
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
Принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
Методы отладки
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Тестирование
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
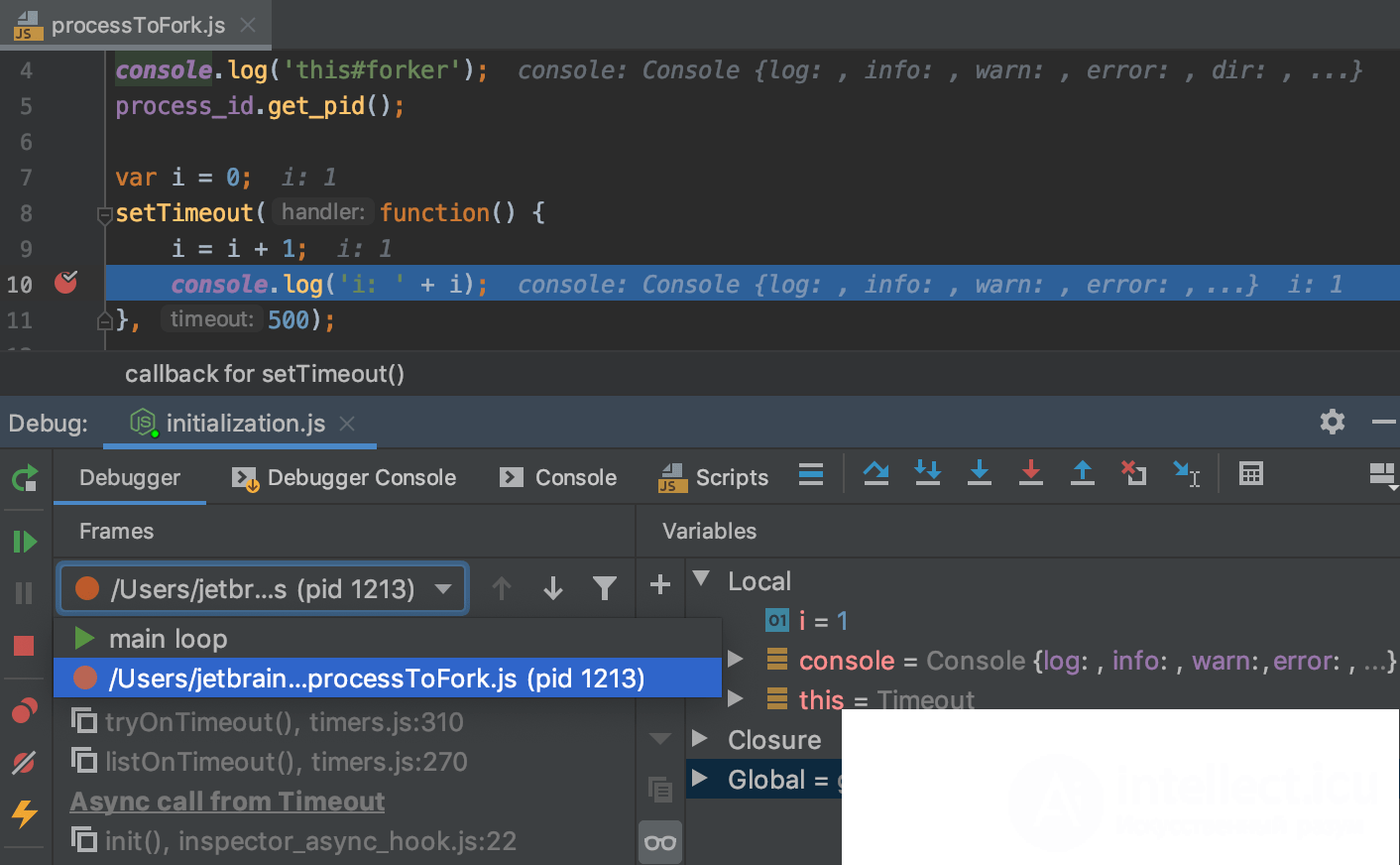
Рис Пример отладки приложения
Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
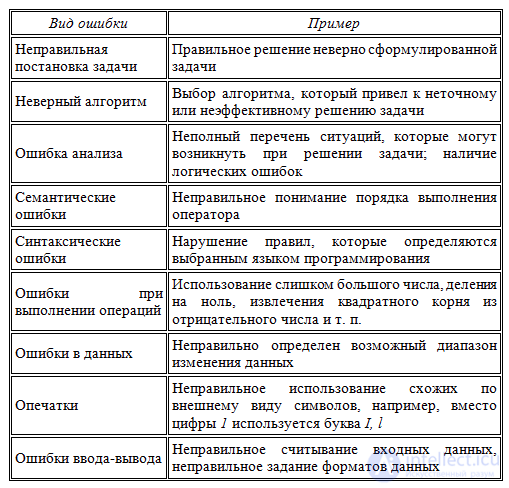
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
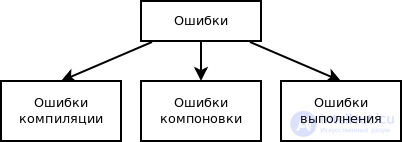
Классификация ошибок по этапу обработки программы
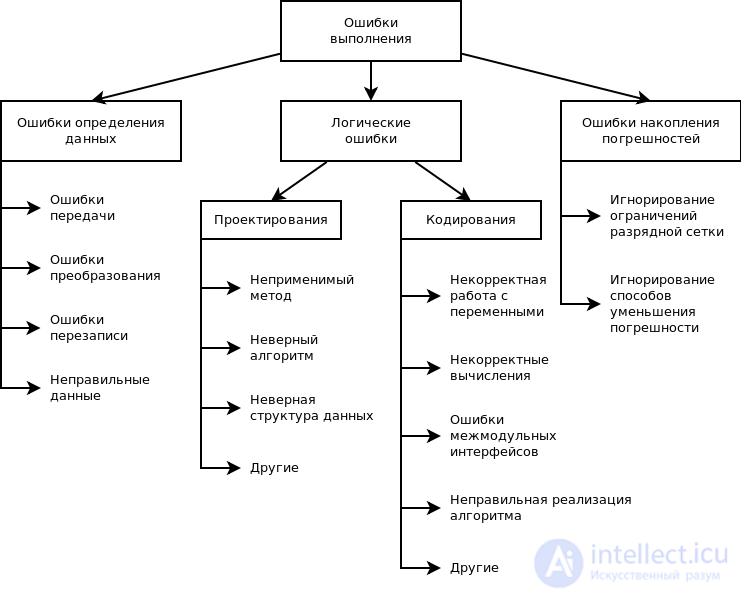
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
8) Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Ошибки в программах – дело обыденное. Приложения зависают, вылетают, перестают запускаться. В простейшем случае пользователь решает проблему переустановкой ПО или чисткой от «мусора». Разработчикам же нужно четко понимать, что такое баг, как исправить его и каким образом получить своевременную обратную связь от пользователей.
Что такое баг?
Термин «баг» (в переводе «жук») у программистов обозначает ситуацию, когда определенный код выдает неверный результат. Причины возникновения разные: ошибки в исходном коде, интерфейсе программы или некорректной работе компилятора. Обнаруживают их на этапе отладки или уже на стадии бета-тестирования, выпуска продукта на рынок.
- Появилось сообщение об ошибке, программа продолжает работу.
- Приложение зависает или вылетает без каких-либо предупреждений.
- Происходит одно из событий с одновременной отправкой отчета разработчику.
Сложнее всего работать с компьютерными играми, в которых чаще используют термин «краш» (crash). Он означает критическую проблему при запуске или использовании программы. Когда говорят о багах, то чаще имеют в виду сбои графики, например, если игрок «проваливается в текстуры».
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Классификация багов
Точка зрения пользователей часто не совпадает с мнением программистов. Так, для первых всего лишь произошел сбой, «приложение перестало работать». Кодеру же предстоит головная боль с определением источника проблемы. Ведь ошибка в программе, вероятно, проявляется лишь на конкретном железе или при сочетании с другим софтом (часто с антивирусами).
Баги делят на категории в зависимости от их критичности:
- незначительные ошибки,
- серьезные ошибки,
- showstopper.
