
Отладка программы — один их самых сложных
этапов разработки программного
обеспечения, требующий глубокого знания:
Перефразировав Томаса Эдисона, можно утверждать, что программирование на 10 процентов состоит из вдохновения и на 90 процентов из отладки. Все действительно квалифицированные программисты являются хорошими отладчиками. Чтобы научиться предотвращать множество ошибок, целесообразно рассмотреть некоторые довольно распространенные действия, которые могут привести к их появлению.
Автоматическое
отображение списка элементов 2
Ошибки в
структуре программы 4
Сообщение
об ошибке в структуре программы 4
Выполнить
до текущей позиции 7
Просмотр
данных во всплывающей подсказке 8
Английский
термин «debugging»
(отладка) связывают с инцидентом,
произошедшим в Министерстве обороны
США. Когда в одной из первых вычислительных
машин Пентагона возникла ошибка при
вычислениях, был проверен текст программы,
однако ошибка не была выявлена. Причина
была обнаружена при проверке самой
вычислительной машины. Между контактами
одного из реле был зажат жучок (насекомое)
– по-английски bug,
что и послужило причиной ошибки. После
удаления жучка (debugging)
ошибка была устранена. Даже если этой
истории и не было на самом деле, её стоило
выдумать, т.к. она довольно удачно
разъясняет возникновение термина
«debugging».
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•среды и языка программирования,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
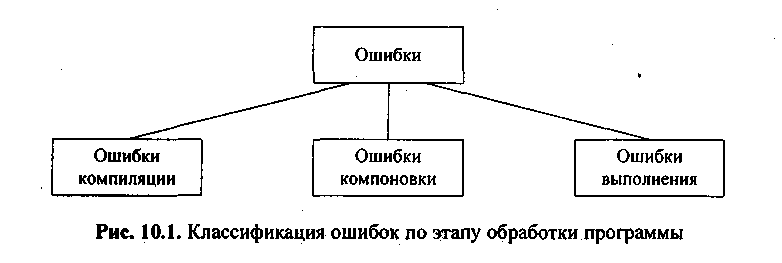
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
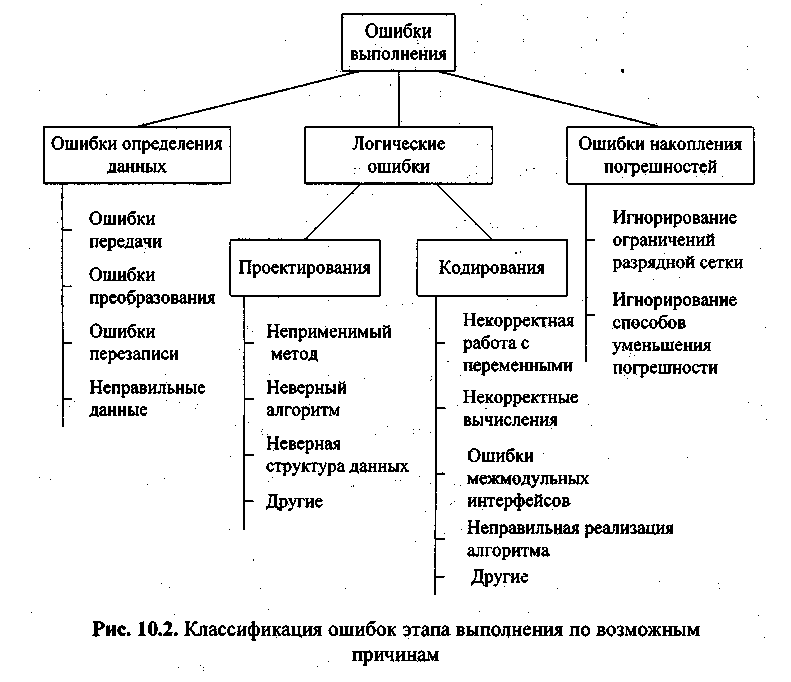
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Классификация ошибок.
