

Екатерина Андреевна Гапонько
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Виды ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
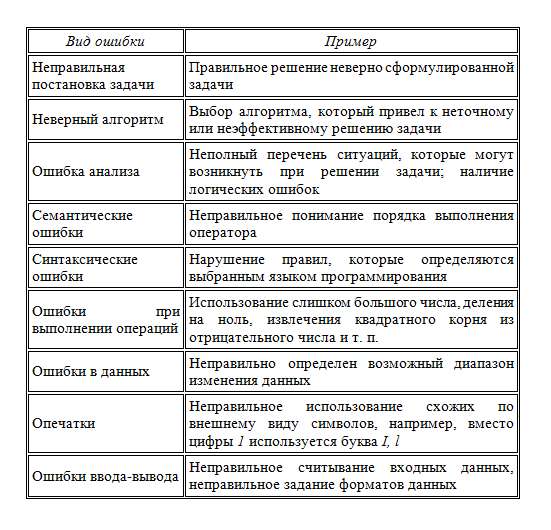
Рассмотрим более подробно некоторые из вышеприведенных видов ошибок.
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы.
Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примерами синтаксических ошибок является:
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
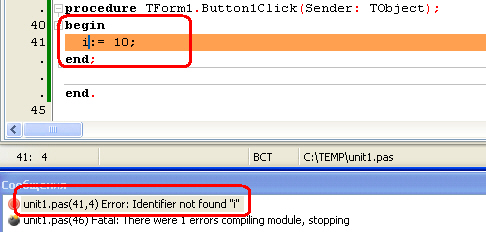
Синтаксическая ошибка «Не задан идентификатор»:
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
«Ошибки в программах » 👇
- после проверки заданного условия неправильно указана ветвь алгоритма;
- неполный перечень возможных условий при решении задачи;
- один или более блоков алгоритма в программе пропущен.
Ошибки в циклах:
- неправильно указано начало цикла;
- неправильно указаны условия окончания цикла;
- неправильно указано количество повторений цикла;
- использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными:
- неправильно задан тип данных;
- организовано считывание меньшего или большего объёма данных, чем нужно;
- неправильно отредактированы данные.
Ошибки в использовании переменных:
- используются переменных, для которых не указаны начальные значения;
- ошибочно указана одна переменная вместо другой.
Ошибки при работе с массивами:
- пропущено предварительное обнуление массивов;
- неправильное описание массивов;
- индексы массивов следуют в ошибочном порядке.
Ошибки в арифметических операциях:
- неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная);
- неправильно определен порядок действий;
- выполняется деление на нуль;
- при расчете выполняется попытка извлечения квадратного корня из отрицательного числа;
- не учитываются значащие разряды числа.
Ошибка в арифметических операциях «Деление на нуль»:

Все вышеописанные ошибки можно обнаружить методом тестирования.
Сопровождение программы
Сопровождением программ называются работы по обслуживанию программ в процессе их эксплуатации.
В случае многократного использования разработанной программы для решения различных задач определенного класса требуется проведение таких дополнительных работ, как:
- при обнаружении ошибок работы программы они должны исправляться;
- при изменении требований эксплуатации необходимая модификация программы;
- выполнение доработки программы с целью решения конкретных задач;
- выполнение дополнительных тестовых расчетов;
- внесение исправлений в рабочую документацию;
- улучшение программы и т.д.
При проведении работ по сопровождению многих программ стоимость этого сопровождения превышает половину затрат, которые приходятся на весь период времени существования программы (от разработки начального алгоритма до морального ее устаревания).
Программа, которая предназначена для длительной эксплуатации, должна сопровождаться соответствующей документацией и инструкцией по ее использованию.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Программист и ошибки — актуально во все времена
Чтобы максимально раскрыть смысл фразы «актуально во все времена«, в качестве иллюстрирующих примеров будут приведены сведения времён старой доброй DOS 🙂, поэтому материал рекомендуется к прочтению любителям ностальгии
Какие же бывают типы ошибок?
