
Версия Python: во всех примерах, приведенных в статье, будет использоваться третья версия языка программирования Python.
Установка всех программ в обзоре практически однотипна и сводится к использованию пакетного менеджера pip.
$ python3.6 -m pip install --upgrade
Некоторые из библиотек имеют готовые бинарные пакеты в репозиториях дистрибутивов linux или возможность установки с использованием git. Тем не менее для большей определенности и возможности повторения примеров из статьи, установка будет производится с помощью pip.
Об ошибках: стоит упомянуть, что говоря об ошибках, обнаруживаемых анализаторами кода, как правило, имеют в виду два типа ошибок. К первому относятся ошибки стиля (неправильные отступы, длинные строки), ко второму — ошибки в логике программы и ошибки синтаксиса языка программирования (опечатки при написании названий стандартных функций, неиспользуемые импорты, дублирование кода). Существуют и другие виды ошибок, например — оставленные в коде пароли или высокая цикломатическая сложность.
Тестовый скрипт: для примеров использования программ мы создали простенький по содержанию файл example.py. Мы сознательно не стали делать его более разнообразным по наличию в нем ошибок. Во-первых, добавление листингов с выводом некоторых анализаторов в таком случае сильно “раздуло” бы статью. Во-вторых, у нас не было цели детально показать различия в “отлове” тех или иных ошибок для каждой из утилит.
Содержание файла example.py:
import os
import notexistmodule
def Function(num,num_two):
return num
class MyClass:
"""class MyClass """
def __init__(self,var):
self.var=var
def out(var):
print(var)
if __name__ == "__main__":
my_class = MyClass("var")
my_class.out("var")
notexistmodule.func(5)
В коде допущено несколько ошибок:
- импорт неиспользуемого модуля os,
- импорт не существующего модуля notexistmodule,
- имя функции начинается с заглавной буквы,
- лишние аргументы в определении функции,
- отсутствие self первым аргументом в методе класса,
- неверное форматирование.
Руководства по стилям: для тех, кто впервые сталкивается с темой оформления кода, в качестве знакомства предлагаем прочитать официальные руководства по стилю для языка Python PEP8 и PEP257. В качестве примера внутрикорпоративных соглашений можно рассмотреть Google Python Style Guide — https://github.com/google/styleguide/blob/gh-pages/pyguide.md
Pycodestyle
Pycodestyle — простая консольная утилита для анализа кода Python, а именно для проверки кода на соответствие PEP8. Один из старейших анализаторов кода, до 2016 года носил название pep8, но был переименован по просьбе создателя языка Python Гвидо ван Россума.
Запустим проверку на нашем коде:
$ python3 -m pycodestyle example.py example.py:4:1: E302 expected 2 blank lines, found 1 example.py:4:17: E231 missing whitespace after ',' example.py:7:1: E302 expected 2 blank lines, found 1 example.py:10:22: E231 missing whitespace after ',' example.py:11:17: E225 missing whitespace around operator
Лаконичный вывод показывает нам строки, в которых, по мнению анализатора, есть нарушение соглашений PEP8. Формат вывода прост и содержит только необходимую информацию:
<имя файла>: <номер строки> :<положение символа>: <код и короткая расшифровка ошибки>
Возможности программы по проверке соглашений ограничены: нет проверок на правильность именования, проверка документации сводится к проверки длины docstring. Тем не менее функционал программы нельзя назвать “спартанским”, он позволяет настроить необходимый уровень проверок и получить различную информацию о результатах анализа. Запуск с ключом —statistics -qq выводит статистику по ошибкам:
$ python3 -m pycodestyle --statistics -qq example.py 1 E225 missing whitespace around operator 2 E231 missing whitespace after ',' 2 E302 expected 2 blank lines, found 1
Более наглядный вывод можно получить при использовании ключа —show-source. После каждого сообщения об ошибке будет выведена строка исходного кода, в которой содержится ошибка.
$ python3 -m pycodestyle --show-source example.py example.py:4:1: E302 expected 2 blank lines, found 1 def Function(num,num_two): ^ example.py:4:17: E231 missing whitespace after ',' def Function(num,num_two): ^ example.py:7:1: E302 expected 2 blank lines, found 1 class MyClass: ^ example.py:10:22: E231 missing whitespace after ',' def __init__(self,var): ^ example.py:11:17: E225 missing whitespace around operator self.var=var ^
Если есть необходимость посмотреть, какие из соглашений PEP8 были нарушены, используйте ключ — show-pep8. Программа выведет список всех проверок с выдержками из PEP8 для случаев нарушений. При обработке файлов внутри директорий предусмотрена возможность фильтрации по шаблону. Pycodestyle позволяет сохранять настройки поиска в конфигурационных файлах как глобально, так и на уровне проекта.
Pydocstyle
Утилиту pydocstyle мы уже упоминали в статье Работа с документацией в Python: поиск информации и соглашения. Pydocstyle проверяет наличие docstring у модулей, классов, функций и их соответствие официальному соглашению PEP257.
$ python3 -m pydocstyle example.py example.py:1 at module level: D100: Missing docstring in public module example.py:4 in public function `Function`: D103: Missing docstring in public function example.py:7 in public class `MyClass`: D400: First line should end with a period (not 's') example.py:7 in public class `MyClass`: D210: No whitespaces allowed surrounding docstring text example.py:10 in public method `__init__`: D107: Missing docstring in __init__ example.py:13 in public method `out`: D102: Missing docstring in public method
Как мы видим из листинга, программа указала нам на отсутствие документации в определениях функции, методов класса и ошибки оформления в docstring класса. Вывод можно сделать более информативным, если использовать ключи —explain и —source при вызове программы. Функционал pydocstyle практически идентичен описанному выше для pycodestyle, различия касаются лишь названий ключей.
Pyflakes
В отличие от уже рассмотренных инструментов для анализа кода Python pyflakes не делает проверок стиля. Цель этого анализатора кода — поиск логических и синтаксических ошибок. Разработчики pyflakes сделали упор на скорость работы программы, безопасность и простоту. Несмотря на то, что данная утилита не импортирует проверяемый файл, она прекрасно справляется c поиском синтаксических ошибок и делает это быстро. С другой стороны, такой подход сильно сужает область проверок.
Функциональность pyflakes — “нулевая”, все что он умеет делать — это выводить результаты анализа в консоль:
$ python3 -m pyflakes example.py example.py:1: 'os' imported but unused
В нашем тестовом скрипте, он нашел только импорт не используемого модуля os. Вы можете самостоятельно поэкспериментировать с запуском программы и передачей ей в качестве параметра командной строки Python файла, содержащего синтаксические ошибки. Данная утилита имеет еще одну особенность — если вы используете обе версии Python, вам придется установить отдельные утилиты для каждой из версий.