Отладка — это
процесс локализаций и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют процесс
определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
Для исправления ошибки необходимо
определить ее причину,
т. е. определить
оператор или фрагмент, содержащие
ошибку. Причины ошибок могут быть как
очевидны, так и очень глубоко скрыты.
В целом сложность отладки обусловлена
следующими причинами:
В соответствии с этапом обработки, на
котором проявляются ошибки, различают
(рис. 10.1):
синтаксические ошибки —
ошибки, фиксируемые
компилятором (транслятором,
интерпретатором) при выполнении
синтаксического и частично семантического
анализа программы;
ошибки компоновки — ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
ошибки выполнения — ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические ошибки.
Синтаксические ошибки
относят к группе самых простых, так как
синтаксис языка, как правило, строго
формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в виду, что
чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным
синтаксисом и с незащищенным синтаксисом.
К первым, безусловно, можно отнести
Pascal,
имеющий очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например:
if(c=n)
x=0;/*
в данном случае не
проверятся равенство с и n,
а выполняется присваивание с значения
n,
после чего результат операции сравнивается
с нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых*/
Ошибки компоновки. Ошибки
компоновки, как следует из названия,
связаны с проблемами, обнаруженными
при разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения. К
самой непредсказуемой группе относятся
ошибки выполнения. Прежде всего они
могут иметь разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
Примечание. Отметим,
что, если ошибки этапа выполнения
обнаруживает пользователь, то в двух
первых случаях, получив соответствующее
сообщение, пользователь в зависимости
от своего характера, степени необходимости
и опыта работы за компьютером, либо
попробует понять, что произошло, ища
свою вину, либо обратится за помощью,
либо постарается никогда больше не
иметь дела с этим продуктом. При
«зависании» компьютера пользователь
может даже не сразу понять, что
происходит что-то не то, хотя его печальный
опыт и заставляет волноваться каждый
раз, когда компьютер не выдает быстрой
реакции на введенную команду, что также
целесообразно иметь в виду. Также опасны
могут быть ситуации, при которых
пользователь получает неправильные
результаты и использует их в своей
работе.
Причины ошибок выполнения
очень разнообразны, а потому и локализация
может оказаться крайне сложной. Все
возможные причины ошибок можно разделить
на следующие группы:
Неверное определение
исходных данных
происходит, если возникают любые
ошибки при выполнении операций
ввода-вывода: ошибки передачи, ошибки
преобразования, ошибки перезаписи и
ошибки данных. Причем использование
специальных технических средств и
программирование с защитой от ошибок
(см. § 2.7) позволяет обнаружить и
предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля. К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный
выбор типов данных, использование
переменных до их инициализации,
использование индексов, выходящих за
границы определения массивов, нарушения
соответствия типов данных при использовании
явного или неявного переопределения
типа данных, расположенных в памяти при
использовании нетипизированных
переменных, открытых массивов, объединений,
динамической памяти, адресной
арифметики и т. п.;
Накопление погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения
ошибок следует иметь в виду в процессе
отладки. Кроме того, сложность отладки
увеличивается также вследствие
влияния следующих факторов:
Синтаксические ошибки.
Причиной
таких ошибок могут быть неправильно
написанные ключевые слова, неверно
примененные разделители или недопустимые
комбинации операторов. Такие ошибки
VisualBasicраспознает сразу после того, как курсор
покидает только что написанную строку.
Строка с синтаксической ошибкой
выделяется красным цветом. После
устранения ошибки выделение цветом
снимается.
VisualBasicимеет средства,
позволяющие не только обнаружить
синтаксическую ошибку, но и избежать
ее в процессе написания кода. К таким
средствам относятся
– механизм
контекстной подсказки (после написании
ключевого слова появляется окно, в
котором отображается полный синтаксис
вводимого оператора или список аргументов
используемой процедуры);
– автоматическое
отображение списка элементов (например,
после имени элемента управления
появляется список всех свойств и
методов, из которого можно выбрать
требуемое);
– дополнение
слова (при вводе нескольких начальных
символов, достаточных для распознавания
ключевого слова, недостающие символы
автоматически добавляются).