Тип №1. Ошибки в программном комплексе, допущенные при разработке и не обнаруженные при его тестировании
• В «Справочнике Microsoft Works» и интерактивной помощи пакета интегрированной обработки информации Works 2.0 функция ЕСЛИ описана как
ЕСЛИ (Условие, ЗначениеЛожь, ЗначениеИстина)
Однако в действительности работа данной функции должна иметь следующий вид:
ЕСЛИ (Условие, ЗначениеИстина, ЗначениеЛожь)
В «Руководстве пользователя Microsoft Works для Windows» пакета Works 3.0 эта ошибка исправлена 🙂
• Потеря связи с космической станцией «Фобос-1» (СССР) произошла из-за ошибочной команды, переданной с Земли на бортовой компьютер.
• Причиной осложнений, возникших при возвращении на Землю из космической экспедиции советско-афганского и советско-французского экипажей, явились ошибки, допущенные в программном обеспечении бортовых компьютеров.
К данному типу относятся ошибки в алгоритмах, когда алгоритм неверный или создан на основе неправильных представлений о действительности:
• Одна из первых компьютерных систем противовоздушной обороны США (60-е годы) в первое же дежурство подняла тревогу, приняв восходящую из-за горизонта Луну за вражескую ракету, поскольку этот «объект» приближался к территории США и не подавал сигналов, что он «свой» 🙂
Тип №2. Ошибки, возникающие при вводе в компьютер неверных данных
Весьма популярные ошибки, предотвращение которых известно под названием «защита от дурака»
• В 1983 году произошло наводнение в юго-западной части США. Причина заключалась в том, что в компьютер были введены неверные данные о погоде, в результате чего он дал ошибочный сигнал шлюзам, перекрывающим реку Колорадо.
• Ещё один печальный пример: в восьмидесятые годы прошлого века в Антарктиде разбился самолёт с туристами на борту, поскольку в управляющую полётом систему были заложены неверные координаты аэропорта взлёта и система ошибочно рассчитала высоту полёта над горами
Тип 3. Компьютерные вирусы, «вмешивающиеся» в работу компьютера и выполняемую им программу.
• Летом 1988 года в Мичиганском госпитале компьютерный вирус инфицировал три компьютера, которые обрабатывали информацию о пациентах. Вирус перемешал фамилии пациентов в базе данных. В результате данного «вмешательства» диагностические сведения одних пациентов оказались приписанными другим пациентам.
Тип 4. Выход из строя элементов компьютера и обслуживающих его систем
Тут, в принципе, всё обстоит точно так же, как и 20 лет назад: в процессе эксплуатации компьютерной системы возможно физическое повреждение накопителя, выход из строя блока питания, отключение электроэнергии, колебание напряжения в электрической сети и др. Результатом такого рода неисправностей может быть полная потеря информации, хранящейся на жёстком диске, частичная или полная потеря информации в файлах баз данных, нарушение работы систем, управляемых компьютером и многое другое. Для предотвращения ошибок данного типа используют системы, в которых одновременно работают несколько компьютеров, дублирующих друг друга, в компьютеры устанавливают два и более параллельно работающих накопителя (вспоминаем RAID-массивы), аппаратуру подключают к источникам бесперебойного питания, которые обеспечивают его работу при отключении электроэнергии или колебаниях напряжения электрической сети и т.д. и т.п.
Тип №5. Выход из строя или сбои в работе измерительных приборов и датчиков, используемых при управлении какими-либо техническими системами и технологическими процессами
• В июле 1985 года произошло преждевременное отключение компьютера одного из основных двигателей американского космического корабля «Челленджер» (Шаттл), едва не закончившееся катастрофой. Положение спас командир корабля, сумевший на двух работающих основных двигателях и двух менее мощных двигателях для маневрирования вывести «Челленджер» на орбиту. Причина же заключалась в том, что один из трёх бортовых компьютеров, управляющих двигателями (на каждый двигатель по компьютеру), был «обманут» вышедшим из строя датчиком, измеряющим температуру газа в двигателе. Для устранения подобных неполадок в будущем на следующих космических кораблях серии Шаттл были установлены датчики изменённой конструкции.