Pylint
До сих пор мы рассматривали утилиты, которые проводили проверки на наличие либо стилистических, либо логических ошибок. Следующий в обзоре статический инструмент для анализа кода Python — Pylint, который совместил в себе обе возможности. Этот мощный, гибко настраиваемый инструмент для анализа кода Python отличается большим количеством проверок и разнообразием отчетов. Это один из самых “придирчивых” и “многословных” анализаторов кода. Анализ нашего тестового скрипта выдает весьма обширный отчет, состоящий из списка найденных в ходе анализа недочетов, статистических отчетов, представленных в виде таблиц, и общей оценки кода:
$ python3.6 -m pylint --reports=y text example.py
************* Module text
/home/ququshka77/.local/lib/python3.6/site-packages/pylint/reporters/text.py:79:22: W0212: Access to a protected member _splitstrip of a client class (protected-access)
************* Module example
example.py:4:16: C0326: Exactly one space required after comma
def Function(num,num_two):
^ (bad-whitespace)
example.py:10:21: C0326: Exactly one space required after comma
def __init__(self,var):
^ (bad-whitespace)
example.py:11:16: C0326: Exactly one space required around assignment
self.var=var
^ (bad-whitespace)
example.py:1:0: C0111: Missing module docstring (missing-docstring)
example.py:2:0: E0401: Unable to import 'notexistmodule' (import-error)
example.py:4:0: C0103: Function name "Function" doesn't conform to snake_case naming style (invalid-name)
example.py:4:0: C0111: Missing function docstring (missing-docstring)
example.py:4:17: W0613: Unused argument 'num_two' (unused-argument)
example.py:13:4: C0111: Missing method docstring (missing-docstring)
example.py:13:4: E0213: Method should have "self" as first argument (no-self-argument)
example.py:7:0: R0903: Too few public methods (1/2) (too-few-public-methods)
example.py:18:4: C0103: Constant name "my_class" doesn't conform to UPPER_CASE naming style (invalid-name)
example.py:19:4: E1121: Too many positional arguments for method call (too-many-function-args)
example.py:1:0: W0611: Unused import os (unused-import)
Report
======
112 statements analysed.
Statistics by type
+----------+----------+---------------+-------------+-------------------+---------------+
|type |number |old number |difference |%documented |%badname |
+======+======+========+========+===========+========+
|module |2 |2 |= |50.00 |0.00 |
+-----------+----------+---------------+-------------+-------------------+---------------+
|class |5 |5 |= |100.00 |0.00 |
+-----------+----------+---------------+-------------+-------------------+---------------+
|method |11 |11 |= |90.91 |0.00 |
+-----------+----------+---------------+-------------+-------------------+---------------+
|function |4 |4 |= |75.00 |25.00 |
+-----------+----------+---------------+-------------+-------------------+---------------+
External dependencies
::
pylint
\-interfaces (text)
\-reporters (text)
| \-ureports
| \-text_writer (text)
\-utils (text)
Raw metrics
+-------------+----------+-------+-----------+-------------+
|type |number |% |previous |difference |
+=======+======+=====+=====+========+
|code |128 |48.30 |128 |= |
+-------------+----------+--------+-----------+------------+
|docstring |84 |31.70 |84 |= |
+-------------+----------+--------+-----------+------------+
|comment |16 |6.04 |16 |= |
+-------------+----------+--------+-----------+------------+
|empty |37 |13.96 |37 |= |
+-------------+----------+--------+-----------+------------+
Duplication
+-------------------------------+------+------------+-------------+
| |now |previous |difference |
+=================+=====+======+========+
|nb duplicated lines |0 |0 |= |
+-------------------------------+-------+------------+------------+
|percent duplicated lines |0.000 |0.000 |= |
+-------------------------------+-------+------------+------------+
Messages by category
+--------------+----------+-----------+-------------+
|type |number |previous |difference |
+========+======+======+========+
|convention |8 |8 |= |
+--------------+----------+-----------+-------------+
|refactor |1 |1 |= |
+--------------+-----------+----------+-------------+
|warning |3 |3 |= |
+--------------+-----------+----------+-------------+
|error |3 |3 |= |
+--------------+-----------+----------+-------------+
% errors / warnings by module
+-----------+--------+-----------+----------+--------------+
|module |error |warning |refactor |convention |
+======+=====+======+======+========+
|example |100.00 |66.67 |100.00 |100.00 |
+-----------+---------+----------+-----------+-------------+
|text |0.00 |33.33 |0.00 |0.00 |
+-----------+---------+----------+-----------+-------------+
Messages
+-----------------------------+----------------+
|message id |occurrences |
+=================+=========+
|missing-docstring |3 |
+-----------------------------+----------------+
|bad-whitespace |3 |
+------------------------------+---------------+
|invalid-name |2 |
+------------------------------+---------------+
|unused-import |1 |
+------------------------------+---------------+
|unused-argument |1 |
+------------------------------+---------------+
|too-many-function-args |1 |
+------------------------------+---------------+
|too-few-public-methods |1 |
+------------------------------+---------------+
|protected-access |1 |
+------------------------------+---------------+
|no-self-argument |1 |
+------------------------------+---------------+
|import-error |1 |
+------------------------------+---------------+
------------------------------------------------------------------------------------------
Your code has been rated at 7.59/10 (previous run: 7.59/10, +0.00)
Программа имеет свою внутреннюю маркировку проблемных мест в коде:
Для вывода подробного отчета мы использовали ключ командной строки —reports=y.
Более гибко настроить вывод команды позволяют разнообразные ключи командной строки. Настройки можно сохранять в файле настроек rcfile. Мы не будем приводить подробное описание ключей и настроек, для этого есть официальная документация — https://pylint.readthedocs.io/en/latest/index.html#, остановимся лишь на наиболее интересных, с нашей точки зрения, возможностях утилиты:
— Генерация файла настроек (—generate-rcfile). Позволяет не писать конфигурационный файл с нуля. В созданном rcfile содержатся все текущие настройки с подробными комментариями к ним, вам остается только отредактировать его под собственные требования.
# pylint: disable=unused-argument
и запустим pylint. Из результатов проверки “исчезло” сообщение:
example.py:4:17: W0613: Unused argument 'num_two' (unused-argument)
— Создание отчетов в формате json (—output-format=json). Полезно, если необходимо сохранение или дальнейшая обработка результатов работы линтера. Вы также можете создать собственный формат вывода данных.
— Параллельный запуск (-j 4). Запуск в нескольких параллельных потоках на многоядерных процессорах сокращает время проверки.
— Встроенная документация. Вызов программы с ключом —help-msg=
$ python3.6 -m pylint --help-msg=import-error :import-error (E0401): *Unable to import %s* Used when pylint has been unable to import a module. This message belongs to the imports checker.
— Система оценки сохраняет последний результат и при последующих запусках показывает изменения, что позволяет количественно оценить прогресс исправлений.
