
Эта статья о логической ошибке в программировании. Об ошибках, связанных с нарушением логической правильности рассуждений, см. Логическая ошибка.
В программировании логической ошибкой называется баг, который приводит к некорректной работе программы, но не к краху программы.
Существование данного вида ошибок связано с неправильными действиями на этапе принятия решений.
В C++ логической ошибкой также называется особое исключение (logic_exception).
Общие причиныПравить
Ошибки могут быть связаны как с простейшими опечатками в написании операторов, так и в запутанном выборе веток алгоритма. Существует также масса других причин: некорректное приведение типа, использование переменной вне её области видимости, отсутствие фрагмента кода и ошибочное понимание разработчиком требований.
Отладка логических ошибокПравить
Одним из способов поиска этого типа ошибки является распечатка списка переменных в программе (во внешний файл или на экран). Хотя этот способ не работает, если ошибка заключается в вызове не той функции, он всё же является самым простым в случае неправильной реализации математического алгоритма.
ПримерыПравить
В этом примере задачей функции является возвращение среднего для двух переданных чисел. Ошибка кроется в неучёте приоритета операторов (деление в выражении вычисляется до операции сложения) и отсутствии по этой причине скобок.
- Синтаксическая ошибка (программирование)
- Ошибка на единицу
- Runtime error detection
Екатерина Андреевна Гапонько
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Виды ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
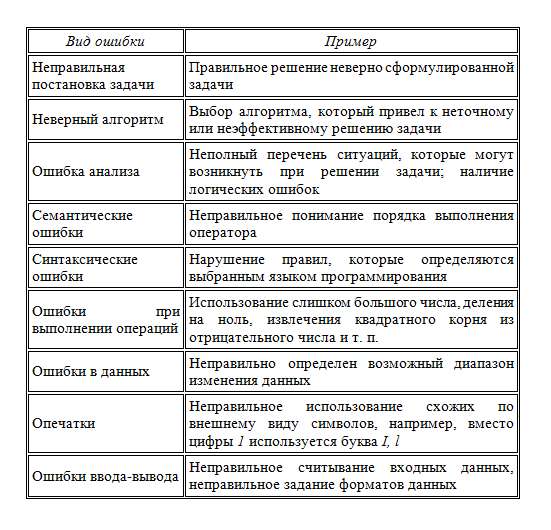
Рассмотрим более подробно некоторые из вышеприведенных видов ошибок.
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы.
Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примерами синтаксических ошибок является:
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
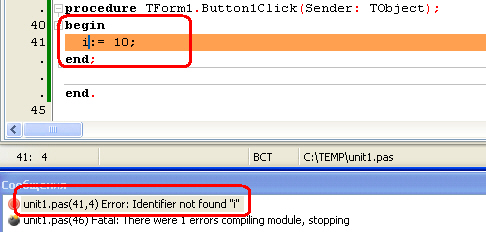
Синтаксическая ошибка «Не задан идентификатор»:
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
«Ошибки в программах » 👇
- после проверки заданного условия неправильно указана ветвь алгоритма;
- неполный перечень возможных условий при решении задачи;
- один или более блоков алгоритма в программе пропущен.
Ошибки в циклах:
- неправильно указано начало цикла;
- неправильно указаны условия окончания цикла;
- неправильно указано количество повторений цикла;
- использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными:
- неправильно задан тип данных;
- организовано считывание меньшего или большего объёма данных, чем нужно;
- неправильно отредактированы данные.
Ошибки в использовании переменных:
- используются переменных, для которых не указаны начальные значения;
- ошибочно указана одна переменная вместо другой.
Ошибки при работе с массивами:
- пропущено предварительное обнуление массивов;
- неправильное описание массивов;
- индексы массивов следуют в ошибочном порядке.
Ошибки в арифметических операциях:
- неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная);
- неправильно определен порядок действий;
- выполняется деление на нуль;
- при расчете выполняется попытка извлечения квадратного корня из отрицательного числа;
- не учитываются значащие разряды числа.
Ошибка в арифметических операциях «Деление на нуль»:

Все вышеописанные ошибки можно обнаружить методом тестирования.
Сопровождение программы
Сопровождением программ называются работы по обслуживанию программ в процессе их эксплуатации.
В случае многократного использования разработанной программы для решения различных задач определенного класса требуется проведение таких дополнительных работ, как:
- при обнаружении ошибок работы программы они должны исправляться;
- при изменении требований эксплуатации необходимая модификация программы;
- выполнение доработки программы с целью решения конкретных задач;
- выполнение дополнительных тестовых расчетов;
- внесение исправлений в рабочую документацию;
- улучшение программы и т.д.
При проведении работ по сопровождению многих программ стоимость этого сопровождения превышает половину затрат, которые приходятся на весь период времени существования программы (от разработки начального алгоритма до морального ее устаревания).
Программа, которая предназначена для длительной эксплуатации, должна сопровождаться соответствующей документацией и инструкцией по ее использованию.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Программная
ошибка
– это расхождение между программой и
её спецификацией, причём тогда и только
тогда, когда спецификация существует
и она правильная.
Программная
ошибка
– это ситуация, когда программа не
делает того, чего пользователь от неё
вполне обоснованно ожидает.
Ошибки
пользовательского интерфейса.
С программой может быть трудно (или даже
невозможно) работать по множеству
причин. Их все можно объединить под
названием “ошибки пользовательского
интерфейса”. Вот несколько разновидностей
таких ошибок.
Функциональность.
Функциональные недостатки имеют место,
если программа не делает того, что
должна, выполняет одну из своих функций
плохо или не полностью. Хотя функции
программы достаточно подробно описываются
в ее спецификации, окончательное
представление о том, что программа
должна делать, существует только в умах
ее пользователей.
Функциональные
недостатки есть абсолютно у всех
программ, поскольку ожидания пользователей
— вещь субъективная: у разных пользователей
они различны. Оправдать их все просто
невозможно, а попытка этого добиться
может привести лишь к усложнению и
потере концептуальной целостности
программного продукта.