• При запуске французской ракеты нового поколения «Ариан-5» примерно на 37-й секунде полёта компьютер, находившийся на борту ракеты, получил от датчиков системы управления неверную информацию о пространственной ориентации ракеты. Исходя из этой информации, компьютер начал корректировать траекторию полёта для того, чтобы компенсировать не существующую на самом деле погрешность. Ракета стала отклоняться от курса, что привело к возрастанию нагрузок на её корпус. В результате чрезмерных нагрузок верхняя часть ракеты отвалилась, и по команде с земли ракета была взорвана.
Тип 6. «Злая воля человека», носителем которой чаще всего выступает либо программист, либо оператор
Программист, создавая программу, может специально внести в неё ошибку 🙂. Другим вариантом проявления «злой воли программиста» является включение в программу «логической бомбы», срабатывающей, например, после определённого числа запусков программы, определённых значениях входных данных и др. Оператор, обслуживающий компьютер, может сознательно ввести в компьютер неверные данные, которые и будут обработаны компьютером, выдавая неверные выходные данные в соответствии с принципом «мусор на входе – мусор на выходе».
• Сборочный конвейер волжского автомобильного завода в городе Тольятти работает под управлением АСУ, которая обеспечивает своевременное поступление деталей на конвейер со складов и из цехов вспомогательных производств. Для выполнения этой задачи информационно-управляющая система хранит информацию о тысячах узлов и деталей, из которых собирается автомобиль, о запасах деталей на складах, об их движении по транспортным линиям и т. д. На основе этой информации АСУ самостоятельно управляет автоматизированными складами, транспортными конвейерами, а также рядом других устройств.
Программист, разрабатывавший программное обеспечение для управления главным конвейером Волжского автозавода, сознательно внёс в программу «логическую бомбу» в знак протеста против низкой зарплаты. Через некоторое время эта «логическая бомба» сработала, и главный конвейер остановился на несколько дней. Ущерб от остановки составил 1 миллион рублей (в ценах 80-х годов), этот ущерб был несопоставим с зарплатой всех программистов ВАЗа, вместе взятых, а программист был дисквалифицирован и переведён в рабочие.
Подводим итоги
Анализ приведённых типов ошибок показывает, что основными задачами, стоящими перед разработчиками программного обеспечения в плане повышения его надёжности, является:
- устранение ошибок, допущенных при разработке программного обеспечения (1-й тип ошибок);
- проектирование программного обеспечения с учётом человеческого фактора, то есть таким образом, чтобы оно было защищено от «дурака» (2-й тип ошибок). При этом «свалять дурака» могут не только пользователи, работающие за компьютером, но и приборы и датчики, от которых компьютер принимает информацию при управлении техническими или иными системами (5-й тип ошибок);
- использование известных мер безопасности для снижения вероятности переноса компьютерных вирусов (3-й тип ошибок) с программами, передаваемыми в эксплуатацию (в практике распространения программ известны случаи, когда разработчики этих программ записывают дистрибутивы на заражённых вирусами компьютерах).
Таким образом, программный продукт в обязательном порядке должен проходить тщательное тестирование и отладку (выявление ошибок 1-го и 2-го типов). Выявление возможных ошибок 5-го типа производится с помощью имитации отказа приборов и датчиков на прошедших тестирование программных комплексах.
Надеюсь, данный материал окажется полезным. Желаю всем делать поменьше ошибок, ведь это особенно актуально в нынешние кризисные времена :^)
PS: сведения предоставляются по данным из этих источников, множество важных дополнений и опровержений представлены ниже в комментариях, особенно от хабраюзера scoon. Однако оригинальный текст не изменяю

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
-
Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
-
std::bad_alloc: для сбоев выделения памяти. -
std::runtime_error: для общих runtime-ошибок. -
std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок. -
std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
System_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
Expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected try_malloc(...); В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.