— Плагины — отличная возможность изменять поведение pylint. Их применение может оказаться полезным в случаях, когда pylint неправильно обрабатывает код и есть “ложные” срабатывания, или когда требуется отличный от стандартного формат вывода результатов.
Vulture
Vulture — небольшая утилита для поиска “мертвого” кода в программах Python. Она использует модуль ast стандартной библиотеки и создает абстрактные синтаксические деревья для всех файлов исходного кода в проекте. Далее осуществляется поиск всех объектов, которые были определены, но не используются. Vulture полезно применять для очистки и нахождения ошибок в больших базовых кодах.
Продолжение следует
Во второй части мы продолжим разговор об инструментах для анализа кода Python. Будут рассмотрены линтеры, представляющие собой наборы утилит. Также мы посмотрим, какие программы можно использовать для автоматического форматирования кода.
Еще статьи по Python
Введение
В данной статье рассказывается о простом алгоритме поиска ошибок в коде . Часто после написания
программы возникают проблемы при компиляции, вызванные ошибками в коде. Это
могут быть самые различные ошибки, но в любом случае возникает необходимость
оперативного обнаружения участка кода, где допущена ошибка.
Нередко у людей уходит немало времени и масса нервов на поиски какой-нибудь
лишней скобки. Однако есть способ быстрого обнаружения ошибок, который основан
на использовании комментирования. Об этом методе я и расскажу в данной статье.
Концепция
Написать достаточно большой код без единой ошибки – весьма приятно. Но, к
сожалению, так выходит не всегда. Есть даже шутка, что ни одна программа не
была написана без единой ошибки. Я не рассматриваю здесь ошибки, которые
приводят к неверному исполнению кода. Здесь пойдёт речь об ошибках, из-за
которых становится невозможной компиляция.
Весьма распространённые ошибки – вставка лишней скобки в сложном условии,
нехватка скобки, не выставление двоеточия, запятой (при объявлении переменных)
и т.д. Часто при компиляции мы можем сразу увидеть, в какой строке допущена
подобная ошибка. Но бывают и случаи, когда найти такую ошибку не так просто. Ни
компилятор, ни зоркий глаз нам не могут помочь сходу найти ошибку. В
таких случаях, как правило, начинающие (и не очень) программисты начинают
«обходить» весь код, пытаясь визуально определить ошибку. И снова, и
снова, пока нервы не иссякнут, и не будет сказано «проще заново написать!».
Однако , как и
другие языки программирования, предлагает потрясающий инструмент –
комментирование. Используя его можно «убирать», «отключать»
какие-то участки кода. Обычно комментирование используют именно для вставки
каких-то комментариев, или же отключения неиспользуемых участков кода. Комментирование
можно также успешно применять и при поиске ошибок.
Алгоритм поиска ошибок
Поиск ошибок обычно сводится к определению участка кода, где допущена
ошибка, а затем, в этом участке, визуально находится ошибка. Думаю, вряд ли кто-то
будет сомневаться в том, что исследовать «на глаз» 5-10 строчек кода
проще и быстрей, чем 100-500.
При использовании комментирования задача предельно проста. Сначала
нужно закомментировать различные участки кода (иногда чуть ли не весь код), тем
самым «отключив» его. Затем, по очереди комментирование снимается с
этих участков кода. После очередного снятия комментирования совершается
попытка компиляции. Если компиляция прошла успешно – ошибка не в этом участке
кода. Затем открывается следующий участок кода и т.д. Когда находится проблемный
участок кода, визуально ищется ошибка, затем устраняется. Опять происходит попытка
компиляции. Если всё прошло успешно, — ошибка устранена.
В случае возникновения новых ошибок, процедура повторяется до
их устранения. Данный подход очень полезен при написании достаточно больших программ,
но и нередко оправдывает себя и при написании относительно небольших кодов.
Весьма важно правильно определять участки кода, которые необходимо
комментировать. Если это условие (или иная логическая конструкция) – то оно
должно комментироваться полно. Если комментируется участок кода, где
объявляются переменные, важно, чтобы не был открыт участок, где происходит
обращение к этим переменным. Иначе говоря, комментирование должно применяться
по логике программирования. Несоблюдения такого подхода приводит к
возникновению новых, вводящих в заблуждение, ошибок при компиляции.
Пример
Приведу пример практического поиска ошибки в коде. Допустим, у нас есть некоторый код:
Level1=;
Level2=;
Lots=;
TP=;
SL=;
Profit_stop=;
start()
{
pos_sell=;
( i_op_sell=()-; i_op_sell>=; i_op_sell--)
{
(!(i_op_sell,,)) ;
(()==()&&(()==||()==)&&(()==))
{
pos_sell=; ;
}
}
pos_buy=;
( i_op_buy=()-; i_op_buy>=; i_op_buy--)
{
(!(i_op_buy,,)) ;
(()==()&&(()==||()==)&&(()==))
{
pos_buy=; ;
}
}
stop_open;
( ia=()-; ia>=; ia--)
{
(!(ia,,)) ;
((()==)&&(()==())&&(()==))
{
stop_open=();
((,)-stop_open<=Profit_stop*) ;
((),(),()+*,(),(),CLR_NONE);
}
((()==)&&(()==())&&(()==))
{
stop_open=();
(stop_open-(,)<=Profit_stop*) ;
((),(),()-*,(),(),CLR_NONE);
}
}
i;
trend_UP=,trend_DOWN=;
(!pos_buy)
{
(i=Level1; i>=; i--)
{
([i]<(,,,,i))
{
trend_UP=; ;
}
}
(i=Level2*; i>=; i--)
{
(i>Level2)
{
((, , i+)<=(, , i))
{
trend_UP=; ;
}
}
(i=(, , i))
{
trend_UP=; ;
}
}
}
}
{
trend_UP=;
}
(!pos_sell)
{
(i=Level1; i>=; i--)
{
{
([i]>(,,,,i))
{
trend_DOWN=; ;
}
}
(i=Level2*; i>=; i--)
{
(i>Level2)
{
((, , i+)>=(, , i))
{
trend_DOWN=; ;
}
}
(i(,,,,))
{
();
}
([]<(,,,,))
{
();
}
MA_1;
MA_1=(,,,,,,,,);
(trend_UP && MA_1< && []<[] && !pos_buy && () != )
{
((),, Lots,,,-SL*,+TP*,,,,Blue);
(, , , [], );
(, , );
(, , );
(, , LightSeaGreen);
}
(trend_DOWN && MA_1> && []>[] && !pos_sell && () != )
{
((),, Lots,,,+SL*,-TP*,,,,Red);
(, , , [], );
(, , );
(, , );
(, , Red);
}
();
}
При попытке его компиляции мы видим сообщение об ошибке:
Оперативно определить участок кода, где допущена ошибка, не представляется
возможным. Прибегаем к комментированию. Комментируем все логические
конструкции:
Level1=;
Level2=;
Lots=;
TP=;
SL=;
Profit_stop=;
start()
{
MA_1;
MA_1=(,,,,,,,,);
();
}
Компиляция будет происходить благополучно, пока мы не дойдём до участка кода:
(!pos_sell)
{
(i=Level1; i>=; i--)
{
{
([i]>(,,,,i))
{
trend_DOWN=; ;
}
}
(i=Level2*; i>=; i--)
{
(i>Level2)
{
((, , i+)>=(, , i))
{
trend_DOWN=; ;
}
}
(i
Следовательно, ошибка именно в этой логической конструкции. При детальном «осмотре» данного участка кода, можно увидеть, что поставлена лишняя фигурная скобка в данной конструкции:
(i=Level1; i>=; i--)
{
{
([i]>(,,,,i))
{
trend_DOWN=; ;
}
}
Если убрать её, код благополучно откомпилируется.
