
2 Примеры ошибок, их происхождение, способы обхода и исправления
В этом разделе будут приведены примеры наиболее часто встречающихся ошибок, попытка понять их происхождение и методы устранения.
Для каждого типа ошибки будут приведены основные свойства данного типа как-то: формализуемость; свойства программы, на которые негативно влияет ошибка; потенциально затрагиваемые свойства при исправлении ошибки.
Важно! Этот раздел является иллюстративным примером описания ошибок как явления, и не предполагался как исчерпывающий список ошибок или филиал лепрозория. Назначение раздела показать неоднозначность ошибки как явления:
— Ошибки не настолько многочисленны если их классифицировать, и поддаются потоковой обработке
— Исправление ошибки может ухудшить качество программы
— Не все ошибки являются ошибками
Но если Вы всё равно считаете что раздел нуждается в дополнении, то добро пожаловать в обсуждение.
Синтаксические ошибки
Ошибки, которые обнаруживает компилятор, называют синтаксическими ошибками или ошибками компиляции. Синтаксические ошибки являются результатом ошибок в конструкции кода, таких как неправильное написание ключевого слова, пропуск необходимого знака пунктуации или использование открывающей фигурной скобки без соответствующей закрывающей фигурной скобки. Эти ошибки обычно легко обнаружить, поскольку компилятор говорит вам, где они находятся и что стало их причиной. Пример программы с синтаксической ошибкой:
public class ShowSyntaxErrors {
public static main(String[] args) {
System.out.println("Welcome to Java);
}
}
Попытка компиляции приведённого кода:

Будет сообщено о четырёх ошибках, но в действительности программа содержит две ошибки:
- Во второй строке отсутствует ключевое слово void перед main
- Строка Welcome to Java должна быть закрыта закрывающей кавычкой в третьей строчке программы
Поскольку одна ошибка часто будет приводить к показу множества ошибок компиляции в разных строках, хорошей практикой является исправление ошибок начиная с верхней строки и постепенно двигаясь вниз. Исправление ошибок, которые ранее возникли в программе, может также исправить дополнительные ошибки, которые произошли позже.
Совет: если вы не знаете, как исправить ошибку, внимательно сравните вашу программу, символ за символом с похожими примерами в тексте. На начальном этапе обучения вы, вероятно, будете проводить много времени исправляя ошибки синтаксиса. Скоро вы будете знакомы с синтаксисом Java и сможете быстро исправлять синтаксические ошибки.
System_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
Где обитают ошибки
Ошибки в своём коде
Самые распространенные ошибки. Мы писали код, ошиблись в формуле, забыли присвоить значение переменной или что-то не проинициализировали перед вызовом. Такие ошибки легко исправить и легко найти место возникновения если внимательно прочитать описание возникшей ошибки.
Ошибки в чужом коде
Если над проектом работает больше одного разработчика, чей код взаимодействует друг с другом, возможна ситуация, когда ошибка происходит в чужом коде. Может сложиться впечатление, что если программа раньше работала, а сломалась только после того, как вы добавили свой код, то проблема в этом коде. На деле может быть, что ваш код обращается к уже существующему чужому коду, но передаёт туда граничные значения данных, работу с которыми забыли протестировать и обработать такие случаи.
В зависимости от соглашений на проекте исправляйте такие ошибки как свои собственные, либо сообщайте о них автору и ждите внесения правок.
Ошибки в библиотеках
Ошибки могут падать во внешних библиотеках к которым нет доступа и в таком случае непонятно что делать. Такие ошибки можно разделить на два типа. Первый- это ошибки в коде библиотеки. Второй- это ошибки связанные с невалидными данными или окружением, которые приводят к внутреннему исключению.
Первый случай хотя и редкий, но не стоит о нём забывать. В этом случае можно откатиться на другую версию библиотеки и создать Issue с описанием проблемы. Если это open-source и нет времени ждать обновления, можно собрать свою версию исправив баг самостоятельно, с последующей заменой на официальную исправленную версию.
Во втором случае определите откуда из вашего кода пришли невалидные данные. Для этого смотрим стек выполнения и по цепочке прослеживаем место в котором библиотека вызывается из нашего кода. Далее с этого места начинаем анализ, как туда попали невалидные данные.
Ошибки не воспроизводимые локально
Ошибка воспроизводится на develop стенде или в production, но не воспроизводится локально. Такие ошибки сложнее отлавливать потому что не всегда есть возможность запустить дебаг на удалённой машине. Поэтому убеждаемся, что ваше окружение соответствует внешнему.