Дебаг и поиск ошибок

Для опытных разработчиков информация статьи может быть очевидной и если вы себя таковым считаете, то лучше добавьте в комментариях полезных советов.
По опыту работы с начинающими разработчиками, я сталкиваюсь с тем, что поиск ошибок порой занимает слишком много времени. Не из-за того, что они глупее более опытных товарищей или не разбираются в процессах, а из-за отсутствия понимания с чего начать и на чём акцентировать внимание. В статье я собрал общие советы о том где обитают ошибки и как найти причину их возникновения. Примеры в статье даны на JavaScript и .NET, но они актуальны и для других платформ с поправкой на специфику.
Как обнаружить ошибку
Прочитай информацию об исключении
Если выполнение программы прерывается исключением, то это первое место откуда стоит начинать поиск.
В каждом языке есть свои способы уведомления об исключениях. Например в JavaScript для обработки ошибок связанных с Web Api существует DOMException. Для пользовательских сценариев есть базовый тип Error. В обоих случаях в них содержится информация о наименовании и описании ошибки.
Для .NET существует класс Exception и каждое исключение в приложении унаследовано от данного класса, который представляет ошибки происходящие во время выполнения программы. В свойстве Message читаем текст ошибки. Это даёт общее понимание происходящего. В свойстве Source смотрим в каком объекте произошла ошибка. В InnerException смотрим, нет ли внутреннего исключения и если было, то разворачиваем его и смотрим информацию уже в нём. В свойстве StackTrace хранится строковое представление информации о стеке вызова в момент появления ошибки.
Каким бы языком вы не пользовались, не поленитесь изучить каким образом язык предоставляет информацию об исключениях и что эта информация означает.
Всю полученную информацию читаем вдумчиво и внимательно. Любая деталь важна при поиске ошибки. Иногда начинающие разработчики не придают значения этому описанию. Например в .NET при возникновении ошибки NRE с описанием параметра, который разработчик задаёт выше по коду. Из-за этого думает, что параметр не может быть NRE, а значит ошибка в другом месте. На деле оказывается, что ошибки транслируют ту картину, которую видит среда выполнения и первым делом за гипотезу стоит взять утверждение, что этот параметр равен null. Поэтому разберитесь при каких условиях параметр стал null, даже если он определялся выше по коду.
Пример неявного переопределения параметров — использование интерцептора, который изменяет этот параметр в запросе и о котором вы не знаете.
Разверните стек
Когда выбрасывается исключение, помимо самого описания ошибки полезно изучить стек выполнения. Для .NET его можно посмотреть в свойстве исключения StackTrace. Для JavaScript аналогично смотрим в Error.prototype.stack (свойство не входит в стандарт) или можно вывести в консоль выполнив console.trace(). В стеке выводятся названия методов в том порядке в котором они вызывались. Если то место, где падает ошибка зависит от аргументов которые пришли из вызывающего метода, то если развернуть стек, мы проследим где эти аргументы формировались.
Загуглите текст ошибки
Очевидное правило, которым не все пользуются. Применимо к не типовым ошибкам, например связанным с конкретной библиотекой или со специфическим типом исключения. Поиск по тексту ошибки помогает найти аналогичные случаи, которые даже если не дадут конкретного решения, то помогут понять контекст её возникновения.
Прочитайте документацию
Если ошибка связана с использованием внешней библиотеки, убедитесь что понимаете как она работает и как правильно с ней взаимодействовать. Типичные ошибки, когда подключив новую библиотеку после прочтения Getting Started она не работает как ожидалось или выбрасывает исключение. Проблема может быть в том, что базовый шаблон подключения библиотеки не применим к текущему приложению и требуются дополнительные настройки или библиотека не совместима с текущим окружением. Разобраться в этом поможет прочтение документации.
