
Фундаментальная теория тестирования
В тестировании нет четких определений, как в физике, математике, которые при перефразировании становятся абсолютно неверными. Поэтому важно понимать процессы и подходы. В данной статье разберем основные определения теории тестирования.

Перейдем к основным понятиям
Тестирование программного обеспечения (Software Testing) — проверка соответствия реальных и ожидаемых результатов поведения программы, проводимая на конечном наборе тестов, выбранном определённым образом.
Цель тестирования — проверка соответствия ПО предъявляемым требованиям, обеспечение уверенности в качестве ПО, поиск очевидных ошибок в программном обеспечении, которые должны быть выявлены до того, как их обнаружат пользователи программы.
Для чего проводится тестирование ПО?
- Для проверки соответствия требованиям.
- Для обнаружение проблем на более ранних этапах разработки и предотвращение повышения стоимости продукта.
- Обнаружение вариантов использования, которые не были предусмотрены при разработке. А также взгляд на продукт со стороны пользователя.
- Повышение лояльности к компании и продукту, т.к. любой обнаруженный дефект негативно влияет на доверие пользователей.
Принципы тестирования
- Принцип 1 — Тестирование демонстрирует наличие дефектов (Testing shows presence of defects).
Тестирование только снижает вероятность наличия дефектов, которые находятся в программном обеспечении, но не гарантирует их отсутствия. - Принцип 2 — Исчерпывающее тестирование невозможно (Exhaustive testing is impossible).
Полное тестирование с использованием всех входных комбинаций данных, результатов и предусловий физически невыполнимо (исключение — тривиальные случаи). - Принцип 3 — Раннее тестирование (Early testing).
Следует начинать тестирование на ранних стадиях жизненного цикла разработки ПО, чтобы найти дефекты как можно раньше. - Принцип 4 — Скопление дефектов (Defects clustering).
Большая часть дефектов находится в ограниченном количестве модулей. - Принцип 5 — Парадокс пестицида (Pesticide paradox).
Если повторять те же тестовые сценарии снова и снова, в какой-то момент этот набор тестов перестанет выявлять новые дефекты. - Принцип 6 — Тестирование зависит от контекста (Testing is context depending). Тестирование проводится по-разному в зависимости от контекста. Например, программное обеспечение, в котором критически важна безопасность, тестируется иначе, чем новостной портал.