Заключение
На практическом примере было показано, как именно используется данный алгоритм
поиска ошибок. В данном примере используется весьма немаленький код (194 строки),
и на его «обход» могло бы уйти достаточно много времени. Именно
возможность комментирования экономит достаточно много времени у многих
программистов, которые сталкиваются с задачей поиска ошибок.
Начните с просмотра видео, чтобы познакомиться с принципами эффективной отладки и избежать распространенных ошибок.
Также загляните в наш Твиттер. В одном треде мы разобрали несколько примеров, когда вроде бы рабочий код не проходит тесты на Хекслете. Сам тред можно найти здесь.
Примеры в этой статье написаны на языке JavaScript, но принципы одинаковы для любого языка.
Тесты
Код на Хекслете проверяется с помощью автоматических тестов. Обычно они написаны на том же языке, на котором написан сам код. Общий принцип работы такого вида тестирования довольно прост. Тестируемая программа загружается в память и вызывается с разными параметрами, а тесты следят за тем, чтобы ее поведение соответствовало ожидаемому.
Когда код не проходит тесты, то обычно говорят что тесты упали. В этот момент начинается самое интересное. Необходимо понять, где и почему возникла ошибка. И вывод тестов в этом процессе играет ключевую роль, это главный помощник и проводник. Но необходим опыт, чтобы начать делать правильные выводы из того, что пишут тесты.
В первую очередь нужно классифицировать проблему. Ошибки в тестах можно грубо разделить на две категории:
- ошибки, которые выдает компилятор или интерпретатор: синтаксическая ошибка, ошибка типизации
- ошибочные утверждения.
Утверждения
Утверждение — это специальная функция, которая вызывает ваш код с определенными параметрами и проверяет, что он возвращает ожидаемый результат. Например:
assert(isPrime(3));
assert.equal(factorial(3), 6);
Самое важное: если тесты упали на утверждении, это означает, что ваш код как минимум отработал, но его результат не соответствует ожидаемому. Причем часто бывает так, что часть утверждений проходит проверку, то есть код возвращает правильный результат, а часть — нет, обычно в пограничных случаях. В конечном итоге падение теста на утверждении говорит о том, что в коде логическая ошибка.
Ниже — пример вывода упавшего теста. То, насколько вывод подробный, зависит от вида утверждения и возможностей тестовой среды.
assert.js:89
throw new assert.AssertionError({
^
AssertionError: 3 == 1
at Object. (test.js:4:8)
at Module._compile (module.js:413:34)
at loader (/usr/local/lib/node_modules/babel-register/lib/node.js:126:5)
at Object.require.extensions.(anonymous function) [as .js] (/usr/local/lib/node_modules/babel-register/lib/node.js:136:7)
at Module.load (module.js:357:32)
at Function.Module._load (module.js:314:12)
at Function.Module.runMain (module.js:447:10)
at /usr/local/lib/node_modules/babel-cli/lib/_babel-node.js:161:27
at Object. (/usr/local/lib/node_modules/babel-cli/lib/_babel-node.js:162:7)
at Module._compile (module.js:413:34)
Вывод можно разделить на две части:
- Первая — описание того, что ожидалось от функции и что было получено. В нашем примере это строка
AssertionError: 3 == 1. Читается она следующим образом: «ожидалось, что функция вернет 3, но она вернула 1». Это уже хорошо, но еще хотелось бы увидеть, с какими параметрами была вызвана функция. И в этом нам поможет вторая часть вывода.
- Вторая часть называется backtrace, она содержит список функций, которые последовательно вызывались в коде. Порядок вывода, чаще всего, обратный: в начале то, что вызывалось последним.
В первую очередь нужно, начиная с конца, найти первое упоминание функции из файла, который похож на тестовый. Обычно его называние содержит слово test. В примере выше это at Object. (test.js:4:8) . В скобках указана строчка, на которой находится вызов этого утверждения. В данном случае — строчка 4.
Всё, что теперь остается, это зайти в соответствующий файл и посмотреть то, как вызывалась ваша функция.
Предупреждения компилятора и интерпретатора
Синтаксические ошибки
Самый простой тип ошибок. Такая ошибка говорит о том, что вы ошиблись в синтаксисе. Забыли запятую, скобку и тому подобные вещи. Такие ошибки легко находить и исправлять. Синтаксическая ошибка сопровождается текстом, по которому можно загуглить возможные причины.
Другие ошибки
Большой класс ошибок, которые могут возникать в процессе разработки. В выводе компилятора или интерпретатора всегда присутствует сообщение об ошибке, которое очень важно понять. Проще всего сделать, загуглив текст ошибки. Рекомендуем наш гайд Как искать техническую информацию.
Также ошибки содержат вывод backtrace, по которому можно найти то место, в котором возникла ошибка и попробовать его проанализировать.
Многие из этих ошибок легко исправить с помощью отладочной печати (см. урок Отладочная печать).
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25
x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
-
Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
-
Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
-
Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
-
Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 🙂
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
items = [0,1,2,3,4,5]
print items[8]
//комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo'
if input == 'Hippo':
print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Недавно мы рассказали о том, как начать писать программы на JavaScript:
- что такое HTML и JavaScript;
- из чего состоят скрипты;
- как и где их выполнять и куда вставлять;
- где искать готовые решения и что с ними потом делать;
- как работать с разными элементами и обрабатывать нажатия клавиш.
Теперь шагнём дальше — изучим отладку скриптов в браузере и посмотрим, чем она может нам помочь.
Что такое отладка
Отладка — это поиск и исправление ошибок в программе. Например, мы написали скрипт, добавили его на страницу, настроили запуск по нажатию кнопки — а при нажатии ничего не происходит. При этом в консоли нет никаких ошибок — все команды верные, браузер просто что-то делает, а результата нет. Отладка нужна как раз для того, чтобы найти ошибку и исправить её.