Также есть деление ошибок по частоте проявления. Проще всего исправлять постоянные, возникающие при одних и тех же обстоятельствах, независимо от платформы, аппаратной части компьютера или каких-то действий пользователя. Сложность возрастает при периодических сбоях, когда причиной вполне может оказаться глючная оперативная память или ошибки накопителей.
Есть вариант, когда проблема возникает только на машине конкретного клиента. Здесь приходится либо заказывать индивидуальную «работу над ошибками», либо менять компьютер. Потому что ПО для массового пользователя никто не будет редактировать из-за «одного». Только если наберется некая критическая масса одинаковых случаев.
Разновидности ошибок
Программисту еще важно деление на разные типы ошибок приложений исходя из типовых условий их эксплуатации. Например, возникающие при повышении нагрузки на процессор, в интерфейсе, в модуле обработки входящих данных. Существуют баги граничных условий, сбоя идентификаторов, банальной несовместимости с архитектурой процессора (чаще в мобильных устройствах).
Кодеры делят ошибки по сложности:
- Борбаг (Bohr Bug) – «стабильная» ошибка, легко выявляемая еще на этапе отладки или при бета-тестировании, когда речь еще не идет о выпуске стабильной версии.
- Гейзенбаг (Heisenbug) – периодически проявляющиеся, иногда надолго исчезающие баги с меняющимися свойствами, включая зависимость от программной среды, «железа».
- Мандельбаг (Mandelbug) – ошибка с энтропийным поведением, почти с непредсказуемым результатом.
- Шрединбаг (Schroedinbug) – критические баги, чаще приводящие к появлению возможности взлома, хотя внешне никак себя не проявляют.
Последняя категория ошибок – одна из основных причин регулярного обновления операционных систем Windows. Вроде бы пользователя все устраивает, а разработчик раз за разом выпускает новые пакеты исправлений. Наиболее известный баг, попортивший нервы многим кодерам, это «ошибка 2000 года» (Y2K Error). Про нее успешно забыли, но уроки извлекли.
Программисты различают и те ошибки, что мешают скомпилировать программу, и ворнинги. Вторая категория представляет собой лишь предупреждение о найденных «косяках» в коде, но они не мешают ни сборке ПО, ни последующей эксплуатации. Например, речь идет об отсутствии точки или точки запятой в синтаксисе, когда компилятор способен сам решить проблему.

Логические
Наиболее серьезная из ошибок. Такие баги приводят к изменению функционирования программы вопреки техническому заданию. К чему это приведет, никто не знает – могут записаться на диске «не те данные», некорректно измениться важные документы или предоставиться доступ к коммерческой информации без авторизации. Исправить их получится только при знании изначальной логики.
Ошибки синтаксиса существуют на уровне конкретного языка программирования: C, Java, Python, Perl и т.д. Что на одной платформе работает максимум с ворнингами, для другой будет серьезной проблемой. Такие баги легко исправить на этапе компиляции, потому что инструмент не позволит «пройти дальше» некорректного участка кода.
Компиляционные
Ситуация происходит, когда код, написанный на языке высокого уровня, преобразуют в «простой», машиночитаемый. Причиной может служить как серьезная ошибка в синтаксисе, так и сбои в самом компиляторе. Такие баги устраняют на этапе разработки-отладки программ, потому что выпустить их даже для бета-тестирования не получится.
Среды выполнения
Так называемые ошибки Run-Time. Проявляются в скомпилированных программах, при запуске. Например, из-за нехватки ресурсов на машине, в результате аварийной ситуации (поломка памяти, носителя, устройств ввода-вывода). Такое происходит, если разработчик не учел реальных условий работы; придется вернуться к стадии проработки логики.
Арифметические
Одна из разновидностей логических ошибок. Происходят, когда программа при работе вычисляет массу переменных, но на каком-то этапе происходит непредвиденное. Например, деление на ноль или же приложение получает «бесконечный» результат. Изменить ситуацию получится только на уровне кода, внедренного в него алгоритма.
Ресурсные
Преимущественно к этой категории относят ошибки типа «переполнение буфера». Программист не учел необходимость очистки памяти перед размещением новых данных. Или интерфейс разработан без учета типовых разрешений экранов, и его элементы постоянно «съезжают», нарушается логика срабатывания кнопок и т.д. Исправить получится только переписыванием части кода.