- Принцип 7 — Заблуждение об отсутствии ошибок (Absence-of-errors fallacy). Отсутствие найденных дефектов при тестировании не всегда означает готовность продукта к релизу. Система должна быть удобна пользователю в использовании и удовлетворять его ожиданиям и потребностям.
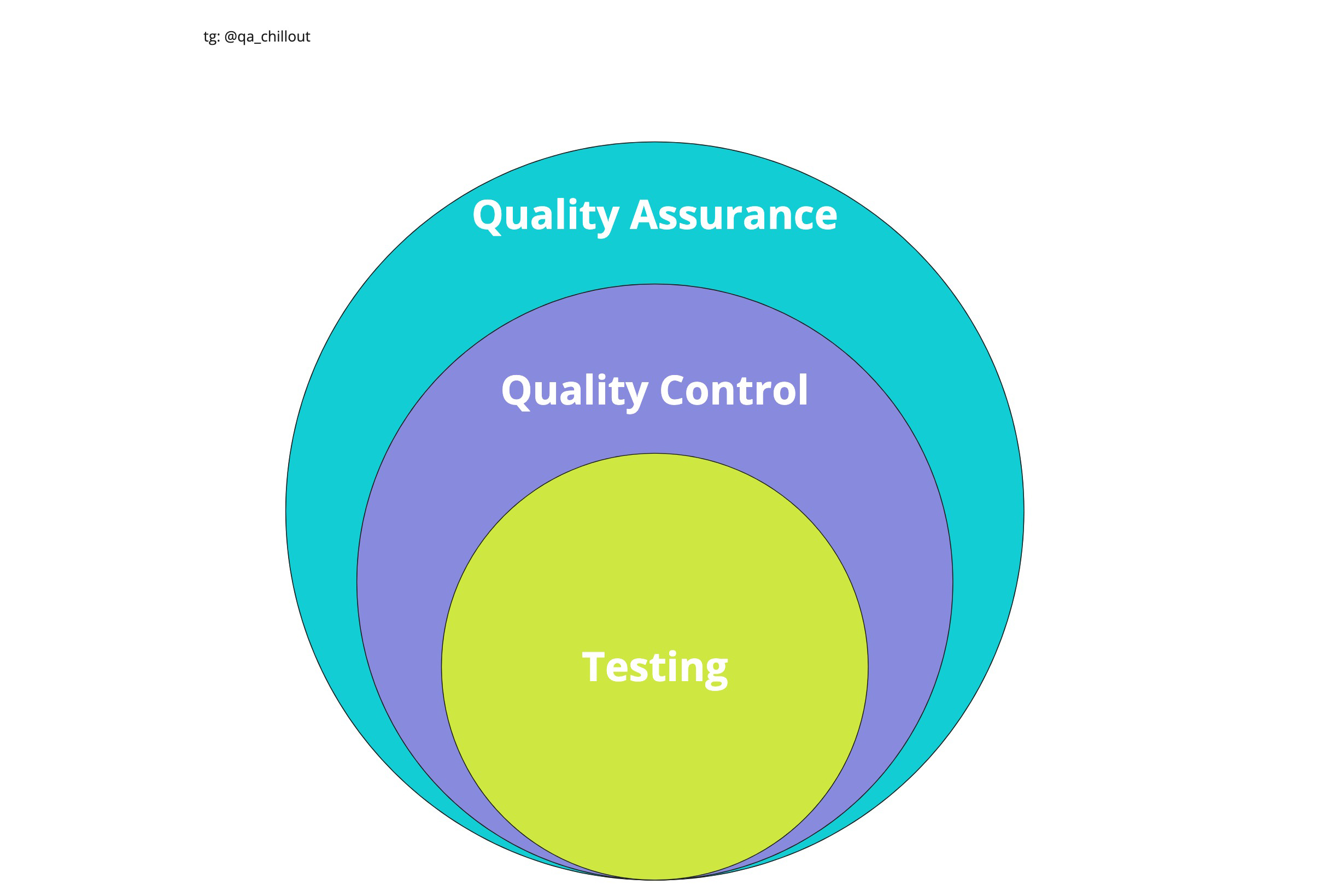
Обеспечение качества (QA — Quality Assurance) и контроль качества (QC — Quality Control) — эти термины похожи на взаимозаменяемые, но разница между обеспечением качества и контролем качества все-таки есть, хоть на практике процессы и имеют некоторую схожесть.
QC (Quality Control) — Контроль качества продукта — анализ результатов тестирования и качества новых версий выпускаемого продукта.
К задачам контроля качества относятся:
- проверка готовности ПО к релизу;
- проверка соответствия требований и качества данного проекта.
QA (Quality Assurance) — Обеспечение качества продукта — изучение возможностей по изменению и улучшению процесса разработки, улучшению коммуникаций в команде, где тестирование является только одним из аспектов обеспечения качества.
К задачам обеспечения качества относятся:
- проверка технических характеристик и требований к ПО;
- оценка рисков;
- планирование задач для улучшения качества продукции;
- подготовка документации, тестового окружения и данных;
- тестирование;
- анализ результатов тестирования, а также составление отчетов и других документов.
Верификация и валидация — два понятия тесно связаны с процессами тестирования и обеспечения качества. К сожалению, их часто путают, хотя отличия между ними достаточно существенны.
Верификация (verification) — это процесс оценки системы, чтобы понять, удовлетворяют ли результаты текущего этапа разработки условиям, которые были сформулированы в его начале.
Валидация (validation) — это определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, его требованиям к системе.
Пример: когда разрабатывали аэробус А310, то надо было сделать так, чтобы закрылки вставали в положение «торможение», когда шасси коснулись земли. Запрограммировали так, что когда шасси начинают крутиться, то закрылки ставим в положение «торможение». Но вот во время испытаний в Варшаве самолет выкатился за пределы полосы, так как была мокрая поверхность. Он проскользил, только потом был крутящий момент и они, закрылки, открылись. С точки зрения «верификации» — программа сработала, с точки зрения «валидации» — нет. Поэтому код изменили так, чтобы в момент изменения давления в шинах открывались закрылки.