Варварская отладка
Самый примитивный вариант отладки — добавить в код на JavaScript метод console.log(), поместив в скобки нужные данные для отладки. Console.log() — это просто способ вывести в консоль какой-нибудь текст.
Например, внутри функции можно сказать: console.log(‘Вызвана такая-то функция’) — и в нужный момент мы увидим, что функция вызвалась (или нет).
Минус этого подхода в том, что в коде появляется много отладочного мусора. А ещё, если мы не предусмотрели логирование для какой-то функции, то мы не поймаем в ней ошибку.
К счастью, помимо console.log() человечество изобрело много удобных инструментов отладки.
Что нужно для отладки
Для несложных проектов на JavaScript проще всего использовать встроенный отладчик в браузере Google Chrome. Единственное ограничение — он работает только с файлами скриптов, а не со встроенным в страницу кодом. Это значит, что если код скрипта находится внутри HTML-файла внутри тега
Получиться должно что-то вроде такого:
Сохраняем этот код как HTML-файл, например index.html, и кладём в ту же папку, что и скрипт. Теперь заходим в папку и дважды щёлкаем по HTML-файлу, чтобы открыть эту страницу в браузере:

На странице ничего нет, но нам нужна не страница, а скрипт, поэтому находим слева наш файл temp.js и нажимаем на него — откроется код скрипта. Теперь можно начинать отладку:

Добавляем точки остановки
Точка остановки — это место, в котором наш скрипт должен остановиться и ждать дальнейших действий программиста. Их ещё называют брейкпоинты, от английского breakpoint — точка, где всё останавливается.
Когда скрипт доходит до этой точки, он ставит скрипт на паузу. При этом все данные и значения переменных скрипта остаются в памяти — в них можно заглянуть.
Брейкпоинт нужен для того, чтобы выполнить скрипт по шагам, начиная с первой команды. Чтобы его установить, нажимаем на номер строки с первой командой — в нашем случае это строка 2:

Обновим страницу и увидим, что скрипт начал работу и остановился. Но он остановился не на второй строке, а на шестой — всё потому, что это первая строка в скрипте, где происходит какое-то действие. Дело в том, что просто объявление новых переменных не влияет на работу скрипта, поэтому он ищет первую команду с действием. В нашем случае — это цикл for:

Пошаговая отладка
Чтобы посмотреть на работу скрипта по шагам, надо нажимать F9 или стрелку вправо с точкой на панели отладки:

Каждый раз, как мы будем нажимать F9 или эту кнопку, скрипт будет переходить к следующей команде, выполнять её и снова становиться на паузу:

Добавляем переменные для отслеживания
Если просто выполнять скрипт по шагам, то мы увидим, какие команды и в каком порядке выполняются, но не будем знать, какие значения лежат в переменных на каждом шагу. Их можно увидеть, просто наведя курсор на любую переменную — над ней появится всплывающая подсказка с текущим значением. Но так работать неудобно — проще сразу видеть значения всех переменных.
Чтобы добавить переменную и видеть её значение во время выполнения, в панели отладки в разделе Watch нажимаем плюсик, вводим имя переменной, выбираем её из списка и нажимаем энтер:

Теперь видно, что на этом шаге значение переменной a равно нулю:

Точно так же добавим остальные переменные: i, b, c. Так мы увидим, что первые два цикла только начались, а внутренний прошёл уже три итерации:

Так, нажимая постоянно F9, мы прогоним весь скрипт до конца и посмотрим, при каких значениях какие условия выполняются и как находится решение:

Но у такого подхода есть минус — если вложенных циклов много или скрипт очень большой, то на пошаговое выполнение уйдёт много времени. Чтобы не перебирать всё вручную, ставят дополнительные брейкпойнты в нужных местах.
Отладка брейкпойнтами
Допустим, нам важно понять, в какой момент скрипт находит и выдаёт решение. Глядя в код, мы понимаем, что как только скрипт дошёл до команды console.log() — он нашёл очередное решение. Это значит, что мы можем поставить брейкпоинт только на эту строчку и не прогонять вручную весь скрипт: он сам остановится, когда дойдёт до неё, а мы сможем посмотреть значения переменных в этот момент.
- Нажимаем снова на строку 2 и убираем предыдущую точку остановки.
- Ставим брейкпоинт на строку 20 — там, где происходит вывод решения в консоль.
- Нажимаем F8.
После этого скрипт продолжит работу сам и снова остановится, как только дойдёт до этой строки. Обратите внимание на значения переменных — они меняются к каждой остановке, а значит, скрипт работает как обычно, но останавливается в нужном нам месте:

Таких точек остановки можно поставить сколько угодно и в любой момент — на каждой из них отладчик остановится и покажет текущее состояние скрипта.
Зачем это всё
Отладка нужна, чтобы найти ошибки в программе. Если мы видим, что на очередном шаге в переменной находится не то, что мы ожидали увидеть, значит, что-то в коде идёт не так. Мы ставим брейкпоинт на начало нужных команд, запускаем отладку и находим команду, которая приводит к ошибке.
В следующей статье мы покажем на примере с реальным кодом, как отладка помогает находить и исправлять такие ошибки. Подпишитесь, чтобы не пропустить это.
Перевод публикуется с сокращениями, автор
Выявление ошибок называется
дебаггингом, а дебаггер – помогающий понять причину их появления инструмент. Умение находить
и исправлять ошибки в коде – важный навык в работе программиста, не
пренебрегайте им.
IDLE (Integrated Development and Learning Environment) – кроссплатформенная интегрированная среда разработки и обучения для Python, созданная Гвидо ван Россумом.
Используйте окно управления отладкой
если отладка отсутствует в строке меню, убедитесь, что интерактивное окно находится
в фокусе.
Обзор окна управления отладкой
Чтобы увидеть работу отладчика, напишем простую
программу без ошибок. Введите в редактор следующий код:
for i in range(1, 4):
j = i * 2
print(f"i is {i} and j is {j}")
Сохраните все, откройте окно отладки и нажмите клавишу F5 –
выполнение не завершилось.