Проведите исследовательское тестирование
Если используете библиотеку которая не работает как ожидалось, а нормальная документация отсутствует, то создайте тесты которые покроют интересующий функционал. В ассертах опишите ожидаемое поведение. Если тесты не проходят, то подбирая различные вариации входных данных выясните рабочую конфигурацию. Цель исследовательских тестов помочь разобраться без документации, какое ожидаемое поведение у изучаемой библиотеки в разных сценариях работы. Получив эти знания будет легче понять как правильно использовать библиотеку в проекте.
Бинарный поиск
В неочевидных случаях, если нет уверенности что проблема в вашем коде, а сообщение об ошибке не даёт понимания где проблема, комментируем блок кода в котором обнаружилась проблема. Убеждаемся что ошибка пропала. Аналогично бинарному алгоритму раскомментировали половину кода, проверили воспроизводимость ошибки. Если воспроизвелась, закомментировали половину выполняемого кода, повторили проверку и так далее пока не будет локализовано место появления ошибки.
Где обитают ошибки
Ошибки в своём коде
Самые распространенные ошибки. Мы писали код, ошиблись в формуле, забыли присвоить значение переменной или что-то не проинициализировали перед вызовом. Такие ошибки легко исправить и легко найти место возникновения если внимательно прочитать описание возникшей ошибки.
Ошибки в чужом коде
Если над проектом работает больше одного разработчика, чей код взаимодействует друг с другом, возможна ситуация, когда ошибка происходит в чужом коде. Может сложиться впечатление, что если программа раньше работала, а сломалась только после того, как вы добавили свой код, то проблема в этом коде. На деле может быть, что ваш код обращается к уже существующему чужому коду, но передаёт туда граничные значения данных, работу с которыми забыли протестировать и обработать такие случаи.
В зависимости от соглашений на проекте исправляйте такие ошибки как свои собственные, либо сообщайте о них автору и ждите внесения правок.
Ошибки в библиотеках
Ошибки могут падать во внешних библиотеках к которым нет доступа и в таком случае непонятно что делать. Такие ошибки можно разделить на два типа. Первый- это ошибки в коде библиотеки. Второй- это ошибки связанные с невалидными данными или окружением, которые приводят к внутреннему исключению.
Первый случай хотя и редкий, но не стоит о нём забывать. В этом случае можно откатиться на другую версию библиотеки и создать Issue с описанием проблемы. Если это open-source и нет времени ждать обновления, можно собрать свою версию исправив баг самостоятельно, с последующей заменой на официальную исправленную версию.
Во втором случае определите откуда из вашего кода пришли невалидные данные. Для этого смотрим стек выполнения и по цепочке прослеживаем место в котором библиотека вызывается из нашего кода. Далее с этого места начинаем анализ, как туда попали невалидные данные.
Ошибки не воспроизводимые локально
Ошибка воспроизводится на develop стенде или в production, но не воспроизводится локально. Такие ошибки сложнее отлавливать потому что не всегда есть возможность запустить дебаг на удалённой машине. Поэтому убеждаемся, что ваше окружение соответствует внешнему.
Проверьте версию приложения
На стенде и локально версии приложения должны совпадать. Возможно на стенде приложение развёрнуто из другой ветки.
Проверьте данные
Проблема может быть в невалидных данных, а локальная и тестовая база данных рассинхронизированы. В этом случае поиск ошибки воспроизводим локально подключившись к тестовой БД, либо сняв с неё актуальный дамп.
Проверьте соответствие окружений
Если проект на стенде развёрнут в контейнере, то в некоторых IDE (JB RIder) можно дебажить в контейнере. Если проект развёрнут не в контейнере, то воспроизводимость ошибки может зависеть от окружения. Хотя .Net Core мультиплатформенный фреймворк, не всё что работает под Windows так же работает под Linux. В этом случае либо найти рабочую машину с таким же окружением, либо воспроизвести окружение через контейнеры или виртуальную машину.
