
Функция ПРЕДСКАЗ в Excel позволяет с некоторой степенью точности предсказать будущие значения на основе существующих числовых значений, и возвращает соответствующие величины. Например, некоторый объект характеризуется свойством, значение которого изменяется с течением времени. Такие изменения могут быть зафиксированы опытным путем, в результате чего будет составлена таблица известных значений x и соответствующих им значений y, где x – единица измерения времени, а y – количественная характеристика свойства. С помощью функции ПРЕДСКАЗ можно предположить последующие значения y для новых значений x.
Deprecated: Функция wp_make_content_images_responsive с версии 5.5.0 считается устаревшей! Используйте wp_filter_content_tags(). in /home/h/hostweg6/mycoderblog.ru/public_html/wp-includes/functions.php on line 5382
Отслеживание ошибок – важное дело. При разработке программного обеспечения ошибки неизбежны. Однако, когда вы сталкиваетесь с одной ошибкой, это часто означает, что в коде есть какие-то проблемы.
Важно отслеживать баги на протяжении всего процесса разработки, чтобы одна небольшая ошибка не превратилась в миллион гигантских проблем. Это также важно для бизнеса, поскольку команды разработчиков, которые производят программное обеспечение с неразрешенными ошибками, — обречены на уныние ибо не найдут клиентов, которые будут покупать, использовать или доверять таким продуктам.
Хорошая команда разработчиков должна иметь надежное решение под рукой для отслеживания ошибок во время работы над проектом. Однако, если вы являетесь частью небогатого стартапа, который еще не имеет своей горки денег, потраченных на программное обеспечение или инвестированных в проект; где каждая копейка на вес золота, — инвестирование в дополнительное ПО может оказаться невозможным.
К счастью, в этом мире ещё есть программное обеспечение для отслеживания проблем, категории free, — стоимость которого составляет целых 0 рублей.
Чтобы помочь сократить ИТ-расходы, мы выбрали десять бесплатных программных решений для отслеживания ошибок с открытым исходным кодом, которые помогут любой команде отслеживать проблемы без каких-либо затрат.

Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах
где Z(t) – фактическое значение временного ряда, а
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
Виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):

Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.
- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.
- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:
Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
MPE – средняя процентная ошибка в Excel
Из данной статьи вы узнаете:
- Для чего нужна средняя процентная ошибка;
- Как она рассчитывается.
MPE (mean percentage error) — средняя процентная ошибка прогноза.
MPE – средняя процентная ошибка прогноза используется в случаях, когда надо определить модель прогноза дает последовательно завышенные прогнозы или последовательно заниженные прогнозы.
Если значение больше нуля, то прогнозы последовательно занижены, т.е. в среднем меньше факта.
Если ошибка меньше нуля, то прогнозы последовательно завышены, т.е. модель делает прогноз в среднем выше факта.
Как рассчитать среднюю процентную ошибку?
- Рассчитываем ошибку для каждого значения модели;
- Делим на фактические данные ошибку в каждый момент времени.
Рассчитываем среднее по пункту 2, и получает среднюю процентную ошибку — MPE:
Рассчитаем на примере прогноза объема продаж:
1. Ошибка = фактические продаж минус значения прогнозной модели для каждого момента времени:

2. Делим ошибку на фактические продажи для каждого периода времени:

3. Рассчитываем среднее значение % ошибки — MPE:

Мы видим, что средняя процентная ошибка у нас получилась -0,65% — это говорит о том, что модель прогноза в среднем дает завышенные прогноза на 0,65%:
Из данной статьи вы узнали, для чего использовать среднюю процентную ошибку прогноза — MPE и как ее рассчитать в Excel.
Если у вас остались вопросы, пожалуйста, задавайте в комментариях, буду рад помочь!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
Тестируйте возможности платных решений:
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
В настоящее время программные системы становятся все более сложными и многокомпонентными. Чем больше объем исходного кода, тем больше трудозатрат необходимо для поддержания качества программной системы на должном уровне. Своевременное выявление и исправление дефектов играют большую роль в жизненном цикле ПО. Прогнозирование того, содержит ли программный компонент дефекты проектирования, помогает улучшить качество разрабатываемых систем.
Классификация методов прогнозирования программных дефектов.
Метод прогнозирования представляет собой последовательность действий, которые нужно совершить для получения модели прогнозирования. Модели прогнозирования дефектов ПО используются либо для классифицирования компонентов, подверженных дефектам, либо для прогнозирования количества дефектов, ожидаемых в программном компоненте. На рисунке 1 приведены наиболее распространенные методы и модели прогнозирования дефектов ПО, сгруппированные в зависимости от цели – прогнозирование количества дефектов или классифицирование дефектов.
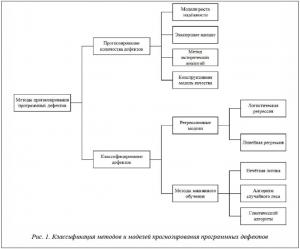
Прогнозирование количества дефектов. Методы прогнозирования, которые оперируют только количеством дефектов, обнаруженных во время разработки и тестирования без учета других атрибутов, связанных с внутренней структурой, дизайном или реализацией продукта, называют методами черного ящика. Методы прогнозирования, которые используют атрибуты, связанные с процессом и продуктом, например, размер, сложность, изменения, относятся к методам белого ящика. Рассмотрим наиболее распространенные модели, применяемые для прогнозирования количества дефектов ПО.
Метод исторических аналогий основан на сборе и сравнении различных метрик между прошлым
и текущим проектами. На основе установления сходства метрик по некоторым признакам появляется возможность сделать вывод о сходстве в других признаках, то есть делать умозаключения по аналогии. Для прогнозирования дефектов ПО обычно используются размер, тип приложения, функциональная сложность и другие параметры. Анализ может быть выполнен на уровне проекта, подсистемы или компонента. Модели, основанные на методе исторических аналогий, особенно полезны, когда для предметной области трудно выявить конкретные правила.
Основные недостатки метода исторических аналогий:
· конечный результат сильно зависит от правильности подобранного объекта-аналога, поэтому
к его выбору необходимо относиться очень внимательно;
· следует учитывать все специфические особенности объекта прогнозирования, а также действия внешних факторов.
Конструктивная модель качества использует экспертно-детерминированные подмодели внедрения и устранения дефектов для построения качественной модели. В рамках этой модели с помощью подмодели «внедрение дефектов» (defect introduction, DI) сначала оценивается количество нетривиальных требований, вводимых дефектов проектирования и кодирования. Эта подмодель использует оценки размера ПО и прочие атрибуты, связанные с проектом и процессом (платформа и т.д.). Выходные данные DI подмодели являются входными данными для подмодели устранения дефектов (defect removal, DR). Результат подмодели DR — оценка количества оставшихся дефектов на единицу размера.
Классифицирование дефектов. Методы классифицирования позволяют определить подверженные дефектам программные модули и обычно применяются на более низких уровнях детализации, например, на уровне файлов и классов.
Регрессионные модели прогнозирования используются для решения задач, требующих изучения отношения между двумя и более переменными. В основе любой регрессионной модели лежит использование регрессии какого-либо вида. Параметры регрессии оцениваются на основе метрик для имеющегося исходного кода, а затем полученная регрессия используется для прогнозирования дефектов. Наиболее распространены логистическая и линейная регрессии.
где Qi — коэффициенты регрессии; xi — независимые переменные.
Линейная регрессионная модель является самым простым вариантом регрессионной модели. В ее основу положено предположение, что существует дискретный внешний фактор X(t), оказывающий влияние на исследуемый процесс Z(t), при этом связь между процессом и внешним фактором линейна. Модель описывается уравнением
где a0 и a1 — коэффициенты регрессии; e t — ошибка модели.
Для получения прогнозных значений Z(t) в момент времени t необходимо иметь значение X(t) в тот же момент времени t, что редко выполнимо на практике. Главным недостатком линейной регрессии является требование равномерного распределения данных.
Следующей группой методов, применяемых для классифицирования дефектов ПО, являются методы машинного обучения — динамические алгоритмы обучения; их производительность, как правило, улучшается по мере поступления дополнительных данных.
На рисунке 2 показан общий процесс прогнозирования дефектов ПО на основе моделей машинного обучения.
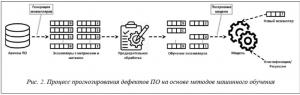
Первым шагом для построения модели прогнозирования является создание экземпляров из архивов ПО (системы контроля версий, системы отслеживания ошибок, архивы электронной почты и т.д.). Каждый экземпляр может представлять собой программный компонент, файл исходного кода, класс или функцию в зависимости от выбранной степени детализации прогнозирования. Каждый извлеченный экземпляр имеет метрики и метки, которые указывают, склонен ли данный экземпляр к дефектам (если да, то дополнительно указывается их количество). Например, на рисунке 2 экземпляры, содержащие дефекты, помечены как «B» с указанием количества ошибок, а экземпляры без ошибок — как «C». Далее производится предварительная обработка экземпляров, включающая нормализацию данных и шумоподавление. Данный этап не является обязательным. После получения окончательного набора обучающих элементов можно переходить к обучению модели прогнозирования. Модель прогнозирования может предсказать наличие ошибки в новом экземпляре. Прогнозирование того, содержит ли данный экземпляр дефекты, представляет собой классификацию, а прогнозирование количества ошибок в экземпляре – регрессию.
Данная методология предполагает следующие шаги.
1. Определение входов и выходов создаваемой системы.
2. Определение функции принадлежности для каждой метрики.
3. Разработка нечетких правил и получение экспертного мнения для реализуемой нечеткой системы.
4. Агрегирование всех отдельных нечетких множеств для различных правил.
5. Поиск четкого значения путем дефаззификации агрегированного нечеткого множества.
Достоинством данной модели является то, что она использует как количественные, так и качественные показатели метрик для прогнозирования дефектов, недостатком — увеличение сложности вычислений в связи с увеличением входных показателей.
Алгоритм случайного леса (Random forest) основан на множестве деревьев решений и использует следующую стратегию.
— Корневой узел каждого дерева содержит начальную выборку данных. Для каждого отдельного дерева эта выборка уникальна.
— На каждом узле выборка случайным образом разбивается на два подмножества для получения двух следующих узлов с меньшими выборками.
— Каждое дерево растет до максимально возможного размера, пока на каждой ветви не будет исчерпана вся выборка.
— Когда все деревья построены, осуществляется классификация объектов путем голосования. Каждое дерево «голосует» либо за то, что компонент содержит дефекты, либо за то, что дефектов нет. В итоге компонент признается дефектным либо недефектным в зависимости от того, за какой класс решения отдано больше голосов.
Алгоритм показывает высокую точность классификации на больших наборах данных.
Генетический алгоритм — это подход к машинному обучению, подобный человеческому гену и дарвиновской теории естественного отбора. Относится к эволюционным алгоритмам, генерирующим решения на основе таких понятий, как мутация, отбор, кроссовер и т.д.
Вывод. В данной статье был сделан обзор методов прогнозирования дефектов ПО, приведены их достоинства и недостатки. Несмотря на разнообразие существующих методов прогнозирования дефектов, некоторые серьезные проблемы остаются нерешенными. Эти проблемы ограничивают сферу применения существующих методов прогнозирования и делают процесс сложным и недостаточно автоматизированным.
Литература
1. International Software Testing Qualifications Board, Certified Tester Foundation Level Syllabus. URL: https://www.istqb.org/downloads/send/51-ctfl2018/208-ctfl-2018-syllabus.html (дата обращения: 24.12.2018).
2. Кирносенко С.И., Лукьянов В.С. Прогнозирование обнаружения дефектов в программном обеспечении // Программные продукты и системы. 2011. № 3. С. 68.
3. Sabnis P., Kadam A. Software Reliability Growth Model with Bug Cycle and Duplicate Detection Techniques. Bharati Vidyapeeth Deemed Univ. College of Eng., Pune, India, 2013, pp. 345-349.
4. Dulal C.S. Software Defect Prediction Based on Classification Rule Mining. Department of comp. sci. and Eng. National Institute of Technology Rourkela, 2013, pp. 19-65.
5. Шадрина В.В. Применение методов прогнозирования в технических системах // Изв. ЮФУ: Технич. науки. 2011. № 2. С. 141-145.
6. Rosli M., Hasimah N., Yusop M. Fault Prediction Model for Web Application Using Genetic Algorithm. Proc. Intern. Conf. on Comp. and Sof. Modeling IPCSIT, 2011, vol. 14, pp. 71-77.
Tuleap

Просмотр проблемы в Tuleap
Tuleap — это гибкое решение для управления проектами. Его функция отслеживания позволяет отслеживать ошибки, а также требования и задачи проекта. Каждая команда может создавать и настраивать новые элементы для отслеживания без одобрения системного администратора.
Tuleap также позволяет создавать настраиваемые рабочие процессы.
Ограничения: в бесплатной версии Tuleap отсутствуют дополнительные функции, такие как отслеживание времени и управление тестированием.
Стоимость обновления: Tuleap предлагает корпоративные и облачные планы для команд, которым необходим доступ к более продвинутым функциям. Эти планы также предлагают платные варианты поддержки. Tuleap не перечисляет цены на своем сайте.
MantisBT

Сводка панели в MantisBT
MantisBT построен на PHP и совместим с базами данных MySQL и PostgreSQL. Он обычно используется в качестве отслеживания ошибок, но его можно настроить для управления более крупными проектами.
MantisBT предлагает управление доступом, которое можно изменить для каждого проекта; настраиваемые поля проблем, уведомления и рабочие процессы, надстройку с оптимизированным мобильным интерфейсом, если команде нужен мобильный доступ.
Пользователи обнаружили, что MantisBT достаточно прост для опытного программиста, но отметили, что менее опытному разработчику может потребоваться некоторое обучение. Они также отметили, что, хотя интерфейс MantisBT устарел, он по-прежнему предлагает все основные функции, которые команда разработчиков программного обеспечения должна отслеживать и иметь возможность исправлять ошибки.
Ограничения бесплатной версии: MantisBT — это решение с открытым исходным кодом. Самостоятельная бесплатная версия включает все функции.
Стоимость обновления: MantisBT также предлагает версию SaaS, которая начинается с $ 4,95 в месяц для одного проекта и до пяти пользователей.
Примеры использования функции ПРЕДСКАЗ в Excel
Функция ПРЕДСКАЗ использует метод линейной регрессии, а ее уравнение имеет вид y=ax+b, где:
- Коэффициент a рассчитывается как Yср.-bXср. (Yср. и Xср. – среднее арифметическое чисел из выборок известных значений y и x соответственно).
- Коэффициент b определяется по формуле:
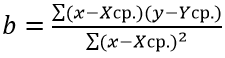
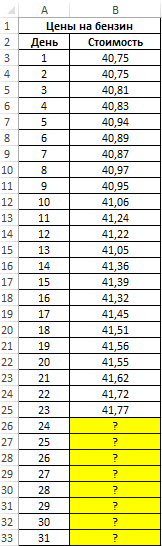
В таблице приведены данные о ценах на бензин за 23 дня текущего месяца. Согласно прогнозам специалистов, средняя стоимость 1 л бензина в текущем месяце не превысит 41,5 рубля. Спрогнозировать стоимость бензина на оставшиеся дни месяца, сравнить рассчитанное среднее значение с предсказанным специалистами.
Вид исходной таблицы данных:
Чтобы определить предполагаемую стоимость бензина на оставшиеся дни используем следующую функцию (как формулу массива):
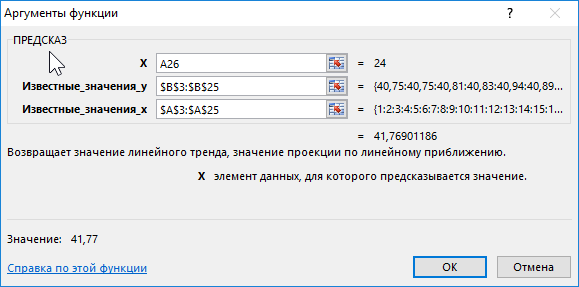
- A26:A33 – диапазон ячеек с номерами дней месяца, для которых данные о стоимости бензина еще не определены;
- B3:B25 – диапазон ячеек, содержащих данные о стоимости бензина за последние 23 дня;
- A3:A25 – диапазон ячеек с номерами дней, для которых уже известна стоимость бензина.
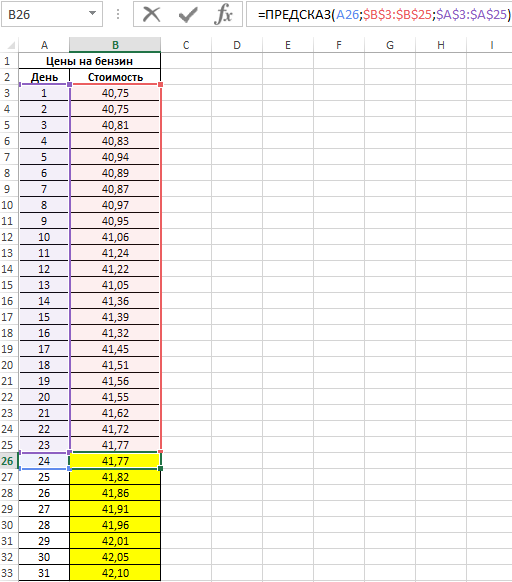
Рассчитаем среднюю стоимость 1 л бензина на основании имеющихся и расчетных данных с помощью функции:
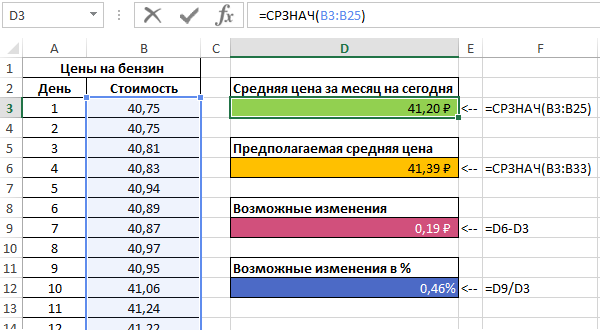
Можно сделать вывод о том, что если тенденция изменения цен на бензин сохранится, предсказания специалистов относительно средней стоимости сбудутся.
Bugzilla

Список ошибок в Bugzilla
Система работает на MySQL, PostgreSQL и Oracle и требует установки Perl.
Пользователям Bugzilla нравится, тем что программное обеспечение легко использовать с низкой кривой обучения. Они считают, что у ПО есть все основные функции для отслеживания ошибок. Но! — если потребности более сложны, то сервис слабоват.
Ограничения бесплатной версии: Bugzilla — это инструмент с открытым исходным кодом, поэтому бесплатная версия включает в себя все функции.
Trac

Список тикетов в Trac
Trac специально создан для проектов разработки и отслеживания проблем, но также может использоваться для управления документами. Он имеет минималистский дизайн, встроенную вики и интегрируется с Apache Subversion и GitHub.
Можно связать ошибки с различными задачами, файлами, страницами вики или ошибками. Trac написан на Python и совместим с SQLite, MySQL и PostgreSQL.
Ограничения бесплатной версии: Trac — это решение с открытым исходным кодом, поэтому бесплатная версия включает в себя все функции.
Анализ прогноза спроса продукции в Excel по функции ПРЕДСКАЗ
Компания недавно представила новый продукт. С момента вывода на рынок ежедневно ведется учет количества клиентов, купивших этот продукт. Предположить, каким будет спрос на протяжении 5 последующих дней.
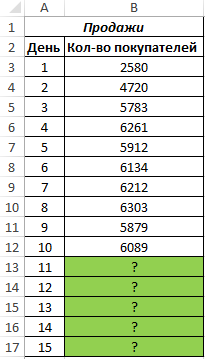
Как видно, в первые дни спрос был небольшим, затем он рос достаточно большими темпами, а на протяжении последних трех дней изменялся незначительно. Это свидетельствует о том, что основным фактором роста продаж на данный момент является не расширение базы клиентов, а развитие продаж с постоянными клиентами. В таких случаях рекомендуют использовать не линейную регрессию, а логарифмический тренд, чтобы результаты прогнозов были более точными.
Рассчитаем значения логарифмического тренда с помощью функции ПРЕДСКАЗ следующим способом:
Как видно, в качестве первого аргумента представлен массив натуральных логарифмов последующих номеров дней. Таким образом получаем функцию логарифмического тренда, которая записывается как y=aln(x)+b.
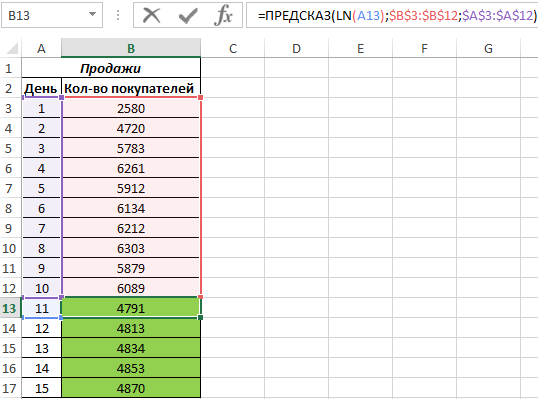
Для сравнения, произведем расчет с использованием функции линейного тренда:
И для визуального сравнительного анализа построим простой график.
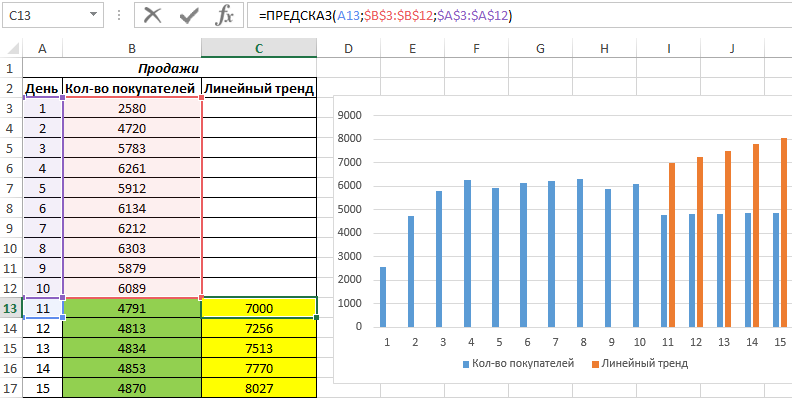
Как видно, функцию линейной регрессии следует использовать в тех случаях, когда наблюдается постоянный рост какой-либо величины. В данном случае функция логарифмического тренда позволяет получить более правдоподобные данные (более наглядно при большем количестве данных).
Pivotal Tracker

Меню настроек и бэклог в Pivotal Tracker ( Source )
Pivotal Tracker — это гибкое решение для управления проектами, созданное для разработчиков программного обеспечения. Его визуальная панель позволяет сразу увидеть все проекты, над которыми проводится работа, чтобы не потерять контроль над ошибками или задачами. Функция отслеживания скорости фиксирует темпы, с которыми команда решает проблемы.
Система также интегрируется с GitHub, поэтому можно отслеживать код во всем проекте.
Пользователям Pivotal Tracker нравится, тем что панели инструментов программы дают им хорошую видимость проектов как в усечённом малом, так и в большом масштабе. Многие считают, что система проста в использовании, но некоторые пользователи отметили, что системой становится сложно пользоваться, если они отслеживают сразу несколько проектов.
- Три пользователя
- 2 ГБ памяти
- Может иметь только два проекта в системе в любой момент времени
Стоимость обновления: самая низкая цена платной версии Pivotal Tracker составляет 12,50 долларов США в месяц для пяти пользователей, пяти проектов и 5 ГБ памяти.
ME – средняя ошибка
Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
RMSE – квадратный корень из среднеквадратичной ошибки
SD – стандартное отклонение
где ME – есть средняя ошибка, определенная по формуле выше.
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:

где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:

В таком случае для тех же примеров ошибка рассчитается иначе:
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Futuramo

Визуальный тикет в Футурамо
Проблемы могут быть поручены одному исполнителю или команде, а функция интеллектуального поиска решения позволяет использовать любые выражения, связанные с проблемой. Futuramo также предлагает множество других модулей, включая отслеживание времени; управление проектами и контактами.
Стоимость обновления: самая низкая цена платной версии Futuramo начинается с 8 долларов США за лицензию в месяц для добавления четвёртого пользователя.
YouTrack

Программное обеспечение, адаптированное под требования Agile software development. Даёт возможность искать полный текст ошибки. Позволяет группировать проблемы с помощью тегов (что упрощает их поиск в системе) или связывать разные проблемы друг с другом для отслеживания связанных ошибок.
Через REST API YouTrack позволяет конечным пользователям сообщать разработчикам о проблемах из различных сторонних приложений.
Пользователи YouTrack заявили, что система быстро настраивается, легко интегрируется с другими приложениями и описали функциональность поиска ошибок как очень мощную. Однако многие отметили, что неуклюжий пользовательский интерфейс приводит к длительному обучению для работы с программой.
- Ограничено до десяти пользователей
- Версия облака имеет ограничение хранения 5 ГБ
- Версия облака не позволяет создавать частные проекты
Стоимость обновления: самая низкая платная версия решения SaaS от YouTrack составляет 200 долларов США в год для 15 пользователей. Для размещения YouTrack на своих серверах YouTrack составляет 500 долларов США для 25 пользователей.
Redmine

Список проблем в Redmine
Redmine — это больше, чем просто трекер ошибок. Это решение для управления проектами с открытым исходным кодом и существует он уже более десяти лет, поддерживает 34 разных языка. Redmine написан на Ruby и совместим с MySQL, PostgreSQL, Microsoft SQL и SQLite.
Если просто ищете отслеживание ошибок, то Redmine может дать намного больше, чем рассчитывали. Можно использовать гибкость настраиваемого интерфейса и множество доступных плагинов для адаптации системы к потребностям команды.
Пользователи Redmine обнаружили, что базовая версия программы проста в применении и довольно интуитивна в использовании. При установке плагинов и расширении с помощью модулей можно повысить функциональность программного обеспечения. Хотя это может сделать систему сложной в использовании. Однако, без плагинов и настроек, интерфейс кажется устаревшим и неуклюжим.
Ограничения бесплатной версии: Redmine — это решение с открытым исходным кодом, поэтому бесплатная версия включает в себя все функции.
Особенности использования функции ПРЕДСКАЗ в Excel
Функция имеет следующую синтаксическую запись:
- – обязательный для заполнения аргумент, характеризующий одно или несколько новых значений независимой переменной, для которых требуется предсказать значения y (зависимой переменной). Может принимать числовое значение, массив чисел, ссылку на одну ячейку или диапазон;
- – обязательный аргумент, характеризующий уже известные числовые значения зависимой переменной y. Может быть указан в виде массива чисел или ссылки на диапазон ячеек с числами;
- – обязательный аргумент, который характеризует уже известные значения независимой переменной x, для которой определены значения зависимой переменной y.
- Второй и третий аргументы рассматриваемой функции должны принимать ссылки на непустые диапазоны ячеек или такие диапазоны, в которых число ячеек совпадает. Иначе функция ПРЕДСКАЗ вернет код ошибки #Н/Д.
- Если одна или несколько ячеек из диапазона, ссылка на который передана в качестве аргумента x, содержит нечисловые данные или текстовую строку, которая не может быть преобразована в число, результатом выполнения функции ПРЕДСКАЗ для данных значений x будет код ошибки #ЗНАЧ!.
- Статистическая дисперсия величин (можно рассчитать с помощью формул ДИСП.Г, ДИСП.В и др.), передаваемых в качестве аргумента известные_значения_x, не должна равняться 0 (нулю), иначе функция ПРЕДСКАЗ вернет код ошибки #ДЕЛ/0!.
- Рассматриваемая функция игнорирует ячейки с нечисловыми данными, содержащиеся в диапазонах, которые переданы в качестве второго и третьего аргументов.
- Функция ПРЕДСКАЗ была заменена функцией ПРЕДСКАЗ.ЛИНЕЙН в Excel версии 2016, но была оставлена для обеспечения совместимости с Excel 2013 и более старыми версиями.
- Для предсказания только одного будущего значения на основании известного значения независимой переменной функция ПРЕДСКАЗ используется как обычная формула. Если требуется предсказать сразу несколько значений, в качестве первого аргумента следует передать массив или ссылку на диапазон ячеек со значениями независимой переменной, а функцию ПРЕДСКАЗ использовать в качестве формулы массива.
10 бесплатных программ для отслеживания ошибок с открытым исходным кодом
Некоторые из этих утилит предназначены исключительно для отслеживания ошибок, а другие — более расширенные решения, которые могут помочь отслеживать несколько этапов ваших проектов разработки. Все они — free.
Некоторые бесплатные системы имеют ограничения по количеству пользователей или проектов, которые можно присоединить к ней. Для небольших команд это не проблема. Но, вероятно, не будет иметь смысла для более крупных команд или компаний, работающих одновременно над несколькими клиентскими проектами, то такие ограничения перечислены, чтоб знать о них заранее.
Параметры, которые применялись при отборе программного обеспечения:
- Решения, наиболее часто упоминаемые специалистами на основе собственного опыта.
- Системы, которые все еще поддерживаются и недавно (в течение последнего года) обновлены.
- Системы, предлагающие бесплатную версию.
- Системы, позволяющие работать более чем одному пользователю в бесплатной версии, чтобы могла работать команда.
Прогнозирование будущих значений в Excel по условию
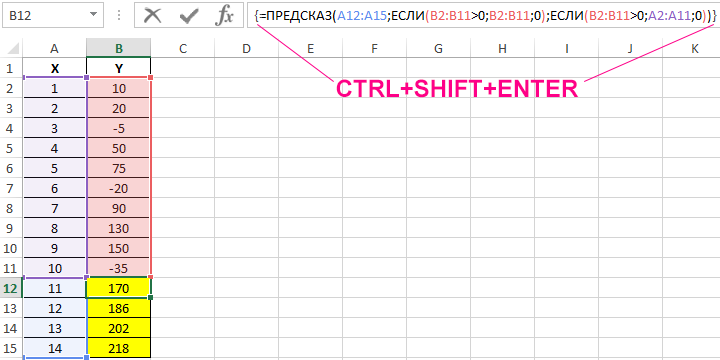
В таблице Excel указаны значения независимой и зависимой переменных. Некоторые значения зависимой переменной указаны в виде отрицательных чисел. Спрогнозировать несколько последующих значений зависимой переменной, исключив из расчетов отрицательные числа.
Вид таблицы данных:
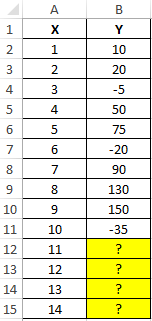
Для расчета будущих значений Y без учета отрицательных значений (-5, -20 и -35) используем формулу:
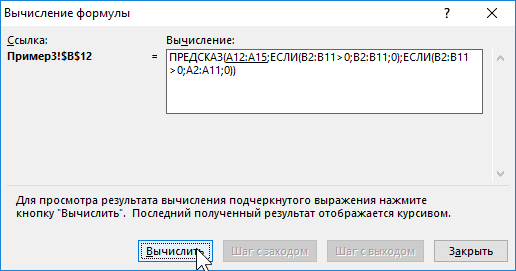
C помощью функций ЕСЛИ выполняется перебор элементов диапазона B2:B11 и отброс отрицательных чисел. Так, получаем прогнозные данные на основании значений в строках с номерами 2,3,5,6,8-10. Для детального анализа формулы выберите инструмент «ФОРМУЛЫ»-«Зависимости формул»-«Вычислить формулу». Один из этапов вычислений формулы:
Backlog

Описание ошибки в Backlog ( Source )
Созданный для разработчиков, Backlog — это онлайн-решение для управления проектами, которое также включает отслеживание ошибок. Система позволяет видеть все ошибки, которые вписываются в общий рабочий процесс проекта.
Пользователям, работающим с Backlog, понравилось, что даже бесплатная версия системы включает в себя доступ к вики и говорит, что система в целом проста в использовании и настройке.
- Десять пользователей
- Один проект
- 100 МБ памяти
Стоимость обновления: самая низкая цена оплачиваемой версии Backlog составляет 20 долларов США в месяц для 30 пользователей, пяти проектов и одного ГБ хранилища.
Fossil

Проект в Fossil
Программное обеспечение с открытым исходным кодом и встроенным отслеживанием ошибок. Оно автономное, поэтому нет необходимости в создании собственного веб-сервера или базы данных. Система также предлагает управление версиями, создание вики и автоматическое обновление файлов.
Настройки позволяют связать работу с реальным временем, позволяя фиксировать этапы, контрольные точки процесса, объявления, связанные проектом.
Ограничения бесплатной версии: Fossil — это инструмент с открытым исходным кодом, поэтому бесплатная версия включает в себя все функции.