Окно отладки будет выглядеть следующим образом:
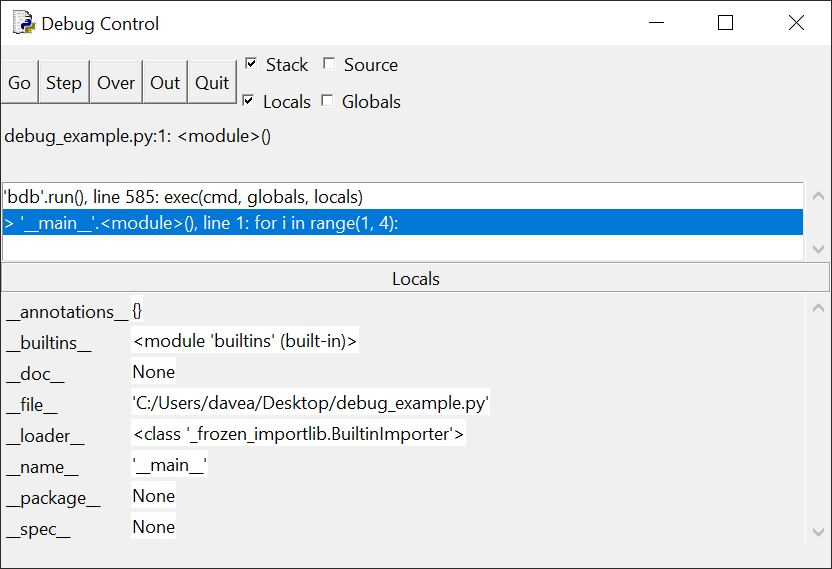
Обратите внимание, что панель в верхней части окна содержит сообщение:
> '__main__'.(), line 1: for i in range(1, 4):
Расшифруем: код for i in range(1, 4): еще не запущен, а '__main__'.module() сообщает, что в данный момент мы находимся в
основном разделе программы, а не в определении функции.
Ниже панели стека находится панель Locals, в которой
перечислены непонятные вещи: __annotations__, __builtins__, __doc__ и т. д. – это
внутренние системные переменные, которые пока можно игнорировать. По мере
выполнения программы переменные, объявленные в коде и отображаемые в этом окне,
помогут в отслеживании их значений.
В левом верхнем углу окна расположены пять кнопок:
Go, Step, Over, Out и Quit – они управляют перемещением отладчика по коду.
В следующих разделах вы узнаете, что делает каждая из
этих кнопок.
Кнопка Step
Нажмите Step и окно отладки будет выглядеть
следующим образом:
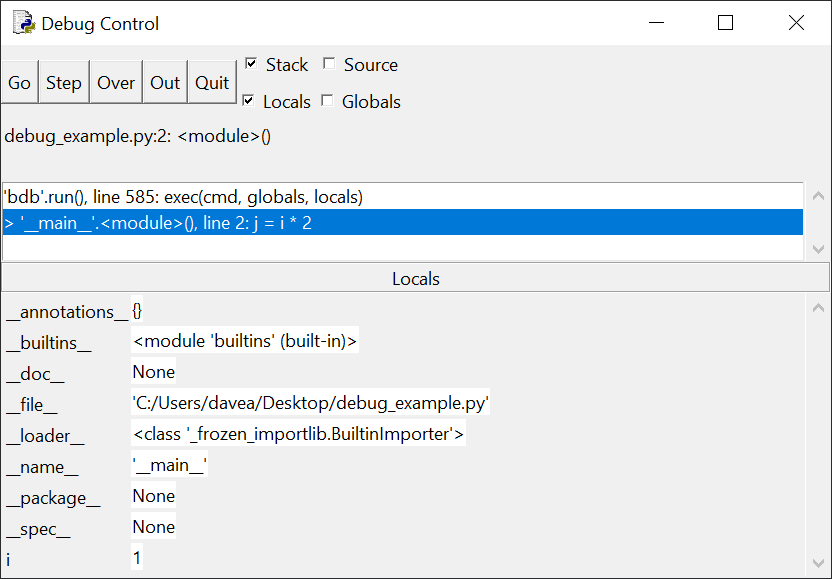
Обратите внимание на два отличия. Во-первых, сообщение на
панели стека изменилось:
> '__main__'.(), line 2: j = i * 2:
На этом этапе выполняется line 1 и отладчик останавливается перед
выполнением line 2.
Во-вторых – новая переменная i со значением 1 на панели Locals. Цикл for в line 1
создал переменную и присвоил ей это значение.
Здесь важно, что можно отслеживать растущие значения i и j по
мере прохождения цикла for. Это полезная фича поиска источника ошибок в коде.
Знание значения каждой переменной в каждой строке кода может помочь точно
определить проблемную зону.
Точки останова и кнопка Go
Часто вам известно, что ошибка должна всплыть в определенном куске
кода, но неизвестно, где именно. Чтобы не нажимать кнопку Step весь
день, установите точку останова, которая скажет отладчику запускать весь код,
пока он ее не достигнет.
Точки останова сообщают отладчику, когда следует
приостановить выполнение кода, чтобы вы могли взглянуть на текущее состояние
программы.
Чтобы установить точку останова, щелкните правой кнопкой мыши
(Ctrl для Mac) по строке кода, на которой хотите сделать паузу, и выберите
пункт Set Breakpoint – IDLE выделит линию желтым. Чтобы удалить ее, выберите Clear
Breakpoint.
Установите точку останова в строке с оператором print(). Окно
редактора должно выглядеть так:
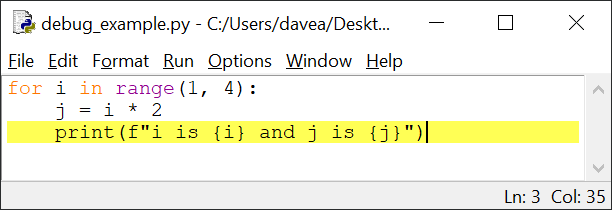
Сохраните и запустите. Как и раньше, панель стека указывает, что отладчик запущен и ожидает выполнения line 1. Нажмите
кнопку Go и посмотрите, что произойдет:
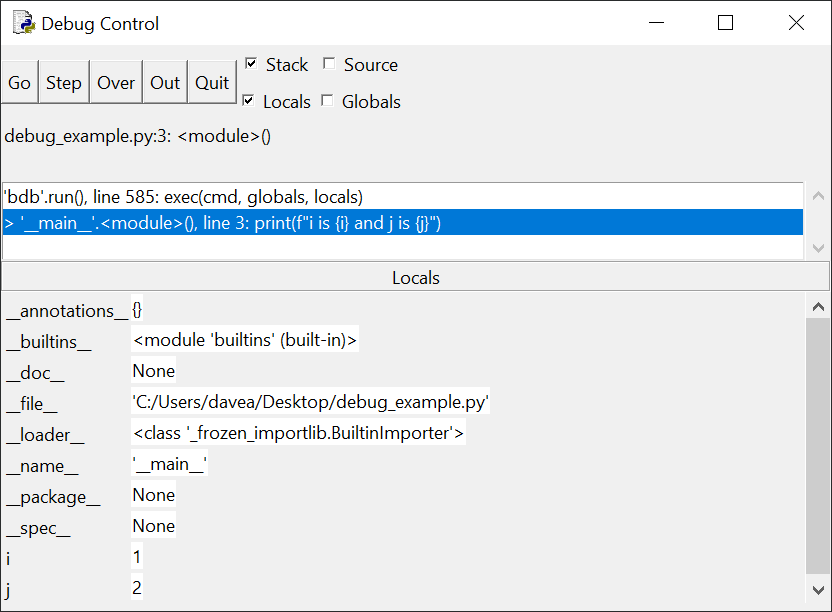
Теперь на панели стека информация о выполнении line 3:
> '__main__'.(), line 3: print(f"i is {i} and j is {j}")
На панели Locals мы видим, что переменные i и j имеют значения 1
и 2 соответственно. Нажмем кнопку Go и попросим отладчик запускать код до точки
останова или до конца программы. Снова нажмите Go – окно отладки теперь выглядит так:
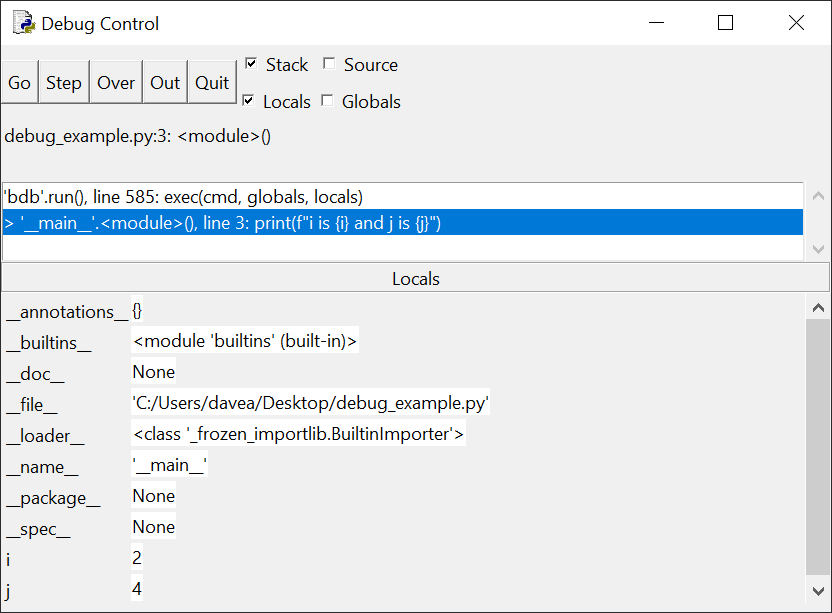
На панели стека отображается то же сообщение, что и раньше –