Проверьте версию приложения
На стенде и локально версии приложения должны совпадать. Возможно на стенде приложение развёрнуто из другой ветки.
Проверьте данные
Проблема может быть в невалидных данных, а локальная и тестовая база данных рассинхронизированы. В этом случае поиск ошибки воспроизводим локально подключившись к тестовой БД, либо сняв с неё актуальный дамп.
Проверьте соответствие окружений
Если проект на стенде развёрнут в контейнере, то в некоторых IDE (JB RIder) можно дебажить в контейнере. Если проект развёрнут не в контейнере, то воспроизводимость ошибки может зависеть от окружения. Хотя .Net Core мультиплатформенный фреймворк, не всё что работает под Windows так же работает под Linux. В этом случае либо найти рабочую машину с таким же окружением, либо воспроизвести окружение через контейнеры или виртуальную машину.
Коварные ошибки
Метод из подключенной библиотеки не хочет обрабатывать ваши аргументы или не имеет нужных аргументов. Такие ситуации возникают, когда в проекте подключены две разных библиотеки содержащие методы с одинаковым названием, а разработчик по привычке понадеялся, что IDE автоматически подключит правильный using. Такое часто бывает с библиотеками расширяющими функционал LINQ в .NET. Поэтому при автоматическом добавлении using, если всплывает окно с выбором из нескольких вариантов, будьте внимательны.
Похожая ситуация и с одинаково названными типами. Если сборка включает несколько проектов в которых присутствуют одинаково названные классы, то можно по ошибке обращаться не к тому который требуется. Чтобы избежать обоих случаев, убедитесь, что в месте возникновения ошибки идёт обращение к правильным типам и методам.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
4 Когда и как лучше всего исправлять ошибки
В предыдущем разделе мы уже частично ответили на этот вопрос – как можно раньше. Чем раньше ошибка обнаружена, тем меньше расходов понесет предприятие.
Да, грамотная организация процесса разработки, инспекции кода и тестирование сократят число ошибок в продуктовых релизах в десятки раз, но не сведет их до нуля. Поэтому не стоит расслабляться если вы организовали хороший контроль на первых этапах выпуска релиза – ошибки всё равно неизбежны. Разумеется, главная цель — это найти и обезвредить ошибку до того, как она сможет нанести ущерб, но искать и регистрировать ошибки необходимо ВСЕГДА. Даже там, где ошибки быть не может, всё равно необходимо искать.
Позже, мы еще будем возвращаться к причинам возникновения ошибок, но здесь я бы хотел отметить еще одно место и время возникновения множества ошибок. Это голова архитектора. Хорошая архитектура сама по себе снижает риск возникновения ошибок или упрощает их локализацию. При этом не принципиально, идет ли речь об архитектуре базы данных или программного кода отдельного модуля – хорошая продуманная архитектура является наиболее эффективным средством борьбы с ошибками. Именно на этапе планирования новых объектов приложения, борьба с ошибками наиболее эффективна. Тогда как плохая архитектура может заставить даже неплохих разработчиков принимать плохие решения. Ниже в порядке убывания эффективности приведу список мероприятий по исправлению ошибок:
Планирование архитектуры приложения
Каждый дополнительный час, потраченный на обдумывание структуры приложения до его разработки, экономит десятки часов на исправление ошибок или обход ограничений архитектуры и вызванные этим ошибки.
Перманентный рефакторинг в процессе разработки.
По эффективности я поставил этот метод на второе место, только в рамках определения эффективности как отношение объема работы к затраченному времени. В ходе выполнения работ, программист может исправить ошибки в затронутых фрагментах программы. Он это сделает быстро, но количество выполненной работы не может быть велико, если модифицируемый фрагмент программы связан с не очень хорошо спроектированными частями.
Как бы не давили дедлайны, необходимо резервировать из фонда рабочего времени хотя бы небольшой процент на рефакторинг. Начните с 1-5% и устраивайте дни рефакторинга. После того как получите наглядные результаты, можно пробовать увеличивать резерв времени на рефакторинг.
Обработка инцидентов в продуктовых базах
Самая неприятная, но в большинстве случаев неизбежная работа. Единственное что можно сделать, это кардинально сократить число ошибок, доходящих до рабочих релизов. Но так как ошибки неизбежны, необходимо приложить усилия к налаживанию системы регистрации инцидентов и всегда иметь резерв на случай непредвиденных ситуаций.