Однако
во многих случаях функциональный
недостаток вполне очевиден. Если
предусмотренную программой задачу
трудно выполнить, если она решается
неуклюже или при определенных
обстоятельствах вообще не может быть
решена — проблема налицо. И когда ожидания
пользователей вполне разумны и
обоснованны, эту проблему без колебаний
можно назвать ошибкой.
Взаимодействие
программы с пользователем. Насколько
сложно пользователю разобраться в том,
как работать с программой? Откуда вообще
он об этом узнает? Как обстоит дело с
экранными инструкциями и подсказками?
Достаточно ли их? Понятны ли они? Имеется
ли в программе интерактивная справка
и может ли пользователь в случае
затруднений найти в ней реальную помощь?
Насколько корректно программа сообщает
пользователю о его ошибках и объясняет,
как их исправить? Нет ли в программе
элементов, которые могут раздражать
пользователя, сбивать его с толку или
просто выглядеть неуклюже?
Организация
программы.
Насколько легко потеряться в вашей
программе? Нет ли в ней непонятных команд
или таких, которые легко спутать между
собой? Какие ошибки чаще всего делает
пользователь, на что он тратит больше
всего времени и почему?
Пропущенные
команды.
Чего в программе не хватает? Не заставляет
ли программа выполнять некоторые
действия странным, неестественным или
крайне неэффективным способом? Нельзя
ли привести ее в соответствие с привычным
стилем пользователя? Допускает ли она
хотя бы некоторую степень настройки?
Производительность.
В интерактивном программном обеспечении
очень важна скорость. Плохо, если у
пользователя создается впечатление,
что программа работает медленно, если
он чувствует задержки в ее реакции
(особенно если конкурирующие программы
работают ощутимо быстрее).
Выходные
данные.
Большинство программ так или иначе
формируют выходные данные: отображают
информацию на экране, печатают ее или
сохраняют в файлах. Получаете ли вы то,
что хотите? Правильно ли формируются
отчеты, наглядны ли диаграммы и достаточно
ли отчетливо они выглядят на бумаге?
Сохраняются ли данные в формате, доступном
и для других аналогичных программ?
Обладает ли программа достаточной
гибкостью, чтобы можно было подстраивать
ее под нужды конкретного пользователя?
Обработка
ошибок. Процедуры
обработки ошибок — это очень важная
часть программы. Но, к сожалению, в них
тоже очень часто встречаются ошибки.
Кроме того, правильно определив ошибку,
программа не всегда выдает о ней
достаточно информативное сообщение.
Ошибки,
связанные с обработкой граничных
условий.
Простейшими граничными условиями
являются числовые. Но существует и много
других граничных ситуаций. Любой аспект
работы программы к которому применимы
понятия больше или меньше, раньше или
позже, первый или последний, короче или
длиннее, обязательно должен быть проверен
на границах диапазона. Внутри диапазонов
программа обычно работает прекрасно,
а вот на их границах случаются самые
неожиданные отклонения.
Ошибки
вычислений.
Программирование даже самых простых
арифметических операций чревато
ошибками. Нечего и говорить о сложных
формулах и расчетах. Одними из самых
распространенных среди математических
ошибок являются ошибки округления.
После нескольких промежуточных вычислений
может оказаться, что 2 + 2 = -1, даже если
на промежуточных этапах не было логических
ошибок.
Ошибки
начального и последующих состояний.
Бывает, что при выполнении какой-либо
функции программы сбой происходит
только однажды — при самом первом
обращении к этой функции. Причиной
такого поведения программы может быть
отсутствие файла с инициализационной
информацией. После первого же запуска
программа создаст такой файл, и дальше
все будет в порядке. Получается, что
такую ошибку невозможно повторить
(точнее, для ее повторения нужно установить
новую копию программы). Но не стоит
думать, что ошибка, проявляющаяся только
при первом запуске программы, безвредна:
ведь это будет первое, с чем столкнется
каждый новый пользователь. Иногда,
программируя процесс, связанный с
последовательными преобразованиями
информации, разработчики забывают о
том, что пользователю может понадобиться
вернуться к исходным данным и изменить
их. Насколько корректно поведет себя
программа в такой ситуации? Позволит
ли она внести нужные изменения и не
будет ли из-за этого потеряна вся
выполненная пользователем работа? Что
увидит пользователь при возвращении к
исходному состоянию программы: свои
данные или стандартные значения, которыми
программа инициализирует переменные
при запуске?
Ошибки
передачи или интерпретации данных.
Один модуль может передавать данные
другому или даже другой программе.
Некоторые данные могут передаваться
между модулями множество раз, и на
каком-то этапе они могут быть разрушены
или неверно интерпретированы. Изменения,
внесенные одной из частей программы,
могут потеряться или достичь не всех
частей системы, где они важны.
Ситуация
гонок. Классическая
ситуация гонок описывается так.
Предположим, в системе ожидаются два
события, А и Б. Первым может произойти
любое из них. Но если первым произойдет
событие А, выполнение программы
продолжится, а если первым наступит
событие Б, то в работе программы произойдет
сбой. Программист полагал, что первым
всегда должно быть событие А, и не ожидал,
что Б может выиграть гонки. Тестировать
ситуации гонок довольно сложно. Наиболее
типичны они для систем, где параллельно
выполняются взаимодействующие процессы
и потоки, а также для многопользовательских
систем реального времени. Ошибки в таких
системах трудно воспроизвести, и на их
выявление обычно требуется очень много
времени.
Перегрузки.
Программа может не справляться с
повышенными нагрузками. Например, она
может не выдерживать интенсивной и
длительной эксплуатации или не справляться
со слишком большими объемами данных.
Кроме того, сбои могут происходить из-за
нехватки памяти или отсутствия других
необходимых ресурсов. У каждой программы
свои пределы. Вопрос в том, соответствуют
ли реальные возможности и требования
программы к ресурсам спецификации, и
как программа себя поведет при перегрузках.
Некорректная
работа с аппаратным обеспечением.