отладчик ожидает выполнения line 3. Однако значения переменных i и j теперь
равны 2 и 4. Интерактивное окно также отображает выходные данные после первого
запуска строки с помощью функции print() через цикл.
Нажмите кнопку в третий раз. Теперь i и j равны 3 и 6. Если
нажать Go еще раз, программа завершит работу.
Over и Out
Кнопка Over работает, как сочетание Step и Go – она
перешагивает через функцию или цикл. Другими словами, если вы собираетесь попасть
в функцию с помощью отладчика, можно и не запускать код этой функции – кнопка
Over приведет непосредственно к результату ее выполнения.
Аналогично если вы уже находитесь внутри функции или цикла –
кнопка Out выполняет оставшийся код внутри тела функции или цикла, а затем
останавливается.
В следующем разделе мы изучим некоторые ошибки и узнаем, как
их исправить с помощью IDLE.
Борьба с багами
Взглянем на «
Следующий код определяет функцию add_underscores(), принимающую
в качестве аргумента строковый объект и возвращающую новую строку – копию слова с каждым символом, окруженным подчеркиванием. Например,
add_underscores("python") вернет «_p_y_t_h_o_n_».
Вот неработающий код:
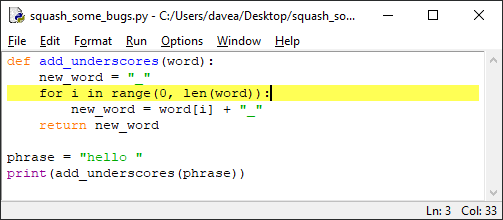
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
phrase = "hello"
print(add_underscores(phrase))
Введите этот код в редактор, сохраните и нажмите F5.
Ожидаемый результат – _h_e_l_l_o_, но вместо этого выведется o_.
Если вы нашли, в чем проблема, не исправляйте ее. Наша цель – научиться
использовать для этого IDLE.
Рассмотрим 4 этапа поиска бага:
- предположите, где может быть ошибка;
- установите точку останова и проверьте код по строке за раз;
- определите строку и внесите изменения;
- повторяйте шаги 1-3, пока код не заработает.
Предположение
Сначала вы не сможете точно определить местонахождение ошибки,
но обычно проще логически представить, в какой раздел кода смотреть.
Обратите внимание, что программа разделена на два раздела:
определение функции add_underscores() и основной блок, определяющий переменную
со значением «hello» и выводящий результат.
Посмотрим на основной раздел:
phrase = "hello"
print(add_underscores(phrase))
Очевидно, что здесь все хорошо и проблема должна быть в
определении функции:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
Первая строка создает переменную new_word со значением «_». Промах,
проблема находится где-то в теле цикла for.
Точка останова
Определив, где может быть ошибка, установите точку
останова в начале цикла for, чтобы проследить за происходящим внутри кода:
Запустим. Выполнение останавливается на строке с определением
функции.
Нажмите кнопку Go, чтобы выполнить код до точки останова:
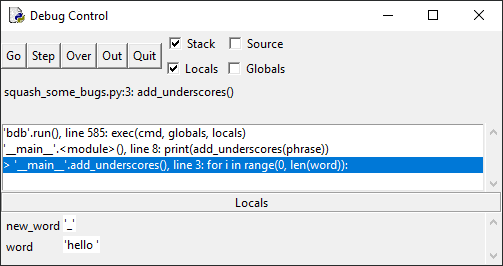
Код останавливается перед циклом for в функции
add_underscores(). Обратите внимание, что на панели Locals отображаются две
локальные переменные – word со значением «hello», и new_word со значением «_»,
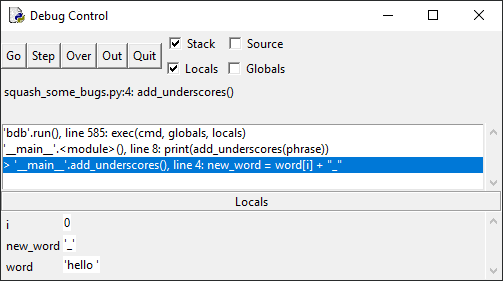
Переменная i – это счетчик для цикла for, который можно
использовать, чтобы отслеживать активную на данный момент итерацию.