Коварные ошибки
Метод из подключенной библиотеки не хочет обрабатывать ваши аргументы или не имеет нужных аргументов. Такие ситуации возникают, когда в проекте подключены две разных библиотеки содержащие методы с одинаковым названием, а разработчик по привычке понадеялся, что IDE автоматически подключит правильный using. Такое часто бывает с библиотеками расширяющими функционал LINQ в .NET. Поэтому при автоматическом добавлении using, если всплывает окно с выбором из нескольких вариантов, будьте внимательны.
Похожая ситуация и с одинаково названными типами. Если сборка включает несколько проектов в которых присутствуют одинаково названные классы, то можно по ошибке обращаться не к тому который требуется. Чтобы избежать обоих случаев, убедитесь, что в месте возникновения ошибки идёт обращение к правильным типам и методам.
Дополнительные материалы
Алгоритм отладки
-
Проверь гипотезу — если гипотеза проверку не прошла то п.3.
-
Убедись что исправлено — если не исправлено, то п.3.
Подробнее ознакомиться с ним можно в докладе Сергея Щегриковича «Отладка как процесс».
Чем искать ошибки, лучше не допускать ошибки. Прочитайте статью «Качество вместо контроля качества», чтобы узнать как это делать.
Итого
-
При появлении ошибки в которой сложно разобраться сперва внимательно и вдумчиво читаем текст ошибки.
-
Смотрим стек выполнения и проверяем, не находится ли причина возникновения выше по стеку.
-
Если по прежнему непонятно, гуглим текст и ищем похожие случаи.
-
Если проблема при взаимодействии с внешней библиотекой, читаем документацию.
-
Если нет документации проводим исследовательское тестирование.
-
Если не удается локализовать причину ошибки, применяем метод Бинарного поиска.
Учебный курс по теории и практике программирования. Бесплатно. В виде структурированного текста. Статья 3. Эта статья посвящена ошибкам программ, их классификации и способам исправления.
Предупреждение об использованных материалах и правах
1 Методики поиска и классификации ошибок
Данная статья является компиляцией материала трёх лекций, посвященных ошибкам. Такой формат выбран отчасти из-за нехватки времени, отчасти из-за нежелания спамить статьями и также из-за постоянного желания улучшить и так неплохое.
Так как курс нацелен на повышение качества программы, нам необходимо понимание того, что приводит к его снижению. Эта лекция в нескольких приближениях даст образы «врага». От простого и четкого, до более сложного и подробного. Помимо этого, в специальном разделе, будут приведены примеры типичных ошибок, способы исправления и обхода.
Хочу напомнить, что несмотря на то, что рекомендации так или иначе исходят их опыта работы отдела разработки или проектной команды, излагаемые принципы и методики легко масштабируются до отдельного программиста.
1 Что такое ошибка
В первой части вводной лекции, мы приняли простое определение качества программы, из которого мы можем вывести такое же простое определение ошибки:
Ошибка – это свойство программы, приводящее к ухудшению её качества по любому из трёх критериев качества: работоспособности, сопровождаемости, гибкости.
Прошу задержать внимание на определении, так как мне приходилось часто наблюдать проблемы, связанные с непониманием того, что считать ошибкой.
Например, встречал случаи, когда на официальном уровне ошибкой считалось только то, о чем сообщили пользователи. Изменения можно было вносить только по заявкам конечных пользователей, и найденный в ходе чтения кода баг, не мог быть легально исправлен, кроме как партизанскими методами, путем сочинения писем пользователям, с просьбой зарегистрировать их как обращения от своего имени.
Крайне важно понимать, что ошибка — это имманентное свойство текущей версии программы, а не некоторое событие, явление или баг-репорт и уж тем более не исключение (exception), которое во многих случаях ошибкой не является.