Ошибки очередности вычисления
В большинстве С-программ применяются операторы инкрементирования и декрементирования, а порядок следования этих операторов, как вы помните, имеет большое значение в зависимости от того, предшествуют они или следуют за переменной. Рассмотрим следующий случай:
y = 10; y = 10;
x = y++; x = ++y;
Приведенные две последовательности не эквивалентны. Та, что слева, присваивает переменной х значение 10, а затем инкрементирует у. В другой же последовательности (справа) у сначала инкрементируется, и в результате этого становится равным 11, и только затем значение 11 присваивается переменной х. Таким образом, в первом случае х равно 10, а во втором случае х — 11. В общем случае в сложных выражениях префиксная операция инкрементирования (или декрементирования) осуществляется перед вычислением значения операнда, используемого в последующих действиях. Постфиксный инкремент (или декремент) выполняется в сложных выражениях после того, как значение операнда вычислено. Если забыть об этих правилах, проблем не миновать.
Путь, обычно ведущий к возникновению ошибки очередности вычисления, заключается в изменении имеющейся последовательности операторов. Например, при оптимизации фрагмента кода вы могли бы изменить следующую последовательность:
/* первоначальный код */
x = a + b;
a = a + 1;
и представить ее в таком виде:
/* «усовершенствованный» код — ошибка! */
x = ++a + b;
Проблема заключается в том, что эти два фрагмента кода не дают одинаковый результат. Причина состоит в том, что второй способ инкрементирует переменную а до того, как она суммируется с b. А такое действие в первоначальном варианте не было предусмотрено!
Подобные ошибки относятся к разряду трудно обнаруживаемых. Могут быть ключи-подсказки, например циклы, выполняющиеся неправильно, или процедуры, которые не работают из-за таких ошибок. Если у вас возникает сомнение в правильности оператора, перекодируйте его таким образом, чтобы быть уверенным в нем на все 100 процентов.
Ошибки, возникающие во время выполнения программы.
Это
ошибки, возникающие во время работы
программы (например, при выполнении
деления на ноль или при попытки чтения
из несуществующего на диске файла). В
таких случаях выводится сообщение в
специальном окне, в котором указывается
причина прерывания программы и номер
ошибки. На этом окне есть четыре кнопки
«Continue», «End»,
«Debug» и «Help».
В
качестве примера на рис.33 показано окно
с сообщением об ошибке деления на ноль.
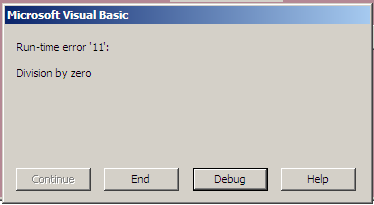
Рис.33.
Вид окна с сообщением об ошибке на этапе
выполнения
Из
рисунка видно, что надпись на кнопке
«Continue» бледнее остальных.
Это означает, что при такой ошибке
дальнейшее продолжение программы
невозможно. Контур кнопки «Debug»
выделен жирной линией, это означает,
что для перехода в режим отладки эту
кнопку можно «нажать» не только с
помощью манипулятора «мышь», но и путем
нажатия кнопки «Enter»
клавиатуры. Нажатие кнопки «End»
приведет к завершению программы, а
кнопки «Help» – к появлению
окна справки с информацией о типе ошибки
и возможности ее устранения.
При
переходе в режим отладки открывается
окно с текстом программы, в которой
выделена строка с командой, выполнение
которой привело к прерыванию. При этом
появляется возможность определить
значения переменных на момент выполнения
прерывания. Для этого достаточно
подвести курсор к имени переменной, в
появившемся окошке появится либо ее
значение, либо слово «Empty»
(«пустая»), если на момент выполнения
команды переменная не получила никакого
значения.