Нажмите кнопку Step еще раз и посмотрите на панель Locals –
переменная new_word приняла значение «h_»:
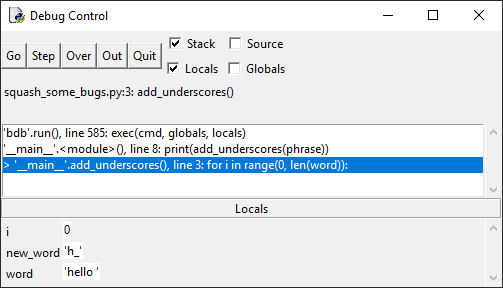
Это неправильно т. к. сначала в new_word было значение «_», на
второй итерации цикла for в ней должно быть «_h_». Если нажать Step еще
несколько раз, то увидим, что в new_word попадает значение e_, затем l_ и так
далее.
Определение ошибки и исправление
Как мы уже выяснили – на каждой итерации цикла new_word
перезаписывается следующим символом в строке «hello» и подчеркиванием.
Поскольку внутри цикла есть только одна строка кода, проблема должна быть именно
там:
new_word = word[i] + "_"
Код указывает Python получить следующий символ word,
прикрепить подчеркивание и назначить новую строку переменной new_word. Это
именно то неверное поведение, которое мы наблюдали.
new_word = new_word + word[i] + "_"
Если бы вы закрыли
отладчик, не нажав кнопку Quit, при повторном открытии окна отладки могла
появиться ошибка:
You can only toggle the debugger when
idle
Всегда нажимайте кнопку Go или Quit, когда заканчиваете отладку,
иначе могут возникнуть проблемы с ее повторным запуском.
Повторение шагов 1-3, пока ошибка не исчезнет
Сохраните изменения в программе и запустите ее снова. В окне
отладки нажмите кнопку Go, чтобы выполнить код до точки останова. Понажимайте
Step несколько раз и смотрите, что происходит с переменной new_word на каждой
итерации – все работает, как положено. Иногда необходимо повторять этот процесс
несколько раз, прежде чем исправится ошибка.
Альтернативные способы поиска ошибок
Использование отладчика может быть сложным и трудоемким, но
это самый надежный способ найти ошибки в коде. Однако отладчики не всегда есть в наличии. В подобных ситуациях можно использовать print debugging для поиска
ошибок в коде. задействует функцию print() для отображения в консоли текста, указывающего место выполнения программы и состояние
переменных.
Например, вместо отладки предыдущего примера можно добавить
следующую строку в конец цикла for:
print(f"i = {i}; new_word = {new_word}")
Измененный код будет выглядеть следующим образом:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
print(f"i = {i}; new_word = {new_word}")
return new_word
phrase = "hello"
print(add_underscores(phrase))
Вывод должен выглядеть так:
i = 0; new_word = h_
i = 1; new_word = e_
i = 2; new_word = l_
i = 3; new_word = l_
i = 4; new_word = o_
o_
работает, но имеет
несколько недостатков по сравнению с отладкой дебаггером. Вы должны запускать
всю программу каждый раз, когда хотите проверить значения переменных, а также помнить про удаление вызовов функций print().
Один из способов улучшить наш цикл – перебирать символы в
word:
def add_underscores(word):
new_word = "_"
for letter in word:
new_word = new_word + letter + "_"
return new_word
Заключение
Теперь вы знаете все об отладке с помощью DLE.
Вы можете использовать этот принцип с
различными дебагерами.
В статье мы разобрали следующие темы:
- использование окна управления отладкой;
- установку точки останова для глубокого понимания работы кода;
- применение кнопок Step, Go, Over и Out;
- четырехэтапный процессом выявления и удаления ошибок.
Не останавливайтесь в обучении и практикуйте дебаггинг – это
весело!
- ТОП-10 книг по Python: эффективно, емко, доходчиво
- Парсинг сайтов на Python: подробный видеокурс и программный код
- Python + Visual Studio Code = успешная разработка
- 29 Python-проектов, оказавших огромное влияние на разработку
- 15 вопросов по Python: как джуниору пройти собеседование
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Ошибки оформления (синтаксиса и линтера)
—
Основы JavaScript
Если программа на JavaScript написана синтаксически некорректно, то интерпретатор выводит на экран соответствующее сообщение, а также указание на файл и строчку в нем, где, по его мнению, произошла ошибка. Синтаксическая ошибка возникает в том случае, когда код был записан с нарушением грамматических правил. В человеческих языках грамматика важна, но текст с ошибками чаще всего можно понять и прочитать. В программировании все строго. Любое мельчайшее нарушение, и программа даже не запустится. Примером может быть забытая ;, неправильно расставленные скобки и другие детали.
Вот пример кода с синтаксической ошибкой:
Если запустить код выше, то мы увидим следующее сообщение: SyntaxError: missing ) after argument list, а также указание на строку и файл, где возникла эта ошибка. Подобные синтаксические ошибки в JavaScript относятся к разряду SyntaxError.
С одной стороны, ошибки SyntaxError — самые простые, потому что они связаны исключительно с грамматическими правилами написания кода, а не с самим смыслом кода. Их легко исправить: нужно лишь найти нарушение в записи.
С другой стороны, интерпретатор не всегда может четко указать на это нарушение. Поэтому бывает, что забытую скобку нужно поставить не туда, куда указывает сообщение об ошибке.
Ошибки линтера
Теперь, когда мы уже научились писать простые программы, можно немного поговорить о том, как их писать.
Код программы следует оформлять определенным образом, чтобы он был достаточно понятным и простым в поддержке. Специальные наборы правил — стандарты — описывают различные аспекты написания кода. Таких стандартов несколько, самые известные в JavaScript: AirBnb, Standard, Google. В уроках мы будем придерживаться AirBnb.
В любом языке программирования существуют утилиты — так называемые линтеры. Они проверяют код на соответствие стандартам. В JavaScript это eslint.
Взгляните на пример из предыдущего урока:
// => 10.5
Линтер будет «ругаться» на нарушение сразу нескольких правил:
В прошлом уроке мы сами признали, что такое обилие цифр и символов запутывает, и решили добавить скобки исключительно для удобства чтения:
// => 10.5
Этот вариант уже не нарушает правил, и линтер будет «молчать».
Рассмотрим еще один пример:
Есть ли здесь нарушение стандарта?
К сожалению, да. На этот раз операции * и / находятся в одном выражении без разделения скобками. Вы можете решить эту проблему, добавив дополнительные скобки. Но в какой-то момент количество скобок может быть уже настолько большим, что код снова станет неудобным и непонятным. В этот момент разумнее будет разделить выражение на отдельные части. Мы научимся это делать в следующих уроках.
no-mixed-operators — лишь одно из большого количества правил. Другие правила описывают отступы, названия создаваемых сущностей, скобки, математические операции, длину строк и множество иных аспектов. Каждое отдельное правило кажется довольно мелким, не очень важным. Но вместе они составляют основу хорошего кода.
На Хекслете линтер начинает проверять код и сообщать о нарушениях после оформления подписки.
Дополнительные материалы

Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.