Программы могут посылать устройствам
неверные данные, игнорировать сообщения
об ошибках, пытаться использовать
устройства, которые заняты или вообще
отсутствуют. Даже если нужное устройство
просто сломано, программа должна понять
это, а не сбоить при попытке к нему
обратится.
Ошибки
документации.
Сама по себе документация не является
программным обеспечением, но все же это
часть программного продукта. И если она
плохо написана, пользователь может
подумать, что и сама программа не намного
лучше.
Ошибки
тестирования.
Обнаружение ошибок, допущенных
тестировщиками, — дело обычное. Конечно,
если таких ошибок будет слишком много,
вы быстро потеряете доверие остальных
членов команды. Но нужно иметь в виду,
что иногда ошибки тестировщика отражают
проблемы пользовательского интерфейса:
если программа заставляет пользователя
делать ошибки, значит, с ней что-то не
так. Конечно, многие ошибки тестирования
вызваны просто неверными тестовыми
данными.
- Дайте
определение понятия «программная
ошибка». - Перечислите
источники ошибок
программного обеспечения. - Классифицируйте
ошибки программного обеспечения.
Учебный курс по теории и практике программирования. Бесплатно. В виде структурированного текста. Статья 3. Эта статья посвящена ошибкам программ, их классификации и способам исправления.
Предупреждение об использованных материалах и правах
1 Методики поиска и классификации ошибок
Данная статья является компиляцией материала трёх лекций, посвященных ошибкам. Такой формат выбран отчасти из-за нехватки времени, отчасти из-за нежелания спамить статьями и также из-за постоянного желания улучшить и так неплохое.
Так как курс нацелен на повышение качества программы, нам необходимо понимание того, что приводит к его снижению. Эта лекция в нескольких приближениях даст образы «врага». От простого и четкого, до более сложного и подробного. Помимо этого, в специальном разделе, будут приведены примеры типичных ошибок, способы исправления и обхода.
Хочу напомнить, что несмотря на то, что рекомендации так или иначе исходят их опыта работы отдела разработки или проектной команды, излагаемые принципы и методики легко масштабируются до отдельного программиста.
1 Что такое ошибка
В первой части вводной лекции, мы приняли простое определение качества программы, из которого мы можем вывести такое же простое определение ошибки:
Ошибка – это свойство программы, приводящее к ухудшению её качества по любому из трёх критериев качества: работоспособности, сопровождаемости, гибкости.
Прошу задержать внимание на определении, так как мне приходилось часто наблюдать проблемы, связанные с непониманием того, что считать ошибкой.
Например, встречал случаи, когда на официальном уровне ошибкой считалось только то, о чем сообщили пользователи. Изменения можно было вносить только по заявкам конечных пользователей, и найденный в ходе чтения кода баг, не мог быть легально исправлен, кроме как партизанскими методами, путем сочинения писем пользователям, с просьбой зарегистрировать их как обращения от своего имени.
Крайне важно понимать, что ошибка — это имманентное свойство текущей версии программы, а не некоторое событие, явление или баг-репорт и уж тем более не исключение (exception), которое во многих случаях ошибкой не является.
2 Классификация ошибок
Классификация есть обобщение массива ошибок с целью облегчения работы с ними. Классификация является наглядным примером абстракции с её достоинствами и недостатками. Структурирование и обобщение больших объемов данных, позволяет их легче обрабатывать и осознавать. От осознания очень сильно зависит качество работы интуиции. Чем глубже понимание базиса вещей, тем чаще случаются «внезапные озарения». Но не стоит забывать о недостатках абстракций и всегда иметь их ввиду.
Видов классификации может быть больше, чем число ошибок, поэтому обобщение классификаций для практических нужд я выполняю по функциональному назначению. В рамках такого подхода выделяются две основные функции классификации:
Управление процессом обнаружения и исправления ошибок.
При значительном количестве ошибок, применение классификации многократно повышает эффективность их исправления. В основном это достигается за счет облегчения идентификации и локализации. При налаженной статистике появляется возможность работы на упреждение – исправление ошибок до их возникновения у конечного пользователя.
Распределение трудовых ресурсов
Является частным случаем управления ошибками, но ввиду распространенности и полезности, не нуждающейся в особых доказательствах, я выделяю эту функцию отдельно. На больших проектах или в штате крупных предприятий суммарная трудоёмкость на исправление ошибок (если их действительно регистрировать) может существенно превышать доступную ёмкость фонда рабочего времени. Также, разные специалисты с разной эффективностью решают различные проблемы: кто-то въедлив и усидчив и легче находит даже хорошо спрятанные ошибки, кто-то хорошо владеет языком и может превратить невнятный запутанный код в ясное изложение. Таким образом, классификация ошибок будет хорошим подспорьем в деле распределения трудовых ресурсов.
В зависимости от специфики предприятия или отдельного проекта, могут применяться различные классификации. Здесь я опишу базовые и некоторые специальные классификации, которые мне приходилось использовать. Прошу обратить особое внимание на определение классификации и их типизацию по функциональному назначению. Не стоит создавать детальную классификацию по принципу «чтобы было», там, где достаточно простой и обобщенной. Если в классификации будет множество неиспользуемых деталей, то со временем, она из помощника превратится в тяжелую повинность и инструмент угнетения.
Здесь будут описаны применявшиеся в реальной практике классификации и сценарии их использования.
Это основная и во многих случаях достаточная классификация. Её суть следует из самого определения ошибки, и эта классификация уже была определена в предшествующих лекциях. Здесь я сделаю финальное определение базовой классификации: все ошибки получают оценку по каждому из трёх критериев качества программы. При этом, из Работоспособности, может выделяться быстродействие, остальные свойства – по необходимости.
Имея информацию о свойствах ошибки, мы можем принимать осознанные решения о концентрации усилий на том или ином направлении. Если ошибки, влияющие на сопровождаемость обнаружены в модуле, который уже давно не редактируется и практически не используется, то нет никаких оснований бросаться на него, при наличии другой работы, но если это активно используемый или часто изменяемый код, то обеспечить его сопровождаемость будет крайне необходимо. Или, наоборот, имея данные наблюдений о низком быстродействии программы, мы будем внимательнее рассматривать ошибки, влияющие на быстродействие.
Классификация по терпимости ошибки
Данная классификация является расширением базовой классификации, т.к. наследует из нее всё те же критерии, но расчет интегральной стоимости ошибки производится по индивидуальному алгоритму, либо с использованием коэффициента.
Подобный подход, необходим для лучшей адресации усилий по исправлению ошибок. Несложно представить, что ошибки с одинаковой интегральной стоимостью могут находиться в разных разделах программы с разной чувствительностью к ошибкам. Например, для проектной команды, получающей оплату по итогам промежуточной приёмки, демонстрация функциональности или рабочий стол директора/собственника, это не то время и место, где они хотели бы увидеть ошибки. А фикси программист, будет иметь много проблем если из-за небольшой ошибки с низким приоритетом, остановился или замедлился важный процесс предприятия. Следовательно, необходима уточняющая классификация, позволяющая двигать действительно критичные ошибки вверх по шкале приоритетов. Даже при отсутствии автоматизированной оценки, всегда остаётся возможность принудительно сделать исправление ошибки сверхприоритетным. Если же углубиться в построение инструментов, то для места возникновения ошибки, можно определить коэффициент (0,5 или 2) или особую формулу («всегда самый высокий» или «ставим в самый низ»).
За скобками я оставляю концепцию управления рисками, но необходимо иметь ввиду, что управление рисками как система, напрямую взаимодействует с данной классификацией, даже если управление рисками происходит только в голове единственного в штате фикси-разработчика.
Классификация по трудоёмкости исправления
Оценочная трудоемкость является общим инструментом в планировании работ, а если принять трудоемкость как стоимость в ресурсах, то планирования вообще. Таким образом, если необходимость в планировании назрела, то работа с оценкой трудоемкости является одним из важнейших инструментов.
В практике программирования, зачастую, это достаточно сложная для полноценного применения классификация. Сложность заключается в низкой точности предварительной оценки трудоёмкости. Чтобы точность повысить, отделу разработки необходимо перейти на качественно иной уровень, когда точность оценки достаточно высока для детального планирования. Но и с низкой точностью предсказания есть возможность использовать классификацию, как минимум, для определения приоритетов. Например, у вас есть 10 ошибок примерно одинаковой вредности. Но одна из них предварительно оценивается в 40 часов, тогда как остальные, даже по пессимистичным оценкам укладываются в 1-8 часов. В большинстве случаев, оптимальным решением будет «поискать под фонарём» — в первую очередь обработать те ошибки, которые можно быстро исправить. Причина проста — затратив те же 40 часов или меньше, вы исправите девять ошибок а не одну. При этом шанс выбиться из графика много ниже. Ведь не стоит забывать, что сложно оценить трудоёмкость более 16 часов без декомпозиции, и вполне возможно, что 40 часов это довольно оптимистичный прогноз. Также, большой объем изменений предполагает более объемное тестирование, и потенциально может увеличить затраты времени в несколько раз. Даже если затраты будут связаны с выявлением ранее не обнаруженных ошибок, которые в старом ошибочном коде не воспроизводились, то это всё равно затраты времени, вызванные исправлением одной ошибки.
Если же вы способны точно оценивать трудоёмкость, то все инструменты планирования становятся доступны. Наиболее ценными в моей практике являлись два инструмента:
— составление графика релизов и план-графика по проектам. Речь идет о действительно точных графиках, а не о наборе пожеланий и обещаний, выполняемых ценой авралов и превозмоганий.
— балансировка нагрузки разработчиков и составление индивидуальных планов. В своё время проводил опыты с линейным программированием, но, к сожалению, не хватило времени довести их до конца. Но так или иначе, для черновых расчетов использовал методы линейного программирования.
Соображения в пользу применения подобной классификации весьма просты – любой процесс планирования очень сильно упрощается при сокращении числа неизвестных, особенно если эта неизвестная одна из основ планирования.
Классификация по пригодности к формализации
На практике эта классификация довольно проста, но всё зависит от организации процесса, поэтому помимо особенностей классификации я опишу методику применения.
Основное назначение данной классификации – автоматизация поиска ошибок. Всякий раз находя ошибку в релизе, есть большое желание в следующий раз найти её автоматическими средствами еще на этапе разработки. Это далеко не всегда удаётся, но если ошибка была формализована хотя бы частично, то её обнаружение значительно облегчится, т.к. в голове уже будет готовый паттерн.
В моей практике эта классификация применялась следующим образом: при регистрации новой ошибки производилась её типизация. Если ошибка встречалась ранее, то проверяется уровень её формализации и по необходимости уточняется. Если ошибка ранее не встречалась, то описывается новый тип ошибки с неизвестным уровнем формализации. Специально назначенный человек по запросу или по расписанию проверяет пригодность к формализации. Полностью формализуемые ошибки рано или поздно попадают в средства автоматической проверки, частично формализуемые в паттерны поиска ошибок (инструкции разработчикам) и иногда в автоматические проверки, если число ложных срабатываний не слишком велико, чтобы замусорить отчеты о проверке.
Приведу уровни формализации, обычно используемые в описанной схеме:
— Не определен
— Не поддаётся формализации. Стараться избегать такого определения. Это или лень или очень-очень плохой код.
— Формализуется частично. Такой уровень пригоден для ручного использования.
— Полностью формализуется. Этот уровень — показание к полной автоматизации поиска ошибки.
— Внедрено в автоматические средства проверки. В идеале, ошибки с таким уровнем формализации не должны попадаться позже этапов разработки и тестирования, но всё в ваших руках.
3 Как искать ошибки
Казалось бы, странный вопрос – зачем искать ошибки, если они сами себя прекрасно находят. Но как говорилось выше, это лишь вершина айсберга, и для получения полноценной информации об ошибках необходимо применять более продвинутые методы поиска.
Главное, о чем нужно помнить, что ошибка должна быть обнаружена как можно ближе к моменту её появления как свойства программы, а не как события в работе программы. Ниже приведу шесть методов поиска, упорядоченных по примерной хронологии и по убыванию желательности обнаружения на данном этапе.
Поиск в процессе разработки
На этом этапе может быть отсеяна львиная доля ошибок. Здесь применяется ревью кода и первичное тестирование. Способ этот ценен тем, что ошибка, найденная разработчиком в процессе разработки, гораздо легче и быстрее исправляется. Ведь программист уже погружен в контекст ошибки и накладные расходы минимальны.
Независимо от того занимаются ли сами разработчики поиском ошибок и тестированием, необходимость инспекции кода вполне очевидна.
Во-первых, инспектор может быть не погружен в контекст, но он как правило видит общую картину и глаз его не «замылен».
Во-вторых, сам факт наличия организованного процесса инспекции кода приводит к повышению качества выпускаемого кода.
В-третьих, инспектор, будучи более квалифицированным специалистом, сможет увидеть проблемы неочевидные для рядовых разработчиков.
Момент проведения инспекции вопрос обсуждаемый. Обычно инспекцию проводят перед отправкой на тестирование функциональности, но после автоматической проверки и первичных тестов самим разработчиком. Такая схема позволяет снизить нагрузку на инспектора, и в то же время уже до этапа объёмного и комплексного тестирования сократить число ошибок.
Под профилированием здесь обобщенно понимается комплекс мер по снятию и анализу различных метрик работы программы. Перечислю вкратце наиболее доступные методики:
— Замер производительности. Можно выполнять и встроенными средствами для чернового результата, но лучше использовать более точные замеры с логированием факта и времени событий.
— Поиск узких мест в алгоритмах. Здесь вполне подойдет встроенный в платформу 1с замер производительности. Но смотреть здесь будем не время, а количество вызовов. Таким образом легко и дешево выявляются нагруженные участки кода, на которые необходимо обратить внимание. Как правило, при вводе в эксплуатацию этого метода, число найденных ошибок резко возрастает и по мере их исправление производительность программы начинает расти.
— Поиск проблем в конвертации запросов из языка 1с в язык СУБД. Как многие из вас знают, запросы, написанные в 1с, интерпретируются в язык используемой СУБД. В процессе интерпретации неоптимальных запросов, могут рождаться «монстры». В MS SQL Server есть специальный инструмент, который так и называется «Profiler». С другими СУБД знаком слабо, но полагаю, аналогичные возможности есть и там.
Тестирование может быть, как простым, так и комплексным процессом. Элементы тестирования могут применяться уже на этапе разработки в виде синтаксического и семантического контроля кода. При этом синтаксический анализ выполняется автоматически, средствами платформы, а семантический требует либо отдельных инструментов, либо применения паттернов для поиска ошибок (см. раздел 1.2.4 текущей статьи). Но именно на семантическом уровне и расположены главные гнёзда ошибок.
Разумеется, нельзя забывать и о функциональном тестировании, когда программа пропускается через различные рабочие сценарии вручную или автоматически. Такой способ тестирования несмотря на очевидную простоту, находит, как ни странно, самые очевидные ошибки, избавляя разработчика от довольно трудоёмкой работы по поиску ошибок логически. Лучшим подходом будет являться разработка через тестирование, когда классы проектируются сразу с тестами, но практически такой подход встречается довольно редко. Обычно главные проблемы применения TDD это сложность подбора тестовых данных и повышение трудоёмкости разработки из-за фактического удвоения объёма работ. Но на простейшем уровне, для отсечения наиболее обидных ошибок применять подобный подход, не увеличивая затраты времени.
Анализ логов работы и разбор исключений
Данный способ применяется уже не только к тестовым версиям, но и к продуктовым релизам. Общая схема такова:
Логирование работы наиболее важных участков кода. Не встречал необходимости логировать всё. А вот противопоказания к логированию есть — чем больше делается записей, тем меньше шансов, что их будут читать. Поэтому логируем только то, что необходимо.
Анализ ошибок (уровень регистрации) в журнале регистрации. Данный подход неплох сам по себе, при условии уверенного парсинга записей журнала. Рабочая база содержит очень много записей об ошибках, но ошибками являются далеко не все. Второй путь — перехват исключений и регистрация их в нужном формате. Первый подход безальтернативно для типовых, второй — для самописных конфигураций или новых подсистем в типовых.
Жалобы и пожелания пользователей
Если ошибка пробралась незамеченной через все выставленные заслоны (или свободно прошла через неохраняемую зону), то конечные пользователи без сомнения выявят наиболее заметные и неприятные из них.
У способа есть ряд недостатков:
— Ошибка, найденная конечными пользователями, прямо означает, что IT со своей работой справляется плохо. Пусть это вызвано объективными причинами, и ребята не виноваты, но вывод простой и очевидный.
— Далеко не все ошибки регистрируются. Лишь самые надоедливые и мешающие работе дойдут до программистов. Упрощение отправки багрепорта или его автоматизация, несколько сглаживает проблему, но окончательно не устраняет.
— Накладные затраты на работу с ошибками, происходящими у конечных пользователей выше, чем на предшествующих этапах.
Наблюдение за работой пользователей
Помимо автоматических средств контроля, существует довольно эффективный метод поиска ошибок. Суть его заключается в прямом физическом наблюдении за работой пользователя. Подчеркиваю, что речь идет о физическом наблюдении. Средства удаленного наблюдения за экраном пользователя, без наблюдения самого пользователя даёт неполную и часто искаженную картину.
В личной практике, подобный метод наиболее эффективно применялся при поиске ошибок в пользовательском интерфейсе. Использование данной методики для нагруженных операциями интерфейсов, позволяло улучшить фактическое быстродействие программы, за счет повышения эргономичности форм. Результат в цифрах может различаться в зависимости от стартовых условий, но обычно наблюдался эффект роста реального быстродействия программы 1,5-3 раза.
4 Когда и как лучше всего исправлять ошибки
В предыдущем разделе мы уже частично ответили на этот вопрос – как можно раньше. Чем раньше ошибка обнаружена, тем меньше расходов понесет предприятие.
Да, грамотная организация процесса разработки, инспекции кода и тестирование сократят число ошибок в продуктовых релизах в десятки раз, но не сведет их до нуля. Поэтому не стоит расслабляться если вы организовали хороший контроль на первых этапах выпуска релиза – ошибки всё равно неизбежны. Разумеется, главная цель — это найти и обезвредить ошибку до того, как она сможет нанести ущерб, но искать и регистрировать ошибки необходимо ВСЕГДА. Даже там, где ошибки быть не может, всё равно необходимо искать.
Позже, мы еще будем возвращаться к причинам возникновения ошибок, но здесь я бы хотел отметить еще одно место и время возникновения множества ошибок. Это голова архитектора. Хорошая архитектура сама по себе снижает риск возникновения ошибок или упрощает их локализацию. При этом не принципиально, идет ли речь об архитектуре базы данных или программного кода отдельного модуля – хорошая продуманная архитектура является наиболее эффективным средством борьбы с ошибками. Именно на этапе планирования новых объектов приложения, борьба с ошибками наиболее эффективна. Тогда как плохая архитектура может заставить даже неплохих разработчиков принимать плохие решения. Ниже в порядке убывания эффективности приведу список мероприятий по исправлению ошибок:
Планирование архитектуры приложения
Каждый дополнительный час, потраченный на обдумывание структуры приложения до его разработки, экономит десятки часов на исправление ошибок или обход ограничений архитектуры и вызванные этим ошибки.
Перманентный рефакторинг в процессе разработки.
По эффективности я поставил этот метод на второе место, только в рамках определения эффективности как отношение объема работы к затраченному времени. В ходе выполнения работ, программист может исправить ошибки в затронутых фрагментах программы. Он это сделает быстро, но количество выполненной работы не может быть велико, если модифицируемый фрагмент программы связан с не очень хорошо спроектированными частями.
Как бы не давили дедлайны, необходимо резервировать из фонда рабочего времени хотя бы небольшой процент на рефакторинг. Начните с 1-5% и устраивайте дни рефакторинга. После того как получите наглядные результаты, можно пробовать увеличивать резерв времени на рефакторинг.
Обработка инцидентов в продуктовых базах
Самая неприятная, но в большинстве случаев неизбежная работа. Единственное что можно сделать, это кардинально сократить число ошибок, доходящих до рабочих релизов. Но так как ошибки неизбежны, необходимо приложить усилия к налаживанию системы регистрации инцидентов и всегда иметь резерв на случай непредвиденных ситуаций.
В рамках отдела резерв обеспечивается дежурствами или выделением отдельного специалиста для работы на последних линиях поддержки, если речь идет об отдельном программисте (частая ситуация для небольших предприятий), то необходимо планировать свою работу так, чтобы всегда можно было оперативно переключиться оперативные проблемы.
2 Примеры ошибок, их происхождение, способы обхода и исправления
В этом разделе будут приведены примеры наиболее часто встречающихся ошибок, попытка понять их происхождение и методы устранения.
Для каждого типа ошибки будут приведены основные свойства данного типа как-то: формализуемость; свойства программы, на которые негативно влияет ошибка; потенциально затрагиваемые свойства при исправлении ошибки.
Важно! Этот раздел является иллюстративным примером описания ошибок как явления, и не предполагался как исчерпывающий список ошибок или филиал лепрозория. Назначение раздела показать неоднозначность ошибки как явления:
— Ошибки не настолько многочисленны если их классифицировать, и поддаются потоковой обработке
— Исправление ошибки может ухудшить качество программы
— Не все ошибки являются ошибками
Но если Вы всё равно считаете что раздел нуждается в дополнении, то добро пожаловать в обсуждение.
1 Запрос в цикле
Формализуется, влияет на производительность, исправление влияет на сопровождаемость и гибкость
В большинстве случаев можно обойтись одним запросом, который сразу выдаст необходимые данные для обработки. В некоторых случаях запросы в цикле применяются осознанно, по различным причинам. Иногда, несколько запросов в цикле могут выполняться быстрее чем один большой запрос, также потеря производительности может быть признана несущественностью и код перерабатывается в пользу большей читаемости и гибкости. Это довольно скользкая дорожка, поэтому очевидно опасные решения должны быть хорошо обоснованы.
2 Неявный запрос
Неявные запросы в том числе в циклах, происходят всякий раз:
— при обращении к свойствам ссылки через точку
— при использовании методов «НайтиПо»
Сами по себе неявные запросы, позволяют сократить объем кода и повысить его читаемость. Именно ради этого разработчики языка 1С и задумывали подобные, небезопасные инструменты. Если данные методы сознательно используются, то за ними необходимо наблюдение – они могут стать узким местом.
3 Разыменование полей в запросах
Разыменование полей в запросах. Само по себе не слишком страшно если не злоупотреблять и не применять в блоке условий и соединений. Но нужно понимать, что разыменование поля приводит к созданию левого соединения с таблицей объектов к реквизитам которого идет обращение. Если разыменовывается составной тип (например, документ-регистратор), то будет создано столько соединений, сколько ссылочных типов предусмотрено в данном составном типе. В качестве обхода проблемы с созданием множества неявных соединений для составных типов можно использовать функцию «Выразить» для выбираемых полей запроса.
4 Неверное употребление функций в запросах
Формализуется, влияет на производительность и сопровождаемость
Наиболее частные ошибки происходят с функциями «Выразить» и «ТипЗначения». Если вы используете функции не только в блоке выбора, но и в блоке соединений или условий, то фактически отключаете работу индекса по данным полям. Дело в том, что для применения функции к полю записи, эту запись необходимо сначала прочитать, таким образом даже хороший запрос с соединениями по индексированным полям будет производить полное чтение записей, вместо работы с индексом. А ваш запрос вместо ускорения выполнения станет обрабатываться дольше.
Функция «Выразить» и «ТипЗначения» часто могут быть заменены оператором «Ссылка», а функция «ЕстьNull» на оператор «Есть Null»
5 Безусловная выгрузка запроса в ТЗ
Формализуется частично, влияет на производительность
Использование выгрузки в таблицу значений результата запроса, там, где достаточно обхода выборки. Накладные расходы на создание таблицы значений в сумме с последующим обходом строк в несколько раз превышают (от 2х и более) накладные расходы на получение и обход выборки из результата запроса. Причина проста — результат запроса уже сам по себе является таблицей, а выборка всего лишь инструмент по удобной работе с этой таблицей, и работая с результатом запроса при помощи выборки, вы не выполняете никаких лишних операций, выгружая же результат запроса в таблицу значений, вы фактически копируете одну таблицу в другую, со всеми накладными расходами на инициализацию, заполнение и хранение.
Формализуется частично, влияет на надёжность, быстродействие и сопровождаемость, исправление влияет на сопровождаемость
Как правило, такие вещи появляются при ошибках в выполнении кода и нежелании разбираться почему они происходят. Наиболее часто встречается попытка записи в БД. Здесь два варианта действий:
а) если ход выполнения программы не допускает прерывания работы программы исключением (например, массовая обработка данных), то постарайтесь чтобы исключение в попытке срабатывало только при физических проблемах с записью (блокировки, база недоступна и.т.д.). Проверки заполнения и корректности полей объекта должны быть выполнены до выполнения попытки. Разумеется, это потребует вынесения проверок в отдельный метод, позволяющий его использование из разных мест, но выигрыш быстродействия на записи будет очевидным.
б) если контекст выполнения программы допускает возникновение исключений (например, при интерактивной работе пользователя), то в исключительных случаях нужно позволить ошибке произойти. Конечно, исключение приведет к остановке выполнения кода, но оно также сообщит важную информацию пользователю о причинах ошибки. Принудительная обработка исключений в таких ситуациях имеет смысл только для записи дополнительной информации в ЖР и/или переопределения описания исключения для вывода пользователю более наглядной и понятной информации.
Главное, что нужно понимать — отсутствие исключений, не означает отсутствие ошибок, и бездумно перехватывая исключения, вы создаёте новые, трудноуловимые ошибки.
7 Оператор «Выполнить» и функция «Вычислить»
Необоснованное применение в нагруженных алгоритмах
Формализуется частично, влияет на производительность, исправление влияет на сопровождаемость и гибкость
Необходимо помнить, что подобные конструкции выполняются очень медленно и употреблять их в рабочей базе следует осмотрительно, иначе возможно многократное падение производительности. Подобные конструкции рекомендуется использовать для однократного вызова обработчиков, имя которых заранее неизвестно. Например, они часто используются при печати, где падение быстродействия не ощутимо, а гибкость кода повышается существенно.
Например данный код
Для Сч = 1 По N Цикл
Выполнить(«А = А + 1»);
Будет выполняться дольше чем:
И по мере увеличения N разница будет расти.
Выполнение произвольного кода, введенного пользователем
Формализуется частично, влияет на безопасность, исправление влияет на сопровождаемость и гибкость
Если ваш продукт не является инструментом разработчика, то категорически нельзя выполнять код, введенный пользователем. Даже если он должен ввести имя реквизита или формулу. Выполняя неизвестный код или его фрагмент, вы открываете свою базу для вредоносных инъекций.
Получение именованных реквизитов
Возвращается парень из армии в деревню. Его спрашивают:
— Как там, в армии?
— Сплошная нервотрёпка!
— Как это?
На следующий день в пять утра деревня поднимается набатом:
Народ с изб повыскакивал и бегом к колокольне, а парень с высоты кричит:
— Мы с отцом за дровами, остальные – разойтись!
Ситуация, когда при необходимости обработать небольшую часть данных, выполняется вызов всех объектов и последующий перебор. Либо применяется излишняя обработка объектов, в этом не нуждающихся. Подобные ошибки я встречал в том числе в нагруженных модулях с многократными выполнениями и большим числом итераций. Наглядный пример: есть элемент справочника, изменение реквизитов которого должно сопровождаться синхронным изменением соответствующих реквизитов в подчиненных элементах. Разработчик поступает так — он отбирает ВСЕ подчиненные элементы и без всякой проверки просто перезаписывает их с правильным значением реквизита. Правильным подходом было бы уже в запросе отфильтровать элементы, нуждающиеся в перезаписи, в крайнем случае выполнять подобную проверку перед записью. Основное правило — старайтесь минимизировать операции, особенно если это операция перезаписи существующих объектов. Во-первых, это просто ненужная операция и она может спровоцировать еще много других ненужных операций (например, регистрация к обмену якобы изменившихся элементов). Во-вторых, операция перезаписи (update) очень тяжелая, и в зависимости от условий разница с записью нового объекта может различаться в несколько раз.
9 Поиск в не индексированных коллекциях
В качестве таких коллекций чаще всего выступают массивы и таблицы значений.
Метод «найти» в коллекции с большим числом элементов нужно использовать с осторожностью, так как поиск производится полным перебором коллекции. Оптимальным вариантом для оптимизации поиска в массиве может быть использование соответствия (map) вместо массива. В этом случае накладные расходы на создание соответствия окупятся значительно более быстрым поиском нужного значения в коллекции.
Для таблицы значений, как правило, помогает индексация полей поиска вкупе с использованием метода «НайтиСтроки». Не забывайте, что индексы нужно создавать под такие сочетания полей поиска, которые вы используете.
10 Клиент-сервер.
Формализуется частично, влияет на производительность. Исправление может влиять на сопровождаемость.
Необоснованные серверные вызовы
Частые контекстные серверные вызовы, там, где можно обойтись внеконтекстным. Например, нужно получить текущий курс валют. На форме есть ссылка на валюту. Чтобы получить курс на дату достаточно выполнить внеконтекстный вызов сервера и передать валюту и дату в качестве параметров. Здесь будет произведена передача одной ссылки и одного примитивного типа на сервер и возврат другого примитивного типа. В случае контекстного вызова сервера, на сервер вытягивается вся форма, при этом все её данные дважды пройдут процедуру сериализации/десериализации при миграции на сервер и обратно.
Необоснованная передача параметров по ссылке
Если вам не нужно редактировать переданные параметры, то передавать их нужно по значению. Иначе процедура сериализации/десериализации параметров будет выполнена дважды! И если для примитивных типов это фактически бесплатно, то для ссылочных типов это довольно дорогая операция. В любом случае, нужно взять за правило, что если параметр не должен измениться, то незачем передавать его по ссылке.
11 «Китайский» метод программирования.
Не формализуется, влияет на надёжность, сопровождаемость и гибкость, исправление влияет на быстродействие
Копирование фрагментов кода с нужным алгоритмом. Это грубая и опасная ошибка. Разумеется, в некоторых случаях копирование применимо и полезно. Но случаи это специфические и применение особых методов к ним должно быть обдумано и обосновано. В иных же случаях «копипаста» не только усложняет чтение и как следствие сопровождение кода, но и может привести к неожиданным и трудноуловимым ошибкам в программе. Например, когда потребности заказчика потребуют внести изменения в исходный алгоритм. В этом случае все созданные копии продолжат использовать старую версию алгоритма. Последствия непредсказуемы, но могут быть катастрофическими. Правильное решение — использование общих формул и алгоритмов — «выделение метода». Создаётся отдельная функция (или обработка с набором методов) и уже эти методы используются в разных частях программы. Для реализации «региональных» особенностей в разных участках кода добавляются особые параметры метода или (если особенности начинают разрастаться) выделяется новый метод или добавляется еще один уровень абстракции. Примерно в таком направлении должна проходить эволюция программы.
12 Использование изменчивых данных ИБ в качестве констант
Формализуется частично, влияет на надёжность, сопровождаемость и гибкость
Написание алгоритмов, опирающихся на изменчивые значения как на константы. Такой подход может привести к самым неожиданным и печальным результатам. Например, поиск элемента справочника по прямо прописанному в коде номеру, наименованию или GUID просто перестанет работать при даже незначительном изменении наименования или замене объекта обработкой по чистке дублей. В таких случаях, обычно или добавляют константу или заводят специальный справочник/РС где хранятся необходимые ссылки. В крайнем случае — если нет возможности менять структуру данных ИБ — заводят общий метод, возвращающий нужное значение (или прописанное кодом или из хранилища значений). Когда появится возможность изменить структуру БД вы легко замените алгоритм в одном единственном общем методе.
13 Несоответствие наименования переменной хранимому значению.
Не формализуется, влияет на сопровождаемость
Причин может быть несколько:
а) исходный алгоритм поменялся, разработчик поленился переименовать переменные;
б) потребовалось записать куда-то необходимые данные — разработчик решил использовать ранее инициализированную и уже «отработавшую» переменную с принципиально другим значением.
в) разработчик поленился и завел одну или несколько переменных с ни о чем не говорящими названиями типа а1, а2 или Темп1-2, Врем1-2 и.т.д.
14 Длинные методы
Не формализуется, влияет на работоспособность, сопровождаемость и гибкость, исправление влияет на быстродействие
Наиболее заметная, но зачастую самая сложная в исправлении ошибка. Главная проблема длинного метода, что он позволяет даже хорошему программисту ошибаться:
а) ошибаться с именованием и типизацией переменных;
б) забывать или даже не знать, что происходит с переменной в дебрях кода;
в) ошибаться в разделении уровней абстракции и сваливать всё в одну плохоразличимую кучу.
Четких критериев на длину метода нет. Формальное ограничение числа строк метода может стать большой глупостью, которая будет особенно очевидна в пограничных случаях. Но общие принципы построения существуют, и руководствуясь ими можно применять различные меры к различным по природе и истории происхождения методам:
Основной принцип при доработке и модификации длинных методов заключается в повышении его наглядности, читаемости и предсказуемости поведения. Как правило, приведение к таким свойствам означает разбиение метода по функциональным блокам и по уровням абстракции. Но не нужно фанатизма, если не стоит прямой задачи на рефакторинг, то достаточно ступенчатого улучшения плохих длинных методов.
Метод «Здесь так заведено»
Сложился исторически в ходе многолетних правок и доработок. Как правило содержит «месиво» кода, и выделение отдельных алгоритмов из них в отдельные методы, может сопровождаться коренной перестройкой переносимых алгоритмов, потому что не существует ни структуры, ни общей логики такого метода. Сразу на такой метод наброситься страшно, поэтому подобного слона можно есть по частям, постепенно приводя запущенный код к состоянию, из которого уже есть простые выходы. Основная рекомендация в данных случаях — постарайтесь хотя бы немного прибраться всякий раз, когда приходится редактировать такие методы и, разумеется, не гадить там самому.
Представляет собой метод из первого примера, подвергнутый частичной оптимизации, либо его автор был человеком аккуратным, но не задумывающимся о совместной работе. Его переменные скорее всего имеют осмысленные наименования, различные операции визуально разделены на блоки и снабжены поясняющими комментариями. Обращаться с таким методом проще, но всё еще просто допустить ошибку. После вас не должно стать хуже. Если вы добавляете функциональный блок, то оформите его так, чтобы он был понятен и легко отличим от остального массива кода метода. Если вам нужно позаимствовать алгоритм одного из функциональных блоков метода, то создайте отдельный метод, реализующий нужный механизм и впредь вместо копирования кода, пользуйтесь вызовом нужного метода.
Метод «я длинный потому, что я удав»
Есть методы, длина которых обоснована и допустима. Это балансирующие на грани методы, являющиеся наиболее частыми предками методов из первого примера. Но знать об их существовании необходимо, чтобы не бросаться на них с клавиатурой наперевес, а подходить к каждому случаю индивидуально. Наиболее частые причины большой длины метода:
— средних размеров запрос и простая обработка его результата;
— инициализация большого числа переменных для выполнения сложных расчетов.
Второй вариант, может являться временным компромиссом, потому что явно указанные данные должны храниться в ИБ, а программа должна эти данные получать и использовать в расчетах.
3 Заключение
В данной статье мы дали лаконичное определение ошибки как свойства программы, и опираясь на эту понятийную базу определили методологию работы с ошибками. В рамках статьи описаны методики поиска и исправления ошибок, а во второй части приведены наиболее характерные примеры ошибок с примерами их исправления.