
Исключения
В нашем разговоре о потоке исполнения команд различными подсистемами пришло время поговорить про исключения или, скорее, исключительные ситуации. И прежде чем продолжить стоит совсем немного остановиться именно на самом определении. Что такое исключительная ситуация?
Исключительной называют такую ситуацию, которая делает исполнение дальнейшего кода абсолютно не корректным. Не таким как задумывалось, проектировалось. Переводит состояние приложения в целом или же его отдельной части (например, объекта) в состояние нарушенной целостности. Т.е. что-то экстраординарное, исключительное.
Почему же это так важно — определить терминологию? Работа с терминологией очень важна, т.к. она держит нас в рамках, а работу кода — предсказуемой для стороннего разработчика. Если не следовать терминологии можно уйти далеко от созданного проектировщиками концепта и получить множество неоднозначных ситуаций как для себя так и для других. А чтобы закрепить понимание вопроса давайте обратимся к примеру:
// Переводит строковое представление в численное
Number
ParsingException
// Переводит строковое представление в численное
Этот пример кажется немного странным: и это не просто так. Для того чтобы показать исключительность проблем, возникающих в данном коде я сделал его несколько утрированным. Для начала посмотрим на метод Parse. Почему он должен выбрасывать исключение?
- Он принимает в качестве параметра строку, а в качестве результата — некоторое число, которое является значимым типом. По этому числу мы никак не можем определить, является ли оно результатом корректных вычислений или же нет: оно просто есть. Другими словами, в интерфейсе метода отсутствует возможность сообщить о проблеме;
- С другой стороны метод, принимая строку подразумевает что её для него корректно подготовили: там нет лишних символов и строка содержит некоторое число. Если это не так, то возникает проблема предусловий к методу: тот код, который вызвал наш метод отдал ему не корректные данные.
Получается, что для данного метода ситуация получения строки с не корректными данными является исключительной: метод не может вернуть корректного значения, но и вернуть абы что он не может. А потому единственный выход для него — бросить исключение.
Второй вариант метода обладает каналом сигнализации о наличии проблем с входными данными: возвращаемое значение тут boolean и является признаком успешности выполнения метода. Сигнализировать о каких-либо проблемах при помощи механизма исключений данный метод не имеет ни малейшего повода: все виды проблем легко уместятся в возвращаемое значение false.
Общая картина
Обработка исключительных ситуаций может показаться вопросом достаточно элементарным: ведь все что нам необходимо сделать — это установить try-catch блоки и ждать соответствующего события. Однако вопрос кажется элементарным только благодаря огромной работе, проделанной командами CLR и CoreCLR чтобы унифицировать все ошибки, которые лезут в CLR со всех щелей — из самых разных источников. Чтобы иметь представление, о чем мы будем далее вести беседу, давайте взглянем на диаграмму:

устарело: нет Linux
На этой схеме мы видим, что в .NET существует по сути два мира: все, что относится к CLR и все, что находится за ней: все возможные ошибки, возникающие в Windows / Linux и прочем unsafe мире:
- Structured Exception Handling (SEH) — структурированная обработка исключений — стандарт платформы Windows для обработки исключений. Во время вызовов unsafe методов и последующем выбросе исключений происходит конвертация исключений unsafe <-> CLR в обе стороны: из unsafe в CLR и обратно, т.к. CLR может вызвать unsafe метод, а тот в свою очередь — CLR метод.
- Vectored Exception Handling (VEH) — по своей сути является корнем SEH, позволяя вставлять свои обработчики в точку выброса исключения. Используется в частности для установки
FirstChanceException. - COM+ исключения — когда источником проблемы является некоторый COM компонент, то прослойка между COM и .NET методом должна сконвертировать COM ошибку в исключение .NET
- И, наконец, обёртки для HRESULT. Введены для конвертации модели WinAPI (код ошибки — в возвращаемом значении, а возвращаемые значения — через параметры метода) в модель исключений: для .NET в отличии от операционных систем стандартом является именно исключительная ситуация
С другой стороны, поверх CLI располагаются языки программирования, каждый из которых частично или же полностью — предлагает функционал по обработке исключений конечному пользователю языка. Так, например, языки VB.NET и F# до недавнего времени обладали более богатым функционалом по части обработки исключительных ситуаций, предлагая функционал фильтров, которых не существовало в языке C#.
Коды возврата vs. исключение
Стоит отдельно отметить, что можно вообще обойтись без исключений. Не выбрасывать их никогда, всегда работая на кодах возврата. Эта идея может показаться странной: мы ведь все привыкли к тому, что исключения есть, их много и их выбрасывают практически все классы нашей необъятной платформы. Однако, если не отворачиваться, а порассуждать, то можно прийти к выводам, что работа без исключений, возможно даже, более удобная и безопасная чем с ними.
Сами посудите: в случае исключения код будет разорван, прерван и эту поломку сможет перехватить только некий другой код выше во стеку. Причём влетая туда, в этот catch блок вы можете получить приложение, находящееся в не консистентном состоянии (например, если выброшено было не предусмотренное исключение, а блок перехватывал по типу базового класса). Плюс, если логика написана с использованием кодов ошибки, которые оформлены в виде enum, пользователь метода видит и возможность самой ошибки, а также может сразу понять, какие ошибки возможны (перейдя на определение enum).