Документацию, которая используется на проектах по разработке ПО, можно условно разделить на две группы:
- Проектная документация — включает в себя всё, что относится к проекту в целом.
- Продуктовая документация — часть проектной документации, выделяемая отдельно, которая относится непосредственно к разрабатываемому приложению или системе.
Этапы тестирования
- Анализ продукта
- Работа с требованиями
- Разработка стратегии тестирования и планирование процедур контроля качества
- Создание тестовой документации
- Тестирование прототипа
- Основное тестирование
- Стабилизация
- Эксплуатация
Стадии разработки ПО — этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широкого круга пользователей.
Программный продукт проходит следующие стадии:
- анализ требований к проекту;
- проектирование;
- реализация;
- тестирование продукта;
- внедрение и поддержка.
Требования
Требования — это спецификация (описание) того, что должно быть реализовано. Требования описывают то, что необходимо реализовать, без детализации технической стороны решения.
- Корректность — точное описание разрабатываемого функционала.
- Проверяемость — формулировка требований таким образом, чтобы можно было выставить однозначный вердикт, выполнено все в соответствии с требованиями или нет.
- Полнота — в требовании должна содержаться вся необходимая для реализации функциональности информация.
- Недвусмысленность — требование должно содержать однозначные формулировки.
- Непротиворечивость — требование не должно содержать внутренних противоречий и противоречий другим требованиям и документам.
- Приоритетность — у каждого требования должен быть приоритет(количественная оценка степени значимости требования). Этот атрибут позволит грамотно управлять ресурсами на проекте.
- Атомарность — требование нельзя разбить на отдельные части без потери деталей.
- Модифицируемость — в каждое требование можно внести изменение.
- Прослеживаемость — каждое требование должно иметь уникальный идентификатор, по которому на него можно сослаться.
Дефект (bug) — отклонение фактического результата от ожидаемого.
Отчёт о дефекте (bug report) — документ, который содержит отчет о любом недостатке в компоненте или системе, который потенциально может привести компонент или систему к невозможности выполнить требуемую функцию.
Атрибуты отчета о дефекте:
- Уникальный идентификатор (ID) — присваивается автоматически системой при создании баг-репорта.
- Тема (краткое описание, Summary) — кратко сформулированный смысл дефекта, отвечающий на вопросы: Что? Где? Когда(при каких условиях)?
- Подробное описание (Description) — более широкое описание дефекта (указывается опционально).
- Шаги для воспроизведения (Steps To Reproduce) — описание четкой последовательности действий, которая привела к выявлению дефекта. В шагах воспроизведения должен быть описан каждый шаг, вплоть до конкретных вводимых значений, если они играют роль в воспроизведении дефекта.
- Фактический результат (Actual result) — описывается поведение системы на момент обнаружения дефекта в ней. чаще всего, содержит краткое описание некорректного поведения(может совпадать с темой отчета о дефекте).
- Ожидаемый результат (Expected result) — описание того, как именно должна работать система в соответствии с документацией.
- Вложения (Attachments) — скриншоты, видео или лог-файлы.
- Серьёзность дефекта (важность, Severity) — характеризует влияние дефекта на работоспособность приложения.
- Приоритет дефекта (срочность, Priority) — указывает на очерёдность выполнения задачи или устранения дефекта.
- Статус (Status) — определяет текущее состояние дефекта. Статусы дефектов могут быть разными в разных баг-трекинговых системах.
- Окружение (Environment) – окружение, на котором воспроизвелся баг.