Взаимодействия
Речь идет о взаимодействии с аппаратным или программным окружением. В случае с приложением для облачного ресурса программист мог допустить ошибку при использовании веб-протоколов. При постоянном появлении ошибки остается только переписывать участок кода, ответственный за появление бага, иначе программа останется неработоспособной.
Что такое исключение
Снизить риски появления непредвиденных ошибок позволяет внедрение в программу исключений. Это события, при возникновении которых начинается «неправильное» поведение. Такой механизм позволяет систематизировать обработку багов независимо от типа приложения, платформы и иных условий. И разработать единую систему реагирования, например, со стороны операционки.
Существуют программные и аппаратные исключения. Первые генерируются самой программой и ОС, под которой она запущена. К аппаратным относятся те, что создаются процессором. Например, деление на 0, переполнение буфера, обращение к невыделенной памяти. Исключениями кодеры охватывают наиболее серьезные, критические баги.
Как избежать ошибок?
Существует два эффективных способа избежать проблем еще на стадии разработки. Первый – это отладка при помощи специальных программ. Они отображают результаты выполнения в цифрах, которые объективно показывают кодеру, правильно ли был обработан следующий участок кода или нужно искать закравшуюся ошибку.
Второй способ представляет собой привлечение специальных людей, тестировщиков. Они помогут разобраться с работоспособностью интерфейса в различных ситуациях, на разных платформах. Это происходит максимально приближенно к реальным условиям. Поэтому любой серьезный продукт проходит такую стадию обязательно.
Выводы
Баги – сопутствующий фактор любой разработки. Большую их часть пользователь не видит, потому что устраняются они еще в «лаборатории», на этапе альфа-тестирования. В бета-версии попадают уже незначительные ошибки, например, связанные с конкретными «узкими» условиями эксплуатации. Редкие проблемы помогают решать краш-репорты – отчеты, отсылаемые производителю самой программой.
Привет, Вы узнаете про регрессионное тестирование, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
регрессионное тестирование, regression testing , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
— это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде (см. также Санитарное тестирование или проверка согласованности/исправности). Регрессионными могут быть какфункциональные, так и нефункциональные тесты.
Как правило, для регрессионного тестирования используются тест кейсы, написанные на ранних стадиях разработки и тестирования. Это дает гарантию того, что изменения в новой версии приложения не повредили уже существующую функциональность. Рекомендуется делатьавтоматизацию регрессионных тестов, для ускорения последующего процесса тестирования и обнаружения дефектов на ранних стадиях разработки программного обеспечения.
Сам по себе термин «Регрессионное тестирование», в зависимости от контекста использования может иметь разный смысл. Сэм Канер, к примеру, описал 3 основных типа регрессионного тестирования:
- Регрессия багов (Bug regression) — попытка доказать, что исправленная ошибка на самом деле не исправлена
- Регрессия старых багов (Old bugs regression) — попытка доказать, что недавнее изменение кода или данных сломало исправление старых ошибок, т.е. старые баги стали снова воспроизводиться.
- Регрессия побочного эффекта (Side effect regression) — попытка доказать, что недавнее изменение кода или данных сломало другие части разрабатываемого приложения
Регрессио́нное тести́рование (англ. regression testing, от лат. regressio — движение назад) — собирательное название для всех видов тестирования программного обеспечения, направленных на обнаружение ошибок в уже протестированных участках исходного кода. Такие ошибки — когда после внесения изменений в программу перестает работать то, что должно было продолжать работать, — называют регрессионными ошибками (англ. regression bugs).
Из опыта разработки ПО известно, что повторное появление одних и тех же ошибок — случай достаточно частый. Иногда это происходит из-за слабой техники управления версиями или по причине человеческой ошибки при работе с системой управления версиями. Но настолько же часто решение проблемы бывает «недолго живущим»: после следующего изменения в программе решение перестает работать. И наконец, при переписывании какой-либо части кода часто всплывают те же ошибки, что были в предыдущей реализации.