В рамках отдела резерв обеспечивается дежурствами или выделением отдельного специалиста для работы на последних линиях поддержки, если речь идет об отдельном программисте (частая ситуация для небольших предприятий), то необходимо планировать свою работу так, чтобы всегда можно было оперативно переключиться оперативные проблемы.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
12 Использование изменчивых данных ИБ в качестве констант
Формализуется частично, влияет на надёжность, сопровождаемость и гибкость
Написание алгоритмов, опирающихся на изменчивые значения как на константы. Такой подход может привести к самым неожиданным и печальным результатам. Например, поиск элемента справочника по прямо прописанному в коде номеру, наименованию или GUID просто перестанет работать при даже незначительном изменении наименования или замене объекта обработкой по чистке дублей. В таких случаях, обычно или добавляют константу или заводят специальный справочник/РС где хранятся необходимые ссылки. В крайнем случае — если нет возможности менять структуру данных ИБ — заводят общий метод, возвращающий нужное значение (или прописанное кодом или из хранилища значений). Когда появится возможность изменить структуру БД вы легко замените алгоритм в одном единственном общем методе.
11 «Китайский» метод программирования.
Не формализуется, влияет на надёжность, сопровождаемость и гибкость, исправление влияет на быстродействие
Копирование фрагментов кода с нужным алгоритмом. Это грубая и опасная ошибка. Разумеется, в некоторых случаях копирование применимо и полезно. Но случаи это специфические и применение особых методов к ним должно быть обдумано и обосновано. В иных же случаях «копипаста» не только усложняет чтение и как следствие сопровождение кода, но и может привести к неожиданным и трудноуловимым ошибкам в программе. Например, когда потребности заказчика потребуют внести изменения в исходный алгоритм. В этом случае все созданные копии продолжат использовать старую версию алгоритма. Последствия непредсказуемы, но могут быть катастрофическими. Правильное решение — использование общих формул и алгоритмов — «выделение метода». Создаётся отдельная функция (или обработка с набором методов) и уже эти методы используются в разных частях программы. Для реализации «региональных» особенностей в разных участках кода добавляются особые параметры метода или (если особенности начинают разрастаться) выделяется новый метод или добавляется еще один уровень абстракции. Примерно в таком направлении должна проходить эволюция программы.
3 Разыменование полей в запросах
Формализуется, влияет на производительность, исправление влияет на сопровождаемость и гибкость
Разыменование полей в запросах. Само по себе не слишком страшно если не злоупотреблять и не применять в блоке условий и соединений. Но нужно понимать, что разыменование поля приводит к созданию левого соединения с таблицей объектов к реквизитам которого идет обращение. Если разыменовывается составной тип (например, документ-регистратор), то будет создано столько соединений, сколько ссылочных типов предусмотрено в данном составном типе. В качестве обхода проблемы с созданием множества неявных соединений для составных типов можно использовать функцию «Выразить» для выбираемых полей запроса.
13 Несоответствие наименования переменной хранимому значению.
Не формализуется, влияет на сопровождаемость
Причин может быть несколько:
а) исходный алгоритм поменялся, разработчик поленился переименовать переменные;
б) потребовалось записать куда-то необходимые данные — разработчик решил использовать ранее инициализированную и уже «отработавшую» переменную с принципиально другим значением.
в) разработчик поленился и завел одну или несколько переменных с ни о чем не говорящими названиями типа а1, а2 или Темп1-2, Врем1-2 и.т.д.
9 Поиск в не индексированных коллекциях
Формализуется частично, влияет на производительность, исправление влияет на сопровождаемость
В качестве таких коллекций чаще всего выступают массивы и таблицы значений.
Метод «найти» в коллекции с большим числом элементов нужно использовать с осторожностью, так как поиск производится полным перебором коллекции. Оптимальным вариантом для оптимизации поиска в массиве может быть использование соответствия (map) вместо массива. В этом случае накладные расходы на создание соответствия окупятся значительно более быстрым поиском нужного значения в коллекции.
Для таблицы значений, как правило, помогает индексация полей поиска вкупе с использованием метода «НайтиСтроки». Не забывайте, что индексы нужно создавать под такие сочетания полей поиска, которые вы используете.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
2 Классификация ошибок
Классификация есть обобщение массива ошибок с целью облегчения работы с ними. Классификация является наглядным примером абстракции с её достоинствами и недостатками. Структурирование и обобщение больших объемов данных, позволяет их легче обрабатывать и осознавать. От осознания очень сильно зависит качество работы интуиции. Чем глубже понимание базиса вещей, тем чаще случаются «внезапные озарения». Но не стоит забывать о недостатках абстракций и всегда иметь их ввиду.