На
этапе разработки программы можно
предусмотреть перехват возможных
ошибок. Это делается с помощью специальной
процедуры – обработчика ошибок.
Для
перехвата возможной ошибки в исполняемой
процедуре используется оператор On
Error. В нем указывается
метка, которая должна находиться в той
же процедуре и помечать тот фрагмент
кода, куда будет осуществлен переход
при возникновении ошибки выполнения.
Обычно этот фрагмент находится в конце
процедуры, а перед меткой помещается
операторExit, благодаря
которому процедура завершается, если
ошибка не возникла.
Обработка
ошибки начинается с установления типа
ошибки. Для этого используется объект
Err, свойство которогоNumber содержит код
последней возникшей ошибки.
После
обработки ошибки программа должна
продолжить свое исполнение. Для того,
чтобы программа продолжала выполняться
в строке, в которой возникла ошибка, в
обработчике указывается оператор
Resume. Если нужно
продолжить программу не с этой, а со
следующей строки, используется операторResume Next.
В
качестве примера рассмотрим процедуру,
которая запускается при нажатии кнопки
со знаком «/» в проекте «Простой
калькулятор» (Лекция №№). При этом
число, введенное в текстовое окноText1делится на число, введенное в окноText2, результат
заносится в окноText3.
Возможная ошибка – деление на ноль.
Обработка ошибки может выглядеть
следующим образом.
On
Error GoTo ошибка
Z=
Val
(InputBox(“Введите
число, не равное нулю”))
Если
в программе возможно появление нескольких
ошибок, их можно обработать, предварительно
определив их код и в зависимости от
кода применить тот или иной метод. В
табл.11 приведены описания основных
ошибок этапа выполнения программы.
Таблица
11. Коды основных ошибок
Код
ошибкиОшибка
выполнения6Переполнение7Мало
памяти11Деление
на ноль13Несовпадение
типов35Подпрограмма
или функция не заданны53Файл
не найден55Файл
уже открыт57Ошибка
устройств ввода-вывода75Ошибка
доступа к файлу
Ошибки в структуре программы.
Ошибки
такого рода появляется в результате
неправильного написания многострочного
оператора (например, в операторе цикла
Forнет последней
строки со словомNext
или в уловном оператореIfнетEnd If).
Переполнение стека
Все компиляторы С используют стек для хранения локальных переменных, адресов возврата и передаваемых функциям параметров. Однако стек не безграничен, и, в конце концов, может быть исчерпан. Тогда попытка записи очередного элемента в него приведет к переполнению стека. Когда такое происходит, программа или полностью «умирает», или продолжает выполняться в ненормальном причудливом стиле. Самое неприятное в переполнении стека заключается в том, что оно в большинстве случаев происходит безо всякого предупреждения и оказывает на программу столь серьезное воздействие, что определить, что именно было сделано неправильно, иногда бывает невероятно трудно. Единственной приемлемой подсказкой может служить то, что в некоторых случаях переполнение стека вызвано выходом из-под контроля рекурсивных функций. Если в вашей программе используются рекурсивные функции и вы столкнулись с необъяснимыми сбоями в ее работе, проверьте условия завершения в рекурсивных функциях.
И еще одно замечание. Некоторые компиляторы позволяют увеличить объем памяти, резервируемой под стек. Если ваша программа во всем остальном не имеет ошибок, но быстро исчерпывает стековое пространство (возможно из-за глубокой степени вложенности или рекурсивности функций), необходимо просто увеличить размер стека.
Ошибки, вызванные «потерей» данных
Как известно, в С нумерация индексов любого массива начинаются с нуля. Тем не менее, даже опытные профессионалы в пылу творческого вдохновения, бывало, забывали это общеизвестное правило! Рассмотрим следующую программу, которая, как предполагается, должна инициализировать массив из ста целых чисел:
Помните, в массиве из 100 элементов элементы пронумерованы числами от 0 до 99.