Если за основу взята модель с исключительными ситуациями, код возврата необходимо внедрять тогда, кода факт ошибки является нормой поведения. Например, в алгоритме парсинга текста ошибки в тексте являются нормой поведения, тогда как в алгоритме работы с разобранной строкой получение от парсера ошибки может являться критичным или, другими словами, чем-то исключительным.
Блоки Try-Catch-Finally коротко
Это вовсе не означает, что перехватывать исключения идеологически плохо: я всего лишь хочу сказать о необходимости перехватывать то и только то, что вы ожидаете от конкретного участка кода и ничего больше. Например, вы не можете ожидать все типы исключений, которые наследуется от ArgumentException или же получение NullReferenceException поскольку это означает что проблема чаще всего не в вызываемом коде, а в вашем. Зато вполне корректно ожидать, что желаемый файл открыть вы не сможете. Даже если на 200% уверены, что сможете, не забудьте сделать проверку.
Третий блок — finally — также не должен нуждаться в представлении. Этот блок срабатывает для всех случаев работы блоков try-catch. Кроме некоторых достаточно редких особых ситуаций, этот блок отрабатывает всегда. Для чего введена такая гарантия исполнения? Для зачистки тех ресурсов и тех групп объектов, которые были выделены или же захвачены в блоке try и при этом являются зоной его ответственности.
Этот блок очень часто используется без блока catch, когда нам не важно, какая ошибка уронила алгоритм, но важно очистить все выделенные для этого конкретно алгоритма ресурсы. Простой пример: для алгоритма копирования файла необходимо: два открытых файла и участок памяти под кэш-буфер копирования. Память мы выделить смогли, один файл открыть смогли, а вот со вторым возникли какие-то проблемы. Чтобы запечатать все в одну «транзакцию», мы помещаем все три операции в единый try блок (как вариант реализации), с очисткой ресурсов — в finally. Пример может показаться упрощённым, но тут главное — показать суть.
Чего не хватает в языке программирования C#, так это блока fault, суть которого — срабатывать всегда, когда произошла любая ошибка. Т.е. тот же finally, только на стероидах. Если бы такое было, мы бы смогли, как классический пример делать единую точку входа в логирование исключительных ситуаций:
_loggerWarnexception
Также, о чем хотелось бы упомянуть во вводной части — это фильтры исключительных ситуаций. Для платформы .NET это новшеством не является, однако является таковым для разработчиков на языке программирования C#: фильтрация исключительных ситуаций появилась у нас только в шестой версии языка. Фильтры призваны нормализовать ситуацию, когда есть единый тип исключения, который объединяет в себе несколько видов ошибок. И в то время как мы хотим отрабатывать на конкретный сценарий, вынуждены перехватывать всю группу и фильтровать её — уже после перехвата. Я, конечно же, имею в виду код следующего вида:
exceptionErrorCode
ErrorCodeMissingModifier
ErrorCodeMissingBracket
Так вот теперь мы можем переписать этот код нормально:
exceptionErrorCode ErrorCodeMissingModifier
exceptionErrorCode ErrorCodeMissingBracket
И вопрос улучшения тут вовсе не в отсутствии конструкции switch. Новая конструкция как по мне лучше по нескольким пунктам:
- фильтруя по when мы перехватываем ровно то что хотим поймать и не более того. Это правильно идеологически;
- в новом виде код стал более читаем. Просматривая взглядом, мозг более легко находит определения ошибок, т.к. изначально он их ищет не в
switch-case, а вcatch; - и менее явное, но также очень важное: предварительное сравнение идёт ДО входа в catch блок. А это значит, что работа такой конструкции для случая промаха мимо всех условий будет идти намного быстрее чем
switchс перевыбросом исключения.
Особенностью исполнения кода является то, что код фильтрации происходит до того как произойдёт развёртка стека. Это можно наблюдать в ситуациях, когда между местом выброса исключения и местом проверки на фильтрацию нет никаких других вызовов кроме обычных:
Main
Foo
Checkex
Foo
Boo
Boo
Exception
Check
exMessage

Как видно на изображении трассировка стека содержит не только первый вызов Main как место отлова исключительной ситуации, но и весь стек до точки выброса исключения плюс повторный вход в Main через некоторый неуправляемый код. Можно предположить, что этот код и есть код выброса исключений, который просто находится в стадии фильтрации и выбора конечного обработчика. Однако стоит отметить что не все вызовы позволяют работать без раскрутки стека. На мой скромный взгляд, внешняя унифицированность платформы порождает излишнее к ней доверие. Например, вызов методов между доменами с точки зрения кода выглядит абсолютно прозрачно. Тем не менее, работа вызовов методов происходит совсем по другим законам. О них мы и поговорим в следующей части.