Поэтому считается хорошей практикой при исправлении ошибки создать тест на нее и регулярно прогонять его при последующих изменениях программы. Хотя регрессионное тестирование может быть выполнено и вручную, но чаще всего это делается с помощью специализированных программ, позволяющих выполнять все регрессионные тесты автоматически. В некоторых проектах даже используются инструменты для автоматического прогона регрессионных тестов через заданный интервал времени. Обычно это выполняется после каждой удачной компиляции (в небольших проектах) либо каждую ночь или каждую неделю.
Регрессионное тестирование является неотъемлемой частью экстремального программирования . Об этом говорит сайт https://intellect.icu . В этой методологии проектная документация заменяется на расширяемое, повторяемое и автоматизированное тестирование всего программного пакета на каждой стадии процесса разработки программного обеспечения.
Использование
Регрессионное тестирование может быть использовано не только для проверки корректности программы, часто оно также используется для оценки качества полученного результата. Так, при разработке компилятора при прогоне регрессионных тестов рассматривается размер получаемого кода, скорость его выполнения и время компиляции каждого из тестовых примеров.
В своей статье S. Yoo and M. Harman предоставляют следующую классификацию регрессионного тестирования:
- Минимизация набора тестов (англ. test suite minimization) стремится уменьшить размер тестового набора за счет устранения избыточных тестовых примеров из тестового набора.
- Задача определения приоритетов теста (англ. test case prioritization). Ее цели заключаются в выполнении заказанных тестов на основе какого-либо критерия. Например, на основе истории, базы или требований, которые, как ожидается, приведут к более раннему выявлению неисправностей или помогут максимизировать некоторые другие полезные свойства.
- Задача выбора теста (англ. test case selection) связана с проблемой выбора подмножества тестов, которые будут использоваться для проверки измененных частей программного обеспечения. Для этого требуется выбрать подмножество тестов из предыдущей версии, которые могут обнаруживать неисправности, основываясь на различных стратегиях. Большинство задокументированных методов регрессионного тестирования сосредоточены именно на этой технике. Обычная стратегия состоит в том, чтобы сосредоточить внимание на отождествления модифицированных частей SUT (англ. SUT — system under test ) и для выбора тестовых случаев, имеющих отношение к ним. Например, техника полного повторного тестирования (англ. retest-all) – один из наивных типов выбора регрессивного теста путем повторного выполнения всех видов тестов от предыдущей версии на новой. Она часто используется в промышленности из-за ее простого и быстрого внедрения. Тем не менее, ее способность обнаружения неисправностей ограничена. Таким образом, значительный объем работ связан с разработкой эффективных и масштабируемых селективных методов.
- Гибридный тест. Является сочетанием задач на определение приоритетов и выбора.
Задача минимизации наборов
Тест минимизации наборов стремится уменьшить размер тестового набора путем устранения тестовых случаев из набора тестов на основе данного критерия. Существует три подхода, первый из которых применяет автоматизированное тестирование безопасности для обнаружения уязвимостей путем изучения неисправностей приложений, которые могут выявлять известные вредоносные программы, как вирусы или черви. Этот подход учитывает только проваленные тесты из предыдущей версии для повторного запуска в новой версии системы после устранения неисправности.
Другой же подход предназначен для обнаружения и устранения уязвимостей второстепенных релизов веб-приложений. В нем настраивается жесткая связь со страницами предыдущей версии при помощи итераторов, которые выбираются для изучения веб-страниц, которые содержат уязвимости.
И, наконец, третий подход предлагает тестирование с самоадаптацией системы для уже известных неудач. Авторы избегают воспроизведения уже известных ошибок, рассматривая только те тесты для выполнения, которые выявили известные неудачи в предыдущих версиях.
Задача с определением приоритетов
Тестовая задача на определение приоритетов касается правильного упорядочения тестов, что максимизирует желаемые свойства, такие как раннее выявление неисправностей. Кроме того, в настоящее время подходы к расстановке приоритетов рассматривают только уязвимости.
Один из методов предлагает основанные на ошибках приоритетные тесты, которые непосредственно используют знание об их способности обнаруживать неисправности.
Другой же предлагает изменяемую систему записи-воспроизведения, которая позволяет переписать записанную исполненную версию приложения в новую, модифицированную. Их выполнение является приоритетным из-за определения оптимального изменяемого переписывания на основе функции затрат и измерения разности между первоначальным исполнением и измененным при повторе.
Задача выбора тестов
Метод выбора позволяет выбрать подмножество или все тестовые случаи, чтобы проверить измененные части программного обеспечения. Следующие подходы тестируют механизмы и безопасности, и уязвимости.
- Подход, основанный на диаграмме состояния (UML-based), регрессионного тестирования для требований безопасности аутентификации, конфиденциальности, доступности, авторизации и целостность. Тесты, представленные в виде диаграммы последовательности, выбираются на основе теста изменения требований.
- Подход к улучшению регрессионного тестирования на основе нефункциональных требований онтологий. Тесты выбираются на основе изменений и воздействий анализа нефункциональных требований, таких как безопасность, производительность и надежность. Каждый тест связан с измененным требованием, которое выбирается для регрессивного тестирования.
- Подход для обеспечения проверки дополнительных доказательств для сертификации требований безопасности услуг. Этот подход основан на обнаружении изменений в тестовой модели обслуживания, которая будет определять, должны ли быть созданы новые тестовые случаи или существующие будут отобраны для повторного выполнения на выделенном сервисе.
- Подход к разработке безопасных систем оцениваемых по общим критериям. В этом подходе тестовые задания по требованиям безопасности создаются вручную и представлены в виде диаграммы последовательности. В случае изменения при необходимости пишутся новые тесты, а затем все тесты выполняются на новой версии.
- Подход к требованиям тестирования безопасности веб-сервиса релизов. Пользователь службы может периодически повторно выполнить набор тестов, направленных против сервиса чтобы проверить, что пользователь по-прежнему обладает правильными правами.
- Coverage-based метод отбора для эволюционного тестирования политик безопасности, каждая из которых включает в себя последовательность правил для определения, какие кто имеет допуск к ресурсу и при каких условиях.
Преимущества и недостатки
Регрессионное тестирование выполняется при внесении изменений в существующие функциональные возможности программного обеспечения или, если есть ошибка исправления в программном обеспечении. Регрессионное тестирование может быть реализовано за счет нескольких подходов. Прохождение модифицированной программой всех тестов успешно обеспечивает уверенность в том, что изменения, внесенные в программное обеспечение, не повлияли на существующие функциональные возможности, которые должны быть неизменными в любом случае.
В гибком процессе управления проектами, где жизненный цикл разработки программного обеспечения очень короткий, не хватает ресурсов, и изменения в программное обеспечение вносятся очень часто. Регрессионное тестирование может ввести много ненужных накладных расходов.
Как правило, регрессионное тестирование осуществляется с помощью средств автоматизации, но нынешнее поколение инструментов регрессионного тестирования не предназначено для обработки приложений баз данных. По этой причине при выполнении регрессионного теста на приложениях, использующих базы данных, могут возникнуть незапланированные траты, поскольку это потребует много ручного труда.
Цитаты
Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20—50 %) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, шаг назад».
Почему не удается устранять ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но если только структура не является очень ясной, или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, ошибки обычно исправляет не автор программы, а зачастую младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное (регрессионное) тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.
— Ф. Брукс Мифический человеко-месяц или как создаются программные системы
- Контроль качества
- Разработка через тестирование
- Дымовое тестирование
К сожалению, в одной статье не просто дать все знания про регрессионное тестирование. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое регрессионное тестирование, regression testing
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Сразу хочу сказать, что здесь никакой воды про баг, и только нужная информация. Для того чтобы лучше понимать что такое
баг, ошибки в программировании, система отслеживания ошибок, баг-трекер, программный дефект , настоятельно рекомендую прочитать все из категории Информатика.
В программировании баг (англ. bug — первичные значения: клоп, любое насекомое, вирус) — жаргонное слово, обычно обозначающее ошибку в программе или системе, из-за которой программа выдает неожиданное поведение и, как следствие, результат. Большинство багов возникают из-за ошибок, допущенных разработчиками программы в ее исходном коде, либо в ее дизайне. Также некоторые баги возникают из-за некорректной работы компилятора, вырабатывающего некорректный код. Программу, которая содержит большое число багов и/или баги, серьезно ограничивающие ее работоспособность, называют нестабильной или, на жаргонном языке, «глючной», «глюкнутой», «забагованной», «бажной», «баг(а)нутой» ).
Термин «баг» обычно употребляется в отношении ошибок, проявляющих себя на стадии работы программы, в отличие, например, от ошибок проектирования или синтаксических ошибок. Отчет, содержащий информацию о баге также называют отчетом об ошибке или отчетом о проблеме (англ. bug report). Отчет о критической проблеме (англ. crash), вызывающей аварийное завершение программы, называют крэш-репортом (англ. crash report).
«Баги» локализуются и устраняются в процессе тестирования и отладки программы.
Программным дефектом называется ошибка в программном обеспечении, в результате которой продукт ведет себя непредвиденно (неверно). Большинство дефектов возникают из-за допущенной ошибки в программном коде или логической ошибки, допущенной во время проектирования. Гораздо меньшее количество — вследствие ошибок работы инструментальных средств (компилятора, генератора кода).
В отличии от программного кода аппаратная ошибка не связана с програмным обепечением. а вызвана работой аппаратных средств в следствии износа. воздействия особых факторов или ошибкой его проектирования.
Этимология термина «баг»
Английское слово bugge является основой для терминов « bugbear » и « bugaboo », используемых для обозначения монстра.
Термин «ошибка» для описания дефектов был частью инженерного жаргона с 1870-х годов и предшествовал электронным компьютерам и компьютерному программному обеспечению; возможно, первоначально он использовался в аппаратной инженерии для описания механических неисправностей. Например, Томас Эдисон написал следующие слова в письме своему коллеге в 1878 году:
Baffle Ball , первая механическая игра в пинбол , рекламировалась как «свободная от ошибок» в 1931 году. Проблемы с военной экипировкой во время Второй мировой войны назывались ошибками (или сбоями ). В книге, опубликованной в 1942 году, Луиза Дикинсон Рич , говоря о механизированной машине для резки льда , сказала: «Распиловка льда была приостановлена до тех пор, пока не появится создатель, который выведет жуков из его любимой машины».
Исаак Азимов использовал термин «жук» для обозначения проблем с роботом в своем рассказе « Поймай этого кролика », опубликованном в 1944 году.

Широко распространена легенда, что 9 сентября 1945 года ученые Гарвардского университета, тестировавшие вычислительную машину Mark II Aiken Relay Calculator, нашли мотылька, застрявшего между контактами электромеханического реле, и Грейс Хопперпроизнесла этот термин. Извлеченное насекомое было вклеено скотчем в технический дневник, с сопроводительной надписью: «First actual case of bug being found» («первый реальный случай, когда был найден жук»). Считается, что этот забавный факт положил начало использованию слова «debugging» в значении «отладка программы», однако, скорее всего, фраза являетсякаламбуром.
В действительности этот случай произошел 9 сентября 1947, а не 1945, года. Слово «bug» в современном значении употреблялось задолго до этого персоналом телеграфных и телефонных компаний в отношении неполадок с электрооборудованием и радиотехникой. Во время Второй мировой войны словом «bugs» назывались проблемы с радарной электроникой. В 1878 годуТомас Эдисон писал:
Это повторялось снова и снова со всеми моими изобретениями. Первым шагом была интуиция, за ней следовала вспышка, затем возникали препятствия — и они исчезали, потом возникали Баги — так называются маленькие недочеты и трудности — и необходимы месяцы постоянного поиска, исследований и тяжелого труда до успеха или неудачи .
В 1946 году, когда Хоппер уволили с действительной службы, она поступила на Гарвардский факультет в вычислительную лабораторию, где продолжила свою работу над Mark II и Mark III . Операторы проследили ошибку в Mark II до мотылька , пойманного в реле, придумав термин « ошибка » . Эта ошибка была тщательно удалена и записана в бортовой журнал. Исходя из первой ошибки, сегодня мы называем ошибки или сбои в программе ошибкой .