Жизненный цикл бага
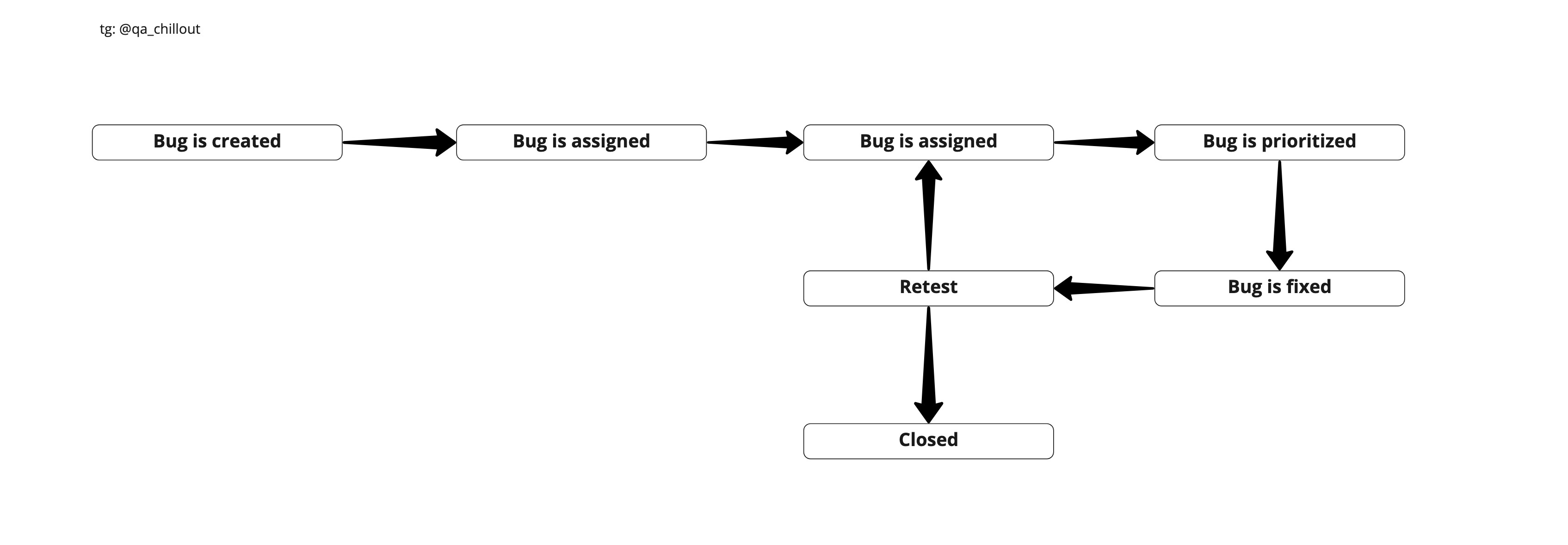
Severity vs Priority
Серьёзность (severity) показывает степень ущерба, который наносится проекту существованием дефекта. Severity выставляется тестировщиком.
Градация Серьезности дефекта (Severity):
- Критический (S2 – Critical)
критическая ошибка, неправильно работающая ключевая бизнес-логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, то есть не работает важная часть одной какой-либо функции либо не работает значительная часть, но имеется workaround (обходной путь/другие входные точки), позволяющий продолжить тестирование. - Значительный (S3 – Major)
не работает важная часть одной какой-либо функции/бизнес-логики, но при выполнении специфических условий, либо есть workaround, позволяющий продолжить ее тестирование либо не работает не очень значительная часть какой-либо функции. Также относится к дефектам с высокими visibility – обычно не сильно влияющие на функциональность дефекты дизайна, которые, однако, сразу бросаются в глаза. - Незначительный (S4 – Minor)
часто ошибки GUI, которые не влияют на функциональность, но портят юзабилити или внешний вид. Также незначительные функциональные дефекты, либо которые воспроизводятся на определенном устройстве. - Тривиальный (S5 – Trivial)
почти всегда дефекты на GUI — опечатки в тексте, несоответствие шрифта и оттенка и т.п., либо плохо воспроизводимая ошибка, не касающаяся бизнес-логики, проблема сторонних библиотек или сервисов, проблема, не оказывающая никакого влияния на общее качество продукта.
Срочность (priority) показывает, как быстро дефект должен быть устранён. Priority выставляется менеджером, тимлидом или заказчиком
Градация Приоритета дефекта (Priority):
- P1 Высокий (High)
Критическая для проекта ошибка. Должна быть исправлена как можно быстрее. - P2 Средний (Medium)
Не критичная для проекта ошибка, однако требует обязательного решения. - P3 Низкий (Low)
Наличие данной ошибки не является критичным и не требует срочного решения. Может быть исправлена, когда у команды появится время на ее устранение.