Проблемы с указателями
Очень распространенной ошибкой в С-программах является неправильное применение указателей. Проблемы с указателями условно можно разделить на две основные категории: неправильное представление об использовании косвенной адресации и об операциях над указателями вообще, а также случайное (точнее непредумышленное) применение недействительных или неинициализированных указателей. Решить первую проблему несложно: просто разберитесь окончательно и до конца в том, что означают операторы * и &! Справиться со второй категорией проблем с указателями несколько сложнее.
Ниже приведена программа, иллюстрирующая оба типа ошибок, связанных с указателями:
При запуске такой программы скорее всего произойдет ее сбой. Объясняется это тем, что значение адреса, возвращаемого функцией malloc(), не было присвоено указателю р, а было размещено в ячейку памяти, на которую указывает р, адрес которой в данном случае неизвестен (и в общем случае, непредсказуем). Данный тип ошибки представляет пример фундаментального непонимания выполнения операторов над указателями (а именно выполнения операции *). Как правило, такая ошибка в программах на С допускается начинающими программистами, но иногда эта нелепая оплошность встречается и у опытных профессионалов! Чтобы исправить эту программу, необходимо заменить строку с ошибкой следующей корректной строкой:
*р = (char *) malloc(100); /* эта строка правильная */
Кроме того, данная программа содержит еще одну, причем более коварную ошибку. В ней отсутствует динамическая проверка значения адреса, возвращаемого функцией malloc(). Помните, если память будет исчерпана, malloc() возвратит значение NULL, а тогда указатель использовать нельзя. Использование NULL в качестве указателя объекта недопустимо и практически всегда ведет к аварийному завершению программы. Вот исправленный вариант данной программы, в который включена проверка допустимости указателя:
Следующая часто встречающаяся ошибка заключается в том, что программист забывает инициализировать указатель перед использованием. Обратимся к следующему фрагменту программы:
int *x;
*x = 100;
Выполнение такого кода обязательно приведет к проблемам, поскольку указатель х не был инициализирован, а значит, едва ли можно ожидать, что он указывает туда, куда нужно. Фактически вы не знаете, куда указывает х. Присвоение какого-либо значения этой неизвестной области памяти может разрушить что-то, имеющее огромное значение, например другой фрагмент программы или данные.
Самая большая неприятность с «дикими» (т.е. непредсказуемыми) указателями состоит в том, что их невероятно тяжело обнаружить. Если вы присваиваете значение посредством указателя, который не содержит действительный адрес, ваша программа в одних случаях может функционировать вполне корректно, а в других — завершаться аварийным отказом. Чем меньше размер программы, тем выше вероятность, что она будет работать правильно, даже с «блуждающим» указателем. Это объясняется тем, что в таком случае программой используется очень маленький объем памяти, поэтому довольно велики шансы того, что указатель-нарушитель указывает на неиспользуемую область памяти. Но по мере увеличения объема программы подобные сбои будут происходить все чаще и чаще. Но вы скорее попытаетесь объяснить их последними внесенными в программу дополнениями или изменениями, и вряд ли свяжете с ошибками в использовании указателей. Следовательно, вы будете искать ошибки совершено не в том месте.
Возможно, утешением, станет то, что хотя указатели могут доставить множество хлопот, тем не менее, они являются одним из наиболее мощных средств языка С и стоят преодоления любой проблемы, которую они могут вам преподнести. Просто постарайтесь с самого начала изучить их правильное применение.
Причиной
возникновения синтаксической ошибки
могут быть неправильно написанные
ключевые слова, ошибки применения
разделителей или недопустимы комбинации
операторов. Visual Basic
распознает синтаксические ошибки
сразу же после того, как курсор покидает
эту логическую строку. Логическая строка
может состоять из нескольких физических
строк, разделенных символом подчеркивания
(_).
При
обнаружении ошибки Visual
Basic выдает сообщение с
подробным пояснением ошибки. Таки
сообщения достаточно информативны и
позволяют легко определить причину
возникновения ошибки и устранить ее.