Видов классификации может быть больше, чем число ошибок, поэтому обобщение классификаций для практических нужд я выполняю по функциональному назначению. В рамках такого подхода выделяются две основные функции классификации:
Управление процессом обнаружения и исправления ошибок.
При значительном количестве ошибок, применение классификации многократно повышает эффективность их исправления. В основном это достигается за счет облегчения идентификации и локализации. При налаженной статистике появляется возможность работы на упреждение – исправление ошибок до их возникновения у конечного пользователя.
Распределение трудовых ресурсов
Является частным случаем управления ошибками, но ввиду распространенности и полезности, не нуждающейся в особых доказательствах, я выделяю эту функцию отдельно. На больших проектах или в штате крупных предприятий суммарная трудоёмкость на исправление ошибок (если их действительно регистрировать) может существенно превышать доступную ёмкость фонда рабочего времени. Также, разные специалисты с разной эффективностью решают различные проблемы: кто-то въедлив и усидчив и легче находит даже хорошо спрятанные ошибки, кто-то хорошо владеет языком и может превратить невнятный запутанный код в ясное изложение. Таким образом, классификация ошибок будет хорошим подспорьем в деле распределения трудовых ресурсов.
В зависимости от специфики предприятия или отдельного проекта, могут применяться различные классификации. Здесь я опишу базовые и некоторые специальные классификации, которые мне приходилось использовать. Прошу обратить особое внимание на определение классификации и их типизацию по функциональному назначению. Не стоит создавать детальную классификацию по принципу «чтобы было», там, где достаточно простой и обобщенной. Если в классификации будет множество неиспользуемых деталей, то со временем, она из помощника превратится в тяжелую повинность и инструмент угнетения.
Здесь будут описаны применявшиеся в реальной практике классификации и сценарии их использования.
Это основная и во многих случаях достаточная классификация. Её суть следует из самого определения ошибки, и эта классификация уже была определена в предшествующих лекциях. Здесь я сделаю финальное определение базовой классификации: все ошибки получают оценку по каждому из трёх критериев качества программы. При этом, из Работоспособности, может выделяться быстродействие, остальные свойства – по необходимости.
Имея информацию о свойствах ошибки, мы можем принимать осознанные решения о концентрации усилий на том или ином направлении. Если ошибки, влияющие на сопровождаемость обнаружены в модуле, который уже давно не редактируется и практически не используется, то нет никаких оснований бросаться на него, при наличии другой работы, но если это активно используемый или часто изменяемый код, то обеспечить его сопровождаемость будет крайне необходимо. Или, наоборот, имея данные наблюдений о низком быстродействии программы, мы будем внимательнее рассматривать ошибки, влияющие на быстродействие.
Классификация по терпимости ошибки
Данная классификация является расширением базовой классификации, т.к. наследует из нее всё те же критерии, но расчет интегральной стоимости ошибки производится по индивидуальному алгоритму, либо с использованием коэффициента.
Подобный подход, необходим для лучшей адресации усилий по исправлению ошибок. Несложно представить, что ошибки с одинаковой интегральной стоимостью могут находиться в разных разделах программы с разной чувствительностью к ошибкам. Например, для проектной команды, получающей оплату по итогам промежуточной приёмки, демонстрация функциональности или рабочий стол директора/собственника, это не то время и место, где они хотели бы увидеть ошибки. А фикси программист, будет иметь много проблем если из-за небольшой ошибки с низким приоритетом, остановился или замедлился важный процесс предприятия. Следовательно, необходима уточняющая классификация, позволяющая двигать действительно критичные ошибки вверх по шкале приоритетов. Даже при отсутствии автоматизированной оценки, всегда остаётся возможность принудительно сделать исправление ошибки сверхприоритетным. Если же углубиться в построение инструментов, то для места возникновения ошибки, можно определить коэффициент (0,5 или 2) или особую формулу («всегда самый высокий» или «ставим в самый низ»).
За скобками я оставляю концепцию управления рисками, но необходимо иметь ввиду, что управление рисками как система, напрямую взаимодействует с данной классификацией, даже если управление рисками происходит только в голове единственного в штате фикси-разработчика.
Классификация по трудоёмкости исправления
Оценочная трудоемкость является общим инструментом в планировании работ, а если принять трудоемкость как стоимость в ресурсах, то планирования вообще. Таким образом, если необходимость в планировании назрела, то работа с оценкой трудоемкости является одним из важнейших инструментов.
В практике программирования, зачастую, это достаточно сложная для полноценного применения классификация. Сложность заключается в низкой точности предварительной оценки трудоёмкости. Чтобы точность повысить, отделу разработки необходимо перейти на качественно иной уровень, когда точность оценки достаточно высока для детального планирования. Но и с низкой точностью предсказания есть возможность использовать классификацию, как минимум, для определения приоритетов. Например, у вас есть 10 ошибок примерно одинаковой вредности. Но одна из них предварительно оценивается в 40 часов, тогда как остальные, даже по пессимистичным оценкам укладываются в 1-8 часов. В большинстве случаев, оптимальным решением будет «поискать под фонарём» — в первую очередь обработать те ошибки, которые можно быстро исправить. Причина проста — затратив те же 40 часов или меньше, вы исправите девять ошибок а не одну. При этом шанс выбиться из графика много ниже. Ведь не стоит забывать, что сложно оценить трудоёмкость более 16 часов без декомпозиции, и вполне возможно, что 40 часов это довольно оптимистичный прогноз. Также, большой объем изменений предполагает более объемное тестирование, и потенциально может увеличить затраты времени в несколько раз. Даже если затраты будут связаны с выявлением ранее не обнаруженных ошибок, которые в старом ошибочном коде не воспроизводились, то это всё равно затраты времени, вызванные исправлением одной ошибки.
Если же вы способны точно оценивать трудоёмкость, то все инструменты планирования становятся доступны. Наиболее ценными в моей практике являлись два инструмента:
— составление графика релизов и план-графика по проектам. Речь идет о действительно точных графиках, а не о наборе пожеланий и обещаний, выполняемых ценой авралов и превозмоганий.
— балансировка нагрузки разработчиков и составление индивидуальных планов. В своё время проводил опыты с линейным программированием, но, к сожалению, не хватило времени довести их до конца. Но так или иначе, для черновых расчетов использовал методы линейного программирования.
Соображения в пользу применения подобной классификации весьма просты – любой процесс планирования очень сильно упрощается при сокращении числа неизвестных, особенно если эта неизвестная одна из основ планирования.
Классификация по пригодности к формализации
На практике эта классификация довольно проста, но всё зависит от организации процесса, поэтому помимо особенностей классификации я опишу методику применения.
Основное назначение данной классификации – автоматизация поиска ошибок. Всякий раз находя ошибку в релизе, есть большое желание в следующий раз найти её автоматическими средствами еще на этапе разработки. Это далеко не всегда удаётся, но если ошибка была формализована хотя бы частично, то её обнаружение значительно облегчится, т.к. в голове уже будет готовый паттерн.
В моей практике эта классификация применялась следующим образом: при регистрации новой ошибки производилась её типизация. Если ошибка встречалась ранее, то проверяется уровень её формализации и по необходимости уточняется. Если ошибка ранее не встречалась, то описывается новый тип ошибки с неизвестным уровнем формализации. Специально назначенный человек по запросу или по расписанию проверяет пригодность к формализации. Полностью формализуемые ошибки рано или поздно попадают в средства автоматической проверки, частично формализуемые в паттерны поиска ошибок (инструкции разработчикам) и иногда в автоматические проверки, если число ложных срабатываний не слишком велико, чтобы замусорить отчеты о проверке.
Приведу уровни формализации, обычно используемые в описанной схеме:
— Не определен
— Не поддаётся формализации. Стараться избегать такого определения. Это или лень или очень-очень плохой код.
— Формализуется частично. Такой уровень пригоден для ручного использования.
— Полностью формализуется. Этот уровень — показание к полной автоматизации поиска ошибки.
— Внедрено в автоматические средства проверки. В идеале, ошибки с таким уровнем формализации не должны попадаться позже этапов разработки и тестирования, но всё в ваших руках.
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Дополнительные материалы
Алгоритм отладки
-
Проверь гипотезу — если гипотеза проверку не прошла то п.3.
-
Убедись что исправлено — если не исправлено, то п.3.
Подробнее ознакомиться с ним можно в докладе Сергея Щегриковича «Отладка как процесс».
Чем искать ошибки, лучше не допускать ошибки. Прочитайте статью «Качество вместо контроля качества», чтобы узнать как это делать.
Логические ошибки
Логические ошибки происходят, когда программа неправильно выполняет то, для чего она была создана. Ошибки этого рода возникают по многим различным причинам. Допустим, вы написали программу, которая конвертирует 35 градусов Цельсия в градусы Фаренгейта следующим образом:
public class ShowLogicErrors {
public static void main(String[] args) {
System.out.println("Celsius 35 is Fahrenheit degree ");
System.out.println((9 / 5) * 35 + 32);
}
}

Вы получите 67 градусов по Фаренгейту, что является неверным. Должно быть 95.0. В Java целочисленное деление показывает только часть – дробная часть отсекается, по этой причине в Java 9 / 5 это 1. Для получения правильного результата, нужно использовать 9.0 / 5, что даст результат 1.8.
Обычно ошибки синтаксиса легко обнаружить и легко исправить, поскольку компилятор даёт указания откуда пришла ошибка и что не так. Ошибки во время выполнения не трудны для поиска, поскольку причина и место для этих ошибок также показывается в консоли во время прерывания программы. Поиск логических ошибок, в свою очередь, очень сложный. В последующих главах вы обучитесь техникам трассировки программ и поиска логических ошибок.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
Expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Как обнаружить ошибку
Прочитай информацию об исключении
Если выполнение программы прерывается исключением, то это первое место откуда стоит начинать поиск.
В каждом языке есть свои способы уведомления об исключениях. Например в JavaScript для обработки ошибок связанных с Web Api существует DOMException. Для пользовательских сценариев есть базовый тип Error. В обоих случаях в них содержится информация о наименовании и описании ошибки.
Для .NET существует класс Exception и каждое исключение в приложении унаследовано от данного класса, который представляет ошибки происходящие во время выполнения программы. В свойстве Message читаем текст ошибки. Это даёт общее понимание происходящего. В свойстве Source смотрим в каком объекте произошла ошибка. В InnerException смотрим, нет ли внутреннего исключения и если было, то разворачиваем его и смотрим информацию уже в нём. В свойстве StackTrace хранится строковое представление информации о стеке вызова в момент появления ошибки.
Каким бы языком вы не пользовались, не поленитесь изучить каким образом язык предоставляет информацию об исключениях и что эта информация означает.
Всю полученную информацию читаем вдумчиво и внимательно. Любая деталь важна при поиске ошибки. Иногда начинающие разработчики не придают значения этому описанию. Например в .NET при возникновении ошибки NRE с описанием параметра, который разработчик задаёт выше по коду. Из-за этого думает, что параметр не может быть NRE, а значит ошибка в другом месте. На деле оказывается, что ошибки транслируют ту картину, которую видит среда выполнения и первым делом за гипотезу стоит взять утверждение, что этот параметр равен null. Поэтому разберитесь при каких условиях параметр стал null, даже если он определялся выше по коду.
Пример неявного переопределения параметров — использование интерцептора, который изменяет этот параметр в запросе и о котором вы не знаете.
Разверните стек
Когда выбрасывается исключение, помимо самого описания ошибки полезно изучить стек выполнения. Для .NET его можно посмотреть в свойстве исключения StackTrace. Для JavaScript аналогично смотрим в Error.prototype.stack (свойство не входит в стандарт) или можно вывести в консоль выполнив console.trace(). В стеке выводятся названия методов в том порядке в котором они вызывались. Если то место, где падает ошибка зависит от аргументов которые пришли из вызывающего метода, то если развернуть стек, мы проследим где эти аргументы формировались.
Загуглите текст ошибки
Очевидное правило, которым не все пользуются. Применимо к не типовым ошибкам, например связанным с конкретной библиотекой или со специфическим типом исключения. Поиск по тексту ошибки помогает найти аналогичные случаи, которые даже если не дадут конкретного решения, то помогут понять контекст её возникновения.
Прочитайте документацию
Если ошибка связана с использованием внешней библиотеки, убедитесь что понимаете как она работает и как правильно с ней взаимодействовать. Типичные ошибки, когда подключив новую библиотеку после прочтения Getting Started она не работает как ожидалось или выбрасывает исключение. Проблема может быть в том, что базовый шаблон подключения библиотеки не применим к текущему приложению и требуются дополнительные настройки или библиотека не совместима с текущим окружением. Разобраться в этом поможет прочтение документации.
Проведите исследовательское тестирование
Если используете библиотеку которая не работает как ожидалось, а нормальная документация отсутствует, то создайте тесты которые покроют интересующий функционал. В ассертах опишите ожидаемое поведение. Если тесты не проходят, то подбирая различные вариации входных данных выясните рабочую конфигурацию. Цель исследовательских тестов помочь разобраться без документации, какое ожидаемое поведение у изучаемой библиотеки в разных сценариях работы. Получив эти знания будет легче понять как правильно использовать библиотеку в проекте.
Бинарный поиск
В неочевидных случаях, если нет уверенности что проблема в вашем коде, а сообщение об ошибке не даёт понимания где проблема, комментируем блок кода в котором обнаружилась проблема. Убеждаемся что ошибка пропала. Аналогично бинарному алгоритму раскомментировали половину кода, проверили воспроизводимость ошибки. Если воспроизвелась, закомментировали половину выполняемого кода, повторили проверку и так далее пока не будет локализовано место появления ошибки.
10 Клиент-сервер.
Формализуется частично, влияет на производительность. Исправление может влиять на сопровождаемость.
Необоснованные серверные вызовы
Частые контекстные серверные вызовы, там, где можно обойтись внеконтекстным. Например, нужно получить текущий курс валют. На форме есть ссылка на валюту. Чтобы получить курс на дату достаточно выполнить внеконтекстный вызов сервера и передать валюту и дату в качестве параметров. Здесь будет произведена передача одной ссылки и одного примитивного типа на сервер и возврат другого примитивного типа. В случае контекстного вызова сервера, на сервер вытягивается вся форма, при этом все её данные дважды пройдут процедуру сериализации/десериализации при миграции на сервер и обратно.
Необоснованная передача параметров по ссылке
Если вам не нужно редактировать переданные параметры, то передавать их нужно по значению. Иначе процедура сериализации/десериализации параметров будет выполнена дважды! И если для примитивных типов это фактически бесплатно, то для ссылочных типов это довольно дорогая операция. В любом случае, нужно взять за правило, что если параметр не должен измениться, то незачем передавать его по ссылке.
1 Запрос в цикле
Формализуется, влияет на производительность, исправление влияет на сопровождаемость и гибкость
В большинстве случаев можно обойтись одним запросом, который сразу выдаст необходимые данные для обработки. В некоторых случаях запросы в цикле применяются осознанно, по различным причинам. Иногда, несколько запросов в цикле могут выполняться быстрее чем один большой запрос, также потеря производительности может быть признана несущественностью и код перерабатывается в пользу большей читаемости и гибкости. Это довольно скользкая дорожка, поэтому очевидно опасные решения должны быть хорошо обоснованы.
Проверь себя
- Что такое синтаксические ошибки (ошибки компилятора), ошибки во время работы и логические ошибки?
- Приведите примеры синтаксических ошибок, ошибок во время выполнения и логических ошибок?
- Если вы забыли написать закрывающую кавычку для строки, какого рода ошибка возникнет?
- Если ваша программа должна считать целое число, но пользователь ввёл строку, возникнет ли ошибка во время работы программы? Если да, то какого рода это ошибка?
- Предположим вы пишите программу для вычисления периметра прямоугольника, но по ошибке написали программу, которая вычисляет площадь прямоугольника. Какого рода эта ошибка?
- Выявите и исправьте ошибки в следующем коде:
public class Welcome {
public void Main(String[] args) {
System.out.println('Welcome to Java!);
}
}
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
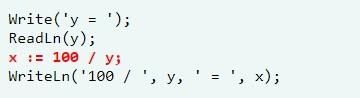
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
5 Безусловная выгрузка запроса в ТЗ
Формализуется частично, влияет на производительность
Использование выгрузки в таблицу значений результата запроса, там, где достаточно обхода выборки. Накладные расходы на создание таблицы значений в сумме с последующим обходом строк в несколько раз превышают (от 2х и более) накладные расходы на получение и обход выборки из результата запроса. Причина проста — результат запроса уже сам по себе является таблицей, а выборка всего лишь инструмент по удобной работе с этой таблицей, и работая с результатом запроса при помощи выборки, вы не выполняете никаких лишних операций, выгружая же результат запроса в таблицу значений, вы фактически копируете одну таблицу в другую, со всеми накладными расходами на инициализацию, заполнение и хранение.
7 Оператор «Выполнить» и функция «Вычислить»
Необоснованное применение в нагруженных алгоритмах
Формализуется частично, влияет на производительность, исправление влияет на сопровождаемость и гибкость
Необходимо помнить, что подобные конструкции выполняются очень медленно и употреблять их в рабочей базе следует осмотрительно, иначе возможно многократное падение производительности. Подобные конструкции рекомендуется использовать для однократного вызова обработчиков, имя которых заранее неизвестно. Например, они часто используются при печати, где падение быстродействия не ощутимо, а гибкость кода повышается существенно.
Например данный код
А = 0;
Для Сч = 1 По N Цикл
Выполнить(«А = А + 1»);
Будет выполняться дольше чем:
А = 0;
И по мере увеличения N разница будет расти.
Выполнение произвольного кода, введенного пользователем
Формализуется частично, влияет на безопасность, исправление влияет на сопровождаемость и гибкость
Если ваш продукт не является инструментом разработчика, то категорически нельзя выполнять код, введенный пользователем. Даже если он должен ввести имя реквизита или формулу. Выполняя неизвестный код или его фрагмент, вы открываете свою базу для вредоносных инъекций.
Получение именованных реквизитов
Формализуется частично, влияет на производительность
2 Неявный запрос
Формализуется, влияет на производительность, исправление влияет на сопровождаемость и гибкость
Неявные запросы в том числе в циклах, происходят всякий раз:
— при обращении к свойствам ссылки через точку
— при использовании методов «НайтиПо»
Сами по себе неявные запросы, позволяют сократить объем кода и повысить его читаемость. Именно ради этого разработчики языка 1С и задумывали подобные, небезопасные инструменты. Если данные методы сознательно используются, то за ними необходимо наблюдение – они могут стать узким местом.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
1 Методики поиска и классификации ошибок
Данная статья является компиляцией материала трёх лекций, посвященных ошибкам. Такой формат выбран отчасти из-за нехватки времени, отчасти из-за нежелания спамить статьями и также из-за постоянного желания улучшить и так неплохое.
Так как курс нацелен на повышение качества программы, нам необходимо понимание того, что приводит к его снижению. Эта лекция в нескольких приближениях даст образы «врага». От простого и четкого, до более сложного и подробного. Помимо этого, в специальном разделе, будут приведены примеры типичных ошибок, способы исправления и обхода.
Хочу напомнить, что несмотря на то, что рекомендации так или иначе исходят их опыта работы отдела разработки или проектной команды, излагаемые принципы и методики легко масштабируются до отдельного программиста.
Дебаг и поиск ошибок

Для опытных разработчиков информация статьи может быть очевидной и если вы себя таковым считаете, то лучше добавьте в комментариях полезных советов.
По опыту работы с начинающими разработчиками, я сталкиваюсь с тем, что поиск ошибок порой занимает слишком много времени. Не из-за того, что они глупее более опытных товарищей или не разбираются в процессах, а из-за отсутствия понимания с чего начать и на чём акцентировать внимание. В статье я собрал общие советы о том где обитают ошибки и как найти причину их возникновения. Примеры в статье даны на JavaScript и .NET, но они актуальны и для других платформ с поправкой на специфику.
6 Неверное употребление оператора «Попытка…Исключение»
Формализуется частично, влияет на надёжность, быстродействие и сопровождаемость, исправление влияет на сопровождаемость
Как правило, такие вещи появляются при ошибках в выполнении кода и нежелании разбираться почему они происходят. Наиболее часто встречается попытка записи в БД. Здесь два варианта действий:
а) если ход выполнения программы не допускает прерывания работы программы исключением (например, массовая обработка данных), то постарайтесь чтобы исключение в попытке срабатывало только при физических проблемах с записью (блокировки, база недоступна и.т.д.). Проверки заполнения и корректности полей объекта должны быть выполнены до выполнения попытки. Разумеется, это потребует вынесения проверок в отдельный метод, позволяющий его использование из разных мест, но выигрыш быстродействия на записи будет очевидным.
б) если контекст выполнения программы допускает возникновение исключений (например, при интерактивной работе пользователя), то в исключительных случаях нужно позволить ошибке произойти. Конечно, исключение приведет к остановке выполнения кода, но оно также сообщит важную информацию пользователю о причинах ошибки. Принудительная обработка исключений в таких ситуациях имеет смысл только для записи дополнительной информации в ЖР и/или переопределения описания исключения для вывода пользователю более наглядной и понятной информации.
Главное, что нужно понимать — отсутствие исключений, не означает отсутствие ошибок, и бездумно перехватывая исключения, вы создаёте новые, трудноуловимые ошибки.