Существует шесть базовых типов задач:
- Эпик (epic) — большая задача, на решение которой команде нужно несколько спринтов.
- Требование (requirement ) — задача, содержащая в себе описание реализации той или иной фичи.
- История (story) — часть большой задачи (эпика), которую команда может решить за 1 спринт.
- Задача (task) — техническая задача, которую делает один из членов команды.
- Под-задача (sub-task) — часть истории / задачи, которая описывает минимальный объем работы члена команды.
- Баг (bug) — задача, которая описывает ошибку в системе.
Тестовые среды
- Среда разработки (Development Env) – за данную среду отвечают разработчики, в ней они пишут код, проводят отладку, исправляют ошибки
- Среда тестирования (Test Env) – среда, в которой работают тестировщики (проверяют функционал, проводят smoke и регрессионные тесты, воспроизводят.
- Интеграционная среда (Integration Env) – среда, в которой проводят тестирование взаимодействующих друг с другом модулей, систем, продуктов.
- Предпрод (Preprod Env) – среда, которая максимально приближена к продакшену. Здесь проводится заключительное тестирование функционала.
- Продакшн среда (Production Env) – среда, в которой работают пользователи.
Основные фазы тестирования
- Pre-Alpha: прототип, в котором всё ещё присутствует много ошибок и наверняка неполный функционал. Необходим для ознакомления с будущими возможностями программ.
- Alpha: является ранней версией программного продукта, тестирование которой проводится внутри фирмы-разработчика.
- Beta: практически готовый продукт, который разработан в первую очередь для тестирования конечными пользователями.
- Release Candidate (RC): возможные ошибки в каждой из фичей уже устранены и разработчики выпускают версию на которой проводится регрессионное тестирование.
Основные виды тестирования ПО
Вид тестирования — это совокупность активностей, направленных на тестирование заданных характеристик системы или её части, основанная на конкретных целях.
Тест-дизайн — это этап тестирования ПО, на котором проектируются и создаются тестовые случаи (тест-кейсы).
Автор книги «A Practitioner’s Guide to Software Test Design», Lee Copeland, выделяет следующие техники тест-дизайна:
- Тестирование на основе классов эквивалентности (equivalence partitioning) — это техника, основанная на методе чёрного ящика, при которой мы разделяем функционал (часто диапазон возможных вводимых значений) на группы эквивалентных по своему влиянию на систему значений.
- Техника анализа граничных значений (boundary value testing) — это техника проверки поведения продукта на крайних (граничных) значениях входных данных.
- Попарное тестирование (pairwise testing) — это техника формирования наборов тестовых данных из полного набора входных данных в системе, которая позволяет существенно сократить количество тест-кейсов.
- Тестирование на основе состояний и переходов (State-Transition Testing) — применяется для фиксирования требований и описания дизайна приложения.
- Таблицы принятия решений (Decision Table Testing) — техника тестирования, основанная на методе чёрного ящика, которая применяется для систем со сложной логикой.
- Доменный анализ (Domain Analysis Testing) — это техника основана на разбиении диапазона возможных значений переменной на поддиапазоны, с последующим выбором одного или нескольких значений из каждого домена для тестирования.
- Сценарий использования (Use Case Testing) — Use Case описывает сценарий взаимодействия двух и более участников (как правило — пользователя и системы).
Методы тестирования

Тестирование белого ящика — метод тестирования ПО, который предполагает, что внутренняя структура/устройство/реализация системы известны тестировщику.
Согласно ISTQB, тестирование белого ящика — это:
- тестирование, основанное на анализе внутренней структуры компонента или системы;
- тест-дизайн, основанный на технике белого ящика — процедура написания или выбора тест-кейсов на основе анализа внутреннего устройства системы или компонента.
- Почему «белый ящик»? Тестируемая программа для тестировщика — прозрачный ящик, содержимое которого он прекрасно видит.
Тестирование серого ящика — метод тестирования ПО, который предполагает комбинацию White Box и Black Box подходов. То есть, внутреннее устройство программы нам известно лишь частично.
Тестирование чёрного ящика — также известное как тестирование, основанное на спецификации или тестирование поведения — техника тестирования, основанная на работе исключительно с внешними интерфейсами тестируемой системы.