Сериализация
Давайте начнём несколько издалека и посмотрим на результаты работы следующего кода (я добавил проброс вызова через границу между доменами приложения):
return ex.Message == "1";
}
public class ProxyRunner : MarshalByRefObject
{
private void MethodInsideAppDomain()
{
throw new Exception("1");
}
public static void Go()
{
var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory
});
var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName);
proxy.MethodInsideAppDomain();
}
}
}
«>
ProxyRunnerGo
Checkex
AppDomainCurrentDomainFriendlyName // -> TestApp.exe
exMessage
Exception
AppDomainCreateDomain AppDomainSetup
AppDomainCurrentDomainBaseDirectory
ProxyRunner domCreateInstanceAndUnwrapAssemblyFullName FullName
proxyMethodInsideAppDomain
Если обратить внимание на размотку стека, то станет ясно, что в данном случае она происходит ещё до того, как мы попадаем в фильтр. Взглянем на скриншоты. Первый взят до того, как генерируется исключение:

А второй — после:

Изучим трассировку вызовов до и после попадания в фильтр исключений. Что же здесь происходит? Здесь мы видим, что разработчики платформы сделали некоторую с первого взгляда защиту дочернего домена. Трассировка обрезана по крайний метод в цепочке вызовов, после которого идёт переход в другой домен. Но на самом деле, как по мне так это выглядит несколько странно. Чтобы понять, почему так происходит, вспомним основное правило для типов, организующих взаимодействие между доменами. Эти типы должны наследовать MarshalByRefObject плюс — быть сериализуемыми. Однако, как бы ни был строг C#, типы исключений могут быть какими угодно. А что это значит? Это значит, что могут быть ситуации, когда исключительная ситуация внутри дочернего домена может привести к её перехвату в родительском домене. И если у объекта данных исключительной ситуации есть какие-либо опасные методы с точки зрения безопасности, они могут быть вызваны в родительском домене. Чтобы такого избежать, исключение сериализуется, проходит через границу доменов приложений и возникает вновь — с новым стеком. Давайте проверим эту стройную теорию:
return ex.Message == "1";
}
public class ProxyRunner : MarshalByRefObject
{
private void MethodInsideAppDomain()
{
var x = new Cast {obj = new Program()};
throw x.Exception;
}
public static void Go()
{
var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory
});
var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName);
proxy.MethodInsideAppDomain();
}
}»>
Main
ProxyRunnerGo
ConsoleReadKey
exWrappedException Program
Check
AppDomainCurrentDomainFriendlyName // -> TestApp.exe
exMessage
Cast Program
xException
AppDomainCreateDomain AppDomainSetup
AppDomainCurrentDomainBaseDirectory
ProxyRunnerdomCreateInstanceAndUnwrapAssemblyFullName FullName
proxyMethodInsideAppDomain
В данном примере, для того чтобы выбросить исключение любого типа из C# кода (я не хочу никого мучить вставками на MSIL) был проделан трюк с приведением типа к не сопоставимому: чтобы мы бросили исключение любого типа, а транслятор C# думал бы, что мы используем тип Exception. Мы создаём экземпляр типа Program — гарантированно не сериализуемого и бросаем исключение с ним в виде полезной нагрузки. Хорошие новости заключаются в том, что вы получите обёртку над не-Exception исключениями RuntimeWrappedException, который внутри себя сохранит экземпляр нашего объекта типа Program и в C# перехватить такое исключение мы сможем. Однако есть и плохая новость, которая подтверждает наше предположение: вызов proxy.MethodInsideAppDomain(); приведёт к исключению SerializationException:

Т.е. проброс между доменами такого исключения не возможен, т.к. его нет возможности сериализовать. А это в свою очередь значит, что оборачивание вызовов методов, находящихся в других доменах фильтрами исключений все равно приведёт к развёртке стека несмотря на то что при FullTrust настройках дочернего домена сериализация казалось бы не нужна.
Стоит дополнительно обратить внимание на причину, по которой сериализация между доменами так необходима. В нашем синтетическом примере мы создаём дочерний домен, который не имеет никаких настроек. А это значит, что он работает в FullTrust. Т.е. CLR полностью доверяет его содержимому как себе и никаких дополнительных проверок делать не будет. Но как только вы выставите хоть одну настройку безопасности, полная доверенность пропадёт и CLR начнёт контролировать все что происходит внутри этого дочернего домена. Так вот когда домен полностью доверенный, сериализация по идее не нужна. Нам нет необходимости как-то защищаться, согласитесь. Но сериализация создана не только для защиты. Каждый домен грузит в себя все необходимые сборки по второму разу, создавая их копии. Тем самым создавая копии всех типов и всех таблиц виртуальных методов. Передавая объект по ссылке из домена в домен, вы получите, конечно, тот же объект. Но у него будут чужие таблицы виртуальных методов и как результат — этот объект не сможет быть приведён к другому типу. Другими словами, если вы создали экземпляр типа
Boo, то получив его в другом домене приведение типа(Boo)booне сработает. А сериализация и десериализация решает проблему: объект будет существовать одновременно в двух доменах. Там где он был создан — со всеми своими данными и в доменах использования — в виде прокси-объекта, обеспечивающего вызов методов оригинального объекта.
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Обработка ошибок
Подход, при котором мы возвращаем либо false, либо данные, подразумевает, что у нас есть два состояния. Но это не всегда так.
Например, если мы возвращаем ошибку файловой системы, то обычно хотим знать, что за ошибка произошла. Например, в файловых системах в UNIXO количество ошибок превышает 100:
/* Operation not permitted */
/* No such file or directory */
/* No such process */
/* Interrupted system call */
/* I/O error */
/* No such device or address */
/* Arg list too long */
/* Exec format error */
/* Bad file number */
/* No child processes */
Самостоятельно пытаться догадаться, что произошло, — не лучшая идея. Так мы не сможем далеко продвинуться при работе с программой.
В этом случае появляется вопрос, как действовать — как возвращать результат. Один из самых простых вариантов — это коды возврата.
Коды возврата
Возврат ошибки связан с тем, что мы возвращаем не просто false или undefined. Мы возвращаем некоторое число. Оно говорит о том, какая ошибка произошла. Это работает так:
// Вызываем команду, например, удаление директории, и получаем результат
// Проверяем, является ли результат частью списка ошибок. Перечисляем возможные варианты
/* errors list */
В итоге мы узнаем, входит ли результат в список ошибок. Если всё хорошо, то мы продолжаем работать и используем тот же результат.
Проблема в том, что результат иногда может быть числовым. Тогда нам нужно выбрать лист ошибок, чтобы нормальное значение не попадало в него.
В итоге нам постоянно придется делать такие проверки — проверять большое количество возможных возвратов. Такой процесс нужно упрощать.
Возврат результата в СИ
В Си принят следующий подход возврата результата:
# Открываем файл на чтение
# Делаем проверку
// Value of errno is: 2
# Если указатель равен нулю, то пишем, что произошла ошибка
"Value of errno: %d
Ошибка записывается в глобальную переменную, которая называется errno. И там, например, будет цифра 2, которая означает, что всё плохо.
Здесь мы убеждаемся, что у нас нет адекватного результата. Но по сути идет глобальное изменение среды. А глобальные переменные — это не вариант, особенно, в современных языках.
Возврат результата в Golang
Рассмотрим более продвинутый способ. Этот тот же способ, что и в СИ, но улучшенный. Он называется Golang Style.
Golang — это современный язык, который избавляет от глобальных переменных.
// Возращается два значения: dat — данные, err — ошибка
// Проверяем, равна ли ошибка nil
Если ошибка не равна nil, то ошибки нет, и всё хорошо. Если равна nil, то мы обрабатываем ее.
Это фактически такой же подход как в CИ. Только здесь нет глобальной переменной, которая постоянно меняется. Каждая функция возвращает свой результат выполнения. Так мы двигаемся вниз по вызовам и можем строить программу.
Возврат результата в JavaScript
В JavaScript можно использовать такой же подход. Это рабочая схема, которая основана на Destructuring. У нее есть определенные недостатки, которые мы разберем в следующем уроке.
// Делаем чтение, описываем данные и ошибку
// do something with data
// handle error
Если ошибка равна null, то делаем все что хотим, если нет, то обрабатываем ошибку.
Инструменты автоматизации и мониторинга удобны тем, что разработчик может взять готовые скрипты, при необходимости адаптировать и использовать в своём проекте. Можно заметить, что в некоторых скриптах используются коды завершения (exit codes), а в других нет. О коде завершения легко забыть, но это очень полезный инструмент. Особенно важно использовать его в скриптах командной строки.
Что такое коды завершения
В Linux и других Unix-подобных операционных системах программы во время завершения могут передавать значение родительскому процессу. Это значение называется кодом завершения или состоянием завершения. В POSIX по соглашению действует стандарт: программа передаёт 0 при успешном исполнении и 1 или большее число при неудачном исполнении.
Почему это важно? Если смотреть на коды завершения в контексте скриптов для командной строки, ответ очевиден. Любой полезный Bash-скрипт неизбежно будет использоваться в других скриптах или его обернут в однострочник Bash. Это особенно актуально при использовании инструментов автоматизации типа SaltStack или инструментов мониторинга типа Nagios. Эти программы исполняют скрипт и проверяют статус завершения, чтобы определить, было ли исполнение успешным.
Кроме того, даже если вы не определяете коды завершения, они всё равно есть в ваших скриптах. Но без корректного определения кодов выхода можно столкнуться с проблемами: ложными сообщениями об успешном исполнении, которые могут повлиять на работу скрипта.
Что происходит, когда коды завершения не определены
В Linux любой код, запущенный в командной строке, имеет код завершения. Если код завершения не определён, Bash-скрипты используют код выхода последней запущенной команды. Чтобы лучше понять суть, обратите внимание на пример.
/root/test
created file
$ ./tmp.sh
touch: cannot touch '/root/test': Permission denied
created file
$ echo $?
0
/root/test
$ ./tmp.sh
touch: cannot touch '/root/test': Permission denied
$ echo $?
1
Поскольку touch в данном случае — последняя запущенная команда, и она не выполнилась, получаем код возврата 1.
Как использовать коды завершения в Bash-скриптах
Проверяем коды завершения
Выше мы пользовались специальной переменной $?, чтобы получить код завершения скрипта. Также с помощью этой переменной можно проверить, выполнилась ли команда touch успешно.
/root/test 2> /dev/null
0
"Successfully created file"
"Could not create file" &2
После рефакторинга скрипта получаем такое поведение:
- Если команда
touchвыполняется с кодом0, скрипт с помощьюechoсообщает об успешно созданном файле. - Если команда
touchвыполняется с другим кодом, скрипт сообщает, что не смог создать файл.
$ ./tmp.sh
Could not create file
Создаём собственный код завершения
Наш скрипт уже сообщает об ошибке, если команда touch выполняется с ошибкой. Но в случае успешного выполнения команды мы всё также получаем код 0.
$ ./tmp.sh
Could not create file
$ echo $?
0
Поскольку скрипт завершился с ошибкой, было бы не очень хорошей идеей передавать код успешного завершения в другую программу, которая использует этот скрипт. Чтобы добавить собственный код завершения, можно воспользоваться командой exit.
/root/test 2> /dev/null
0
"Successfully created file"
0
"Could not create file" &2
1
$ ./tmp.sh
Could not create file
$ echo $?
1
Как использовать коды завершения в командной строке
Скрипт уже умеет сообщать пользователям и программам об успешном или неуспешном выполнении. Теперь его можно использовать с другими инструментами администрирования или однострочниками командной строки.
$ ./tmp.sh && echo "bam" || (sudo ./tmp.sh && echo "bam" || echo "fail")
Could not create file
Successfully created file
bam
Скрипт использует коды завершения, чтобы понять, была ли команда успешно выполнена. Если коды завершения используются некорректно, пользователь скрипта может получить неожиданные результаты при неудачном выполнении команды.
Дополнительные коды завершения
Команда exit принимает числа от 0 до 255. В большинстве случаев можно обойтись кодами 0 и 1. Однако есть зарезервированные коды, которые обозначают конкретные ошибки. Список зарезервированных кодов можно посмотреть в документации.
Адаптированный перевод статьи Understanding Exit Codes and how to use them in bash scripts by Benjamin Cane. Мнение администрации Хекслета может не совпадать с мнением автора оригинальной публикации.
Программисты каждый день пользуются сторонними библиотеками в своих программах, например, http-клиентами или парсерами. Помимо выполнения основных функций, все эти библиотеки как-то обрабатывают возникающие ошибки. Причем чем больше в библиотеке побочных эффектов — сетевое взаимодействие, работа с файлами — тем больше внутри кода, отвечающего за ошибки, и тем он сложнее.
В этой статье разберем принципы, по которым строится обработка ошибок внутри библиотек. Это поможет отличать хорошие библиотеки от плохих. Вы сможете лучше строить взаимодействие с ними и даже проектировать свои собственные библиотеки.
Прежде чем начать, давайте разберемся с терминологией. В отличие от программы, библиотека не может использоваться напрямую, например, в терминале. Любая библиотека — это код на конкретном языке, который вызывается другим кодом на этом же языке. Говорят, что у библиотеки есть клиент. Клиент — тот, кто использует библиотеку:
// http-клиент в js, эту библиотеку мы будем использовать в качестве примера
// С точки зрения axios, этот файл содержит клиентский код
// То есть код, который использует axios.
// Вызов библиотеки идет в клиентском коде
В свою очередь, находящийся внутри библиотеки код называется библиотечным кодом. Это разделение довольно важно, так как у каждой из этих частей своя зона ответственности.
Сами библиотеки часто реализованы как функция, набор функций, класс, или, опять же, набор классов. Обработка ошибок в этом случае различаться не будет, поэтому для простоты все примеры ниже будут построены на функциях.
Про ошибки
Что вообще считать ошибкой, а что нет? Представьте функцию, которая ищет символ внутри строки и не находит его. Является ли это ошибкой?
// Эта функция ищет символ в строке и возвращает его индекс
// Данный вызов ничего не найдет
Такое поведение нормально для данной функции. Если значения нет, все нормально, функция все равно выполнила свою задачу и вернула что-то осмысленное.
А что насчет http запроса как в примере выше? Как вести себя функции axios.get, которая не смогла загрузить указанную страницу? С точки зрения функции такая ситуация не является нормальной. Если функция не может выполнить свое основное предназначение, это ошибка. Именно об этих ошибках и пойдет речь. Ниже конкретные примеры того, как делать стоит и как не стоит при использовании библиотек и их проектировании.
Завершение процесса
Во всех языках программирования есть возможность досрочно остановить процесс операционной системы, в котором выполняется код. Обычно это делается с помощью функции, имеющие в названии слово exit. Вызов этой функции останавливает программу целиком.
/* что-то не получилось */
Есть ровно одна причина, по которой такой код недопустим ни в одной библиотеке: то, что является фатальной ошибкой для конкретной библиотеки, не является такой же ошибкой для всей программы. В самом худшем случае программа предупредит пользователя о неудачной попытке загрузить сайт и попросит попробовать снова. Подобное поведение невозможно было бы реализовать в случае использования библиотеки, которая останавливает выполнение целой программы.
Проще говоря, библиотека не может решать за программу, когда ей завершаться. Это не ее зона ответственности. Задача библиотеки — оповестить клиентский код об ошибке, а дальше уже не ее забота. Оповещать можно с помощью исключений:
// Делаем что-нибудь полезное с response
// Для отладки хорошо бы вывести полную информацию
// exit нужно делать на уровне программы,
// так как важно установить правильный код возврата (отличный от 0)
// только так снаружи можно будет понять что была ошибка
Вопрос на самоконтроль. Можно ли написать тесты на библиотеку, которая выполняет остановку процесса?
Имитация успеха
Иногда разработчик пытается скрыть от клиентского кода любые или почти любые ошибки. Код в таком случае перехватывает все возможные ошибки (исключения) и всегда возвращает какой-то результат. Ниже гипотетический пример с функцией axios.get. Как бы она выглядела в этом случае:
// Очень упрощенный код внутри axios.get
// Тут на самом деле сложный асинхронный код, выполняющий http запрос
// Опустим его и посмотрим на то место где возникает ошибка
// Ниже упрощенный пример обработки ошибки
// Генеральная идея — этот код возвращает какой-то результат,
// который сложно или невозможно отличить от успешно выполненного запроса
Самая главная проблема в таком решении: оно скрывает проблемы и делает невозможным или практически невозможным отлов ошибки снаружи, в клиентском коде:
// Как узнать что тут произошла ошибка и предупредить пользователя?
Правильное решение — использовать исключения.
Подавление ошибок
Этот способ очень похож на предыдущий. Код с подавлением ошибки выглядит примерно так:
// Очень упрощенный код внутри axios.get
`Something was wrong during http request:
Что здесь происходит? Разработчик выводит сообщение об ошибке в консоль и возвращает наружу, например, null. Такой код появляется тогда, когда программист еще не до конца осознал, что такое библиотека. Главный вопрос, который должен вызывать этот код: а как клиентский код узнает об ошибке? Ответ здесь — никак. Подобную библиотеку невозможно использовать правильно. Представьте, если бы так себя вел axios.get:
// Во время ошибки идет вывод в консоль
// А если консоли вообще нет?
// Даже если есть, как обработать ошибку?
Иногда ситуация еще хуже. Внутри библиотеки используется код, который порождает исключения, что правильно, а программист их перехватывает и подавляет.
// Клиент этой функции (библиотеки) никогда не узнает о том, что произошла ошибка
Правильное решение — порождать исключения и не подавлять исключения.
Коды возврата
Само по себе это не является ошибкой, но во многих ситуациях коды возврата нежелательны. О том, почему исключения предпочтительнее в большинстве ошибочных ситуаций, можно почитать в шикарной статье на Хабре.
Вопрос на самоконтроль: как должна себя вести функция валидации в случае нахождения ошибок: выкидывать исключение или возвращать ошибки, например, как массив?
Исключения
Как правило, это самый адекватный способ работы с ошибками в большинстве языков. Однако есть другие языки с совершенно другими схемами работы. Если ошибка фатальная, то она либо уже является исключением, либо исключение нужно выбросить:
/* чем больше тут полезной информации, тем лучше */
Методы обработки ошибок
1. Не обрабатывать.
2. Коды возврата. Основная идея — в случае ошибки возвращать специальное значение, которое не может быть корректным. Например, если в методе есть операция деления, то придется проверять делитель на равенство нулю. Также проверим корректность аргументов a и b:
Double f(Double a, Double b) {
((a == ) || (b == )) {
;
}
(Math.abs(b) < ) {
;
} {
a / b;
}
}
При вызове метода необходимо проверить возвращаемое значение:
Double d = f(a, b);
(d != ) {
} {
}
Минусом такого подхода является необходимость проверки возвращаемого значения каждый раз при вызове метода. Кроме того, не всегда возможно определить тип ошибки.
3.Использовать флаг ошибки: при возникновении ошибки устанавливать флаг в соответствующее значение:
;
Double f(Double a, Double b) {
((a == ) || (b == )) {
= ;
;
}
(Math.abs(b) < ) {
= ;
b;
} {
a / b;
}
}
= ;
Double d = f(a, b);
() {
} {
}
Минусы такого подхода аналогичны минусам использования кодов возврата.
4.Можно вызвать метод обработки ошибки и возвращать то, что вернет этот метод.
Double f(Double a, Double b) {
((a == ) || (b == )) {
nullPointer();
}
(Math.abs(b) < ) {
divisionByZero();
} {
a / b;
}
}
Но в таком случае не всегда возможно проверить корректность результата вызова основного метода.
5.В случае ошибки просто закрыть программу.
(Math.abs(b) < ) {
System.exit();
;
}
Это приведет к потере данных, также невозможно понять, в каком месте возникла ошибка.
Исключения
В Java возможна обработка ошибок с помощью исключений:
Double f(Double a, Double b) {
((a == ) || (b == )) {
IllegalArgumentException("arguments of f() are null");
}
a / b;
}
Проверять b на равенство нулю уже нет необходимости, так как при делении на ноль метод бросит непроверяемое исключение ArithmeticException.
- разделить обработку ошибок и сам алгоритм;
- не загромождать код проверками возвращаемых значений;
- обрабатывать ошибки на верхних уровнях, если на текущем уровне не хватает данных для обработки. Например, при написании универсального метода чтения из файла невозможно заранее предусмотреть реакцию на ошибку, так как эта реакция зависит от использующей метод программы;
- классифицировать типы ошибок, обрабатывать похожие исключения одинаково, сопоставлять специфичным исключениям определенные обработчики.
Каждый раз, когда при выполнении программы происходит ошибка, создается объект-исключение, содержащий информацию об ошибке, включая её тип и состояние программы на момент возникновения ошибки.
После создания исключения среда выполнения пытается найти в стеке вызовов метод, который содержит код, обрабатывающий это исключение. Поиск начинается с метода, в котором произошла ошибка, и проходит через стек в обратном порядке вызова методов. Если не было найдено ни одного подходящего обработчика, выполнение программы завершается.
Таким образом, механизм обработки исключений содержит следующие операции:
- Создание объекта-исключения.
- Заполнение stack trace’а этого исключения.
- Stack unwinding (раскрутка стека) в поисках нужного обработчика.
Классификация исключений
Класс Java Throwable описывает все, что может быть брошено как исключение. Наследеники Throwable — Exception и Error — основные типы исключений. Также RuntimeException, унаследованный от Exception, является существенным классом.
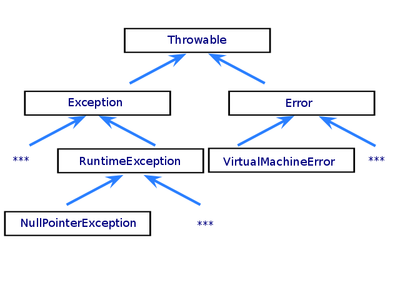
Иерархия стандартных исключений
Наследники класса Exception (кроме наслеников RuntimeException) являются проверяемыми исключениями(checked exception). Как правило, это ошибки, возникшие по вине внешних обстоятельств или пользователя приложения – неправильно указали имя файла, например. Эти исключения должны обрабатываться в ходе работы программы, поэтому компилятор проверяет наличие обработчика или явного описания тех типов исключений, которые могут быть сгенерированы некоторым методом.
Все исключения, кроме классов Error и RuntimeException и их наследников, являются проверяемыми.
Класс Error и его подклассы предназначены для системных ошибок. Свои собственные классы-наследники для Error писать (за очень редкими исключениями) не нужно. Как правило, это действительно фатальные ошибки, пытаться обработать которые довольно бессмысленно (например OutOfMemoryError).
Эти исключения обычно возникают в результате ошибок программирования, такие как ошибки разработчика или неверное использование интерфейса приложения. Например, в случае выхода за границы массива метод бросит OutOfBoundsException. Такие ошибки могут быть в любом месте программы, поэтому компилятор не требует указывать runtime исключения в объявлении метода. Теоретически приложение может поймать это исключение, но разумнее исправить ошибку.
Обработка исключений
Чтобы сгенерировать исключение используется ключевое слово throw. Как и любой объект в Java, исключения создаются с помощью new.
(t == ) {
NullPointerException("t = null");
}
Есть два стандартных конструктора для всех исключений: первый — конструктор по умолчанию, второй принимает строковый аргумент, поэтому можно поместить подходящую информацию в исключение.
Возможна ситуация, когда одно исключение становится причиной другого. Для этого существует механизм exception chaining. Практически у каждого класса исключения есть конструктор, принимающий в качестве параметра Throwable – причину исключительной ситуации. Если же такого конструктора нет, то у Throwable есть метод initCause(Throwable), который можно вызвать один раз, и передать ему исключение-причину.
Как и было сказано раньше, определение метода должно содержать список всех проверяемых исключений, которые метод может бросить. Также можно написать более общий класс, среди наследников которого есть эти исключения.
f() InterruptedException, IOException {
Код, который может бросить исключения оборачивается в try-блок, после которого идут блоки catch и finally (Один из них может быть опущен).
{
// Код, который может сгенерировать исключение
}
Сразу после блока проверки следуют обработчики исключений, которые объявляются ключевым словом catch.
{
// Код, который может сгенерировать исключение
} (Type1 id1) {
// Обработка исключения Type1
} (Type2 id2) {
// Обработка исключения Type2
}
Сatch-блоки обрабатывают исключения, указанные в качестве аргумента. Тип аргумента должен быть классом, унаследованного от Throwable, или самим Throwable. Блок catch выполняется, если тип брошенного исключения является наследником типа аргумента и если это исключение не было обработано предыдущими блоками.
Код из блока finally выполнится в любом случае: при нормальном выходе из try, после обработки исключения или при выходе по команде return.
NB: Если JVM выйдет во время выполнения кода из try или catch, то finally-блок может не выполниться. Также, например, если поток выполняющий try или catch код остановлен, то блок finally может не выполниться, даже если приложение продолжает работать.
Блок finally удобен для закрытия файлов и освобождения любых других ресурсов. Код в блоке finally должен быть максимально простым. Если внутри блока finally будет брошено какое-либо исключение или просто встретится оператор return, брошенное в блоке try исключение (если таковое было брошено) будет забыто.
java.io.IOException;
ExceptionTest {
public static void main(String[] args) {
{
{
Exception();
} {
IOException();
}
} (IOException ex) {
System..println(ex.getMessage());
} (Exception ex) {
System..println(ex.getMessage());
}
}
}
После того, как было брошено первое исключение — new Exception("a") — будет выполнен блок finally, в котором будет брошено исключение new IOException("b"), именно оно будет поймано и обработано. Результатом его выполнения будет вывод в консоль b. Исходное исключение теряется.
Обработка исключений, вызвавших завершение потока
При использовании нескольких потоков бывают ситуации, когда поток завершается из-за исключения. Для того, чтобы определить с каким именно, начиная с версии Java 5 существует интерфейс Thread.UncaughtExceptionHandler. Его реализацию можно установить нужному потоку с помощью метода setUncaughtExceptionHandler. Можно также установить обработчик по умолчанию с помощью статического метода Thread.setDefaultUncaughtExceptionHandler.
Интерфейс Thread.UncaughtExceptionHandler имеет единственный метод uncaughtException(Thread t, Throwable e), в который передается экземпляр потока, завершившегося исключением, и экземпляр самого исключения. Когда поток завершается из-за непойманного исключения, JVM запрашивает у потока UncaughtExceptionHandler, используя метод Thread.getUncaughtExceptionHandler(), и вызвает метод обработчика – uncaughtException(Thread t, Throwable e). Все исключения, брошенные этим методом, игнорируются JVM.
Информация об исключениях
-
getMessage(). Этот метод возвращает строку, которая была первым параметром при создании исключения; -
getCause()возвращает исключение, которое стало причиной текущего исключения; -
printStackTrace()печатает stack trace, который содержит информацию, с помощью которой можно определить причину исключения и место, где оно было брошено.
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
Все методы выводятся в обратном порядке вызовов. В примере исключение IllegalStateException было брошено в методе getBookIds, который был вызван в main. «Caused by» означает, что исключение NullPointerException является причиной IllegalStateException.
Разработка исключений
Чтобы определить собственное проверяемое исключение, необходимо создать наследника класса java.lang.Exception. Желательно, чтобы у исключения был конструкор, которому можно передать сообщение:
FooException Exception {
FooException() {
();
}
FooException(String message) {
(message);
}
FooException(String message, Throwable cause) {
(message, cause);
}
FooException(Throwable cause) {
(cause);
}
}
Исключения в Java7
- обработка нескольких типов исключений в одном
catch-блоке:
В таких случаях параметры неявно являются final, поэтому нельзя присвоить им другое значение в блоке catch.
Байт-код, сгенерированный компиляцией такого catch-блока будет короче, чем код нескольких catch-блоков.
-
Tryс ресурсами позволяет прямо вtry-блоке объявлять необходимые ресурсы, которые по завершению блока будут корректно закрыты (с помощью методаclose()). Любой объект реализующийjava.lang.AutoCloseableможет быть использован как ресурс.
String readFirstLineFromFile(String path) IOException {
(BufferedReader br =
BufferedReader( FileReader(path))) {
br.readLine();
}
}
В приведенном примере в качестве ресурса использутся объект класса BufferedReader, который будет закрыт вне зависимосити от того, как выполнится try-блок.
Можно объявлять несколько ресурсов, разделяя их точкой с запятой:
public static void viewTable(Connection con) throws SQLException { String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES"; (Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(query)) { //Work with Statement and ResultSet } (SQLException e) { e.printStackTrace; } }
Во время закрытия ресурсов тоже может быть брошено исключение. В try-with-resources добавленна возможность хранения «подавленных» исключений, и брошенное try-блоком исключение имеет больший приоритет, чем исключения получившиеся во время закрытия. Получить последние можно вызовом метода getSuppressed() от исключения брошенного try-блоком.
- Перебрасывание исключений с улучшенной проверкой соответствия типов.
Компилятор Java SE 7 тщательнее анализирует перебрасываемые исключения. Рассмотрим следующий пример:
FirstException Exception { }
SecondException Exception { }
rethrowException(String exceptionName) Exception {
{
(.equals(exceptionName)) {
FirstException();
} {
SecondException();
}
} (Exception ex) {
e;
}
}
В примере try-блок может бросить либо FirstException, либо SecondException. В версиях до Java SE 7 невозможно указать эти исключения в декларации метода, потому что catch-блок перебрасывает исключение ex, тип которого — Exception.
В Java SE 7 вы можете указать, что метод rethrowException бросает только FirstException и SecondException. Компилятор определит, что исключение Exception ex могло возникнуть только в try-блоке, в котором может быть брошено FirstException или SecondException. Даже если тип параметра catch — Exception, компилятор определит, что это экземпляр либо FirstException, либо SecondException:
rethrowException(String exceptionName) FirstException, SecondException {
{
} (Exception e) {
e;
}
}
Если FirstException и SecondException не являются наследниками Exception, то необходимо указать и Exception в объявлении метода.
Примеры исключений
- любая операция может бросить
VirtualMachineError. Как правило это происходит в результате системных сбоев. -
OutOfMemoryError. Приложение может бросить это исключение, если, например, не хватает места в куче, или не хватает памяти для того, чтобы создать стек нового потока. -
IllegalArgumentExceptionиспользуется для того, чтобы избежать передачи некорректных значений аргументов. Например:
f(Object a) {
(a == ) {
IllegalArgumentException("a must not be null");
}
}
IllegalStateExceptionвозникает в результате некорректного состояния объекта. Например, использование объекта перед тем как он будет инициализирован.
Гарантии безопасности
При возникновении исключительной ситуации, состояния объектов и программы могут удовлетворять некоторым условиям, которые определяются различными типами гарантий безопасности:
- Отсутствие гарантий (no exceptional safety). Если было брошено исключение, то не гарантируется, что все ресурсы будут корректно закрыты и что объекты, методы которых бросили исключения, могут в дальнейшем использоваться. Пользователю придется пересоздавать все необходимые объекты и он не может быть уверен в том, что может переиспозовать те же самые ресурсы.
- Отсутствие утечек (no-leak guarantee). Объект, даже если какой-нибудь его метод бросает исключение, освобождает все ресурсы или предоставляет способ сделать это.
- Слабые гарантии (weak exceptional safety). Если объект бросил исключение, то он находится в корректном состоянии, и все инварианты сохранены. Рассмотрим пример:
Interval {
//invariant: left <= right
double left;
double right;
}
Если будет брошено исключение в этом классе, то тогда гарантируется, что ивариант «левая граница интервала меньше правой» сохранится, но значения left и right могли измениться.
- Сильные гарантии (strong exceptional safety). Если при выполнении операции возникает исключение, то это не должно оказать какого-либо влияния на состояние приложения. Состояние объектов должно быть таким же как и до вызовов методов.
- Гарантия отсутствия исключений (no throw guarantee). Ни при каких обстоятельствах метод не должен генерировать исключения. В Java это невозможно, например, из-за того, что
VirtualMachineErrorможет произойти в любом месте, и это никак не зависит от кода. Кроме того, эту гарантию практически невозможно обеспечить в общем случае.