Интерпритация синтаксических ошибок
Время от времени вы будете сталкиваться с синтаксическими ошибками, сообщения о которых покажутся вам абсурдными и бессмысленными. То ли сообщение об ошибке зашифровано, то ли ошибка, описание которой приводится в сообщении, вообще не похожа на ошибку. Тем не менее, в большинстве случаев в вопросах обнаружения ошибок компилятор оказывается прав. Просто в подобных случаях сам текст сообщения об ошибке чуть-чуть не дотягивает до совершенства. При поиске причин необычных синтаксических ошибок, как правило, необходимо при чтении программы немного возвратиться назад. Поэтому, если вы столкнулись с сообщением об ошибке, которое, судя по всему, не имеет смысла, попробуйте поискать синтаксическую ошибку одной двумя строками выше по тексту вашей программы.
С одной из особенно сногсшибательных ошибок можно познакомиться ближе, если вы попытаетесь скомпилировать следующий код:
Ваш компилятор выдаст сообщение об ошибке вместе с таким вот разъяснением:
Type mismatch in redeclaration of myfunc(void)
(Несоответствие типов при повторном объявлении myfunc(void))
Это сообщение относится к строке листинга программы, которая помечена комментарием о наличии ошибки. Как такое возможно? Ведь в этой строке нет двух функций myfunc(). А разгадка состоит в том, что прототип в верхней строке программы показывает, что myfunc() возвращает значение типа указатель на символ. Это ведет к тому, что в таблице идентификаторов компилятор заполняет строку, содержащую эту информацию. Когда затем в программе компилятор встречает функцию myfunc(), то теперь тип результата указывается как int. Следовательно, вы «повторно объявили», другими словами «переопределили» функцию.
Другая синтаксическая ошибка, которую трудно сразу правильно истолковать, генерируется при попытке скомпилировать следующий код:
Здесь ошибка состоит в наличии точки с запятой после определения функции func1(). Компилятор будет рассматривать это как выражение, находящееся за пределами какой бы то ни было функции, что является ошибкой. Однако различные компиляторы по-разному сообщают об этой ошибке. Некоторые компиляторы выводят в сообщении об ошибке такой текст:
bad declaration syntax (неправильный синтаксис объявления)
,и в то же время указывают на первую открытую скобку после функции func1(). Поскольку вы привыкли в конце выражений ставить точку с запятой, подобную ошибку очень трудно заметить.
Пропуск прототипов функций
В современной среде программирования отсутствие даже одного прототипа функции является непростительным упущением, «отступничеством» от мудрых принципов и здравого смысла. Чтобы понять почему именно, рассмотрим следующую программу, которая выполняет умножение двух чисел с плавающей запятой:
В данном случае, поскольку прототип функции mul() отсутствует, при компиляции функции main() предполагается, что в результате выполнения mul() будет возвращена целочисленная величина. Но в действительности mul() возвращает число с плавающей запятой. Допустим, что для целого числа выделяется 4 байта, а для чисел двойной точности (double) — 8 байтов. Это значит, что в действительности только четыре байта из восьми, необходимых для двойной точности, будут использованы в операторе printf() внутри функции main(). Это приведет к неправильному ответу, выводимому на экран дисплея.
Чтобы исправить эту программу, достаточно создать прототип функции mul(). Корректный вариант программы будет выглядеть следующим образом:
В данном случае прототип указывает, что при компиляции функции main() необходимо учитывать, что функция mul() возвращает значение с удвоенной точностью.
Ошибки из-за нарушения границ
И в среде прогона программ, написанных на языке С, и во многих стандартных библиотечных функциях почти не имеется (а иногда они вообще отсутствуют) средств динамической проверки принадлежности к диапазону (т.е. средств контроля границ). Например, если в программе произойдет выход за границы массива, то такая ошибка может остаться незамеченной. Рассмотрим следующую программу, которая должна считывать строку символов из буфера клавиатуры и отображать ее на экране монитора:
В этом фрагменте нет очевидных ошибок кодирования. Тем не менее, вызов функции gets() с параметром s может косвенно привести к ошибке. В данной программе переменная s объявлена как массив символов (строка длиной в 10 знаков). Но что произойдет, если пользователь введет больше десяти знаков? Это приведет к выходу за границы массива s, и значение переменной var1 или var2, а возможно, и их обеих будет перезаписано. Следовательно, var1 и (или) var2 не будут содержать правильных значений. Это вызвано тем, что для хранения локальных переменных все С-компиляторы применяют стек. Переменные var1, var2, а также s могут располагаться в памяти так, как показано на рис. 28.1. (Ваш компилятор С может поменять порядок следования переменных var1, var2 и s.)
Предположим, что порядок распределения ячеек памяти совпадает с изображенным на рис. 28.1. Тогда, если произойдет выход за границы массива s, то дополнительные (лишние) символы будут помещены в область, в которой должна находиться переменная var2. Это практически уничтожит информацию, ранее записанную там.
Поэтому на экран будет выведено не число 10 в качестве значения обеих целых переменных, а в качестве значения переменной, поврежденной в результате выхода за границы массива s, будет отображено что-нибудь другое. А вы можете искать ошибку совсем в другом месте.
Рис. 28.1. Размещение в памяти переменных var1, var2 и s (исходя из предположения, что на целое число выделяется 2 байта)
В рассмотренной программе потенциальная ошибка из-за выхода за границы может быть исключена за счет применения функции fgets() вместо gets(). Функция fgets() предоставляет возможность устанавливать максимальное количество считываемых символов. Единственная проблема состоит в том, что fgets() считывает и сохраняет еще и символ разделителя строк, поэтому в большинстве приложений его необходимо будет удалять.
Ошибки при задании аргументов
Тип любого формального параметра, должен соответствовать типу фактического параметра. Хотя благодаря прототипам функций компиляторы могут обнаруживать многие несоответствия типов аргументов (параметров), они не могут обнаружить все. Более того, когда функция имеет переменное количество параметров, компилятор не может обнаружить несоответствие их типов. Например, рассмотрим функцию scanf(), которая принимает большое количество разнообразных аргументов. Не забывайте, что scanf() ожидает принять адреса своих аргументов, а не их значения. И никакая сила не сделает за вас правильную подстановку. Например, следующая последовательность операторов
int x;
scanf(«%d», x);
содержит ошибку, поскольку передается значение переменной х, а не ее адрес. Тем не менее, вызов этой функции scanf() будет скомпилирован без сообщения об ошибке, и лишь во время выполнения этого оператора выявится ошибка. Правильный вариант вызова функции scanf() приведен ниже:
Типы ошибок
При
отладке и выполнении программы могут
возникать ошибки четырех типов:
Ошибки,
связанные с неправильным синтаксисом
оператора (например, If
без Then).
Ошибки
такого типа появляются в результате
некорректного написания многострочных
операторов (например, For
без Next).
По сути, это синтаксические ошибки, но
Visual Basic
обрабатывает ошибки этого типа несколько
иначе.
Это
ошибки, проявляющиеся во время работы
программы (например, ошибка деления на
ноль).
Ошибки
такого типа самые каверзные. Программа
выполняет вычисления, но выдает
неправильный результат.
Проверка синтаксиса
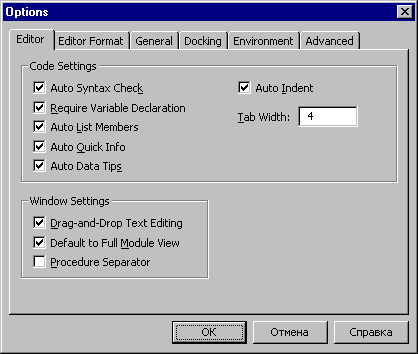
роверку
синтаксиса можно включить или отключить
с помощью опции AutoSyntaxCheck
вкладки Editor
диалогового окна 0ptions,
которое можно открыть с помощью команды
меню Tools ►
0ptions. Отключать проверку
синтаксиса имеет смысл только в тех
редких случаях, когда строка кода
формируется путем копирования готовых
фрагментов из других мест программы. В
этом случае при перемещении курсора в
окне кода постоянно появляются
раздражающие сообщения об ошибках,
причина которых и так известна
разработчику. В большинстве случаев
отключать проверку синтаксиса не
следует.
Строка
с синтаксической ошибкой выделяется
красным цветом. Повторная проверка
синтаксиса проверенных строк кода
выполняется только после внесения в
них изменений.
Применение отладчика
Многие компиляторы поставляются вместе с отладчиком, который представляет собой программу, помогающую отладить разрабатываемый код. В общем случае отладчики позволяют шаг за шагом исполнять код разрабатываемой программы, устанавливать точки останова и контролировать содержимое различных переменных. Современные отладчики, например такие, как поставляемые в составе пакета Visual C++, являются действительно замечательными инструментальными средствами, которые могут оказать существенную помощь в обнаружении ошибок в разрабатываемом коде. Хороший отладчик стоит дополнительного времени и усилий, которые необходимы на его изучение, чтобы в дальнейшем эффективно его применять. Как бы то ни было, хороший программист никогда не откажется от работы с отладчиком для реализации надежного проекта и выполнения тонких работ.
Теория отладки в общих чертах
Каждый разработчик имеет свой собственный подход в программировании и отладке. Тем не менее, длительный опыт показывает, что существуют технические приемы, которые значительно лучше, чем остальные. В отношении отладки считается, что наиболее эффективным методом в плане времени и стоимости является инкрементное (нарастающее) тестирование, даже если может показаться, что этот подход может замедлить на первых порах процесс разработки. Инкрементное тестирование является технологическим приемом, гарантирующим, что вы всегда будете иметь работоспособную программу. В чем же его суть? Уже на самых ранних стадиях процесса разработки функциональный блок. Функциональный блок — это просто фрагмент работающего кода. По мере добавления нового кода к этому блоку, он тестируется и отлаживается. Таким способом программист может обнаруживать ошибки без особого труда, поскольку, вероятнее всего, ошибки будут присутствовать в более новом коде (добавке) или возникать из-за плохого взаимодействия с функциональным блоком.
Время отладки прямо пропорционально общему количеству строк кода, в котором программист ищет ошибки. Благодаря инкрементному тестированию количество строк кода, в котором необходимо искать ошибки, ограничено как правило, количеством вновь добавленных строк. Другими словами, ошибка, скорее всего, содержится в строках, которые не входят в состав функционального блока. Эта ситуация проиллюстрирована на рис. 28.2. Любому программисту хочется минимизировать объем отлаживаемого фрагмента программы. Метод инкрементного тестирования позволяет не тестировать те участки, где эта работа уже была проведена. Таким образом, можно уменьшить область, в которой вероятнее всего прячется ошибка.
Рис. 28.2. При регулярном использовании метода инкрементального тестирования ошибки, если они есть, вероятнее всего находятся в добавленном коде
Крупные проекты часто можно разбить на несколько модулей, слабо взаимодействующих между собой. В таких случаях можно выделить несколько функциональных блоков, что позволит вести параллельную разработку проекта.
Инкрементное тестирование — просто технологический прием, благодаря которому который всегда можно иметь работоспособный код. Поэтому всякий раз, когда появляется возможность выполнить кусочек разрабатываемой программы, вы должны запустить его на выполнение и тщательно протестировать его. По мере добавления к программе новых фрагментов продолжайте тестировать их, а также их интерфейс с уже проверенным функциональным кодом. Этот способ позволяет разрабатывать программу так, что большинство ошибок будет сконцентрировано в небольшой области кода. Конечно, вы никогда не должны упускать из виду то, что ошибка могла быть пропущена и в функциональном блоке, но все же данный метод тестирования уменьшает вероятность такого случая.