Согласно ISTQB, тестирование черного ящика — это:
- тестирование, как функциональное, так и нефункциональное, не предполагающее знания внутреннего устройства компонента или системы;
- тест-дизайн, основанный на технике черного ящика — процедура написания или выбора тест-кейсов на основе анализа функциональной или нефункциональной спецификации компонента или системы без знания ее внутреннего устройства.
Тестовая документация
Тест план (Test Plan) — это документ, который описывает весь объем работ по тестированию, начиная с описания объекта, стратегии, расписания, критериев начала и окончания тестирования, до необходимого в процессе работы оборудования, специальных знаний, а также оценки рисков.
Тест план должен отвечать на следующие вопросы:
- Что необходимо протестировать?
- Как будет проводиться тестирование?
- Когда будет проводиться тестирование?
- Критерии начала тестирования.
- Критерии окончания тестирования.
Основные пункты тест плана:
Чек-лист (check list) — это документ, который описывает что должно быть протестировано. Чек-лист может быть абсолютно разного уровня детализации.
Чаще всего чек-лист содержит только действия, без ожидаемого результата. Чек-лист менее формализован.
Тестовый сценарий (test case) — это артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Атрибуты тест кейса:
- Предусловия (PreConditions) — список действий, которые приводят систему к состоянию пригодному для проведения основной проверки. Либо список условий, выполнение которых говорит о том, что система находится в пригодном для проведения основного теста состояния.
- Шаги (Steps) — список действий, переводящих систему из одного состояния в другое, для получения результата, на основании которого можно сделать вывод о удовлетворении реализации, поставленным требованиям.
- Ожидаемый результат (Expected result) — что по факту должны получить.
Резюме
Автоматизация тестирования абсолютно неотъемлема и необходима в современной разработке программного обеспечения. Ее преимущества известны всем, что делает автоматизацию тестирования желанным для применения. Факт, отказ от ручного тестирования, сокращение затрат и автоматизация в спринте (in-sprint automation) подталкивают компании внедрять автоматизацию как можно скорее в собственные проекты. У каждой компании свой подход к достижению цели. Однако, они все совершают одинаковые ошибки в процессе внедрения автоматизированного тестирования.
Работая над фреймворками для автоматизированного тестирования, я пытался определить общие проблемы, с которыми сталкиваются организации, и ошибки, которые они совершают. Эти ошибки создают эффект снежного кома и влияют на возврат инвестиций (ROI) от автоматизации.
Улучшай внедрение автоматизации, избегая распространенных ошибок
Жизненный цикл автоматизированного тестирования
Для планирования, реализации и поддержки автоматизированных тестов, я разделяю автоматизацию на 4 этапа. Это помогает мне отслеживать и контролировать автоматизацию на проектах. Этапы имеют следующие названия:
- Внедрение и выполнение автоматизации.
- Поддержка и улучшение автоматизации.
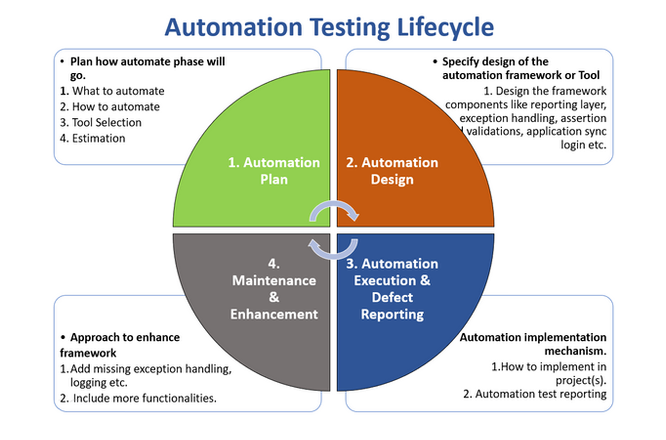
Жизненный цикл автоматизированного тестирования
Я хотел бы представить распространенные ошибки в каждом из 4 этапов. Давайте посмотрим на них.
Ошибки на этапе планирования автоматизации
- Не рассчитана окупаемость инвестиций (ROI).
- Нет плана автоматизации/цели автоматизации.
- Не определен и не приоритизирован объем тестирования перед стартом автоматизации.
- Отсутствие задокументированных требований к среде автоматизации/нереалистичные ожидания.
- Выбран неправильный уровень тестирования для автоматизации.
- Выбор инструментов, так как они open-source или бесплатные.
- Выбор неправильных инструментов автоматизации.
- Выбор инструментов на основе навыков команды.
1 Не рассчитана окупаемость инвестиций (ROI)
Первая и наиболее частая ошибка, это незнание команд окупятся ли усилия, которые вложат в автоматизацию, или нет. Первоначальная цель автоматизации, это уменьшение расходов при увеличении уровня качества. Рассчитываем мы ROI при внедрении автоматизации в проект? Если ответ нет, какой смысл в автоматизации? Это фундаментальная проверка, которую должный делать команды перед началом автоматизации.
Решение проблемы — с помощью формулы ниже рассчитать ROI в автоматизацию.
RIO = «Затраты ручного тестирования, которые уменьшает автоматизация» — («Затраты на автоматизацию» — «Затраты на поддержку автоматизации»)
2 Нет плана автоматизации/цели автоматизации
Они говорят «Плохой план лучше чем его отсутствие». Однако, 80% проектов используют автоматизированное тестирование без плана. Неудивительно почему так много проектов автоматизации не оправдывают ожидания. Это происходит потому что нет шагов автоматизации, неявно установлена цель или нет сигнала о готовности начать, по сути, отсутствие плана автоматизированного тестирования. Часто проекты автоматизации выполняются одновременно с ручным тестированием, но как раз определить различия этих подходов? Насколько отличается их реализация? Разве не требуется различное мышление для выполнения ручного и автоматизированного тестирования? Получается, что нужен план для каждого подхода с разными критериями успеха?
Решение проблемы — создать эксклюзивный, специализированный и исчерпывающий план автоматизированного тестирования.
3 Не определен и не приоритизирован объем тестирования перед стартом автоматизации
Обычно говорят «нельзя улучшить то, что нельзя измерить», что верно при запуске проектов автоматизации. Как мы можем начать ее без определения объема тестирования? Без этого мы не можем измерить и сравнить результаты автоматизации. Без определения объема мы будем неуверенными на каждом этапе тестирования.
Решение проблемы — определить объем тестирования
Отсутствие задокументированных требований к среде автоматизации/нереалистичные ожидания
Был ли у вас когда-либо задокументированные требования к среде автоматизации? Мы убедились, что сложность разработки среды для автоматизации практические такая же, как и для разработки бизнес-приложений. Мы не начинаем разработку таких приложений без документации, но при этом начинаем автоматизацию без нее. Это приводит к неправильным/неизвестным ожиданиям от среды автоматизации и часто они нереалистичны.
- Среда автоматизации — не начинать разрабатывать среду автоматизации без задокументированных требований к ней и определения цели автоматизации.
- Инструменты автоматизации — составить требования и ожидания от инструментов автоматизации и используйте инструменты, которые соответствуют требованиям.
Выбран неправильный уровень тестирования для автоматизации
Часто тестировщики фокусируются на автоматизации UI тестов для обеспечения end-to-end тестирования вместо интеграционных, API и БД тестов. Автоматизация нижних уровней тестирования обеспечит лучшее и детальное тестовое прикрытие с большей скоростью и меньшими затратами. UI тесты медленные и их дорого поддерживать. При этом мы не можем исключать тестирования UI, особенно для продуктов ориентированных на пользователя и продуктов Saas, но можем свести его к минимуму.
Решение проблемы — Понимать и следовать пирамиде тестирования, это фундамент успеха и эффективности автоматизации. Уделять больше внимания тестированию на низком, чем на более верхнем уровне пирамиды тестирования.

Выбор инструментов, так как они open-source или бесплатные
Основная причина неудач автоматизации — выбор инструментов или библиотек потому, что они бесплатные или имеют открытый исходный код. Хотя эти они отлично работают, если разработаны должным образом, однако в этом заключается проблема.
Разработка среды автоматизации — это, по сути, тот же процесс, что и разработка других бизнес приложений командой разработчиков. Это словно полноценный проект разработки, который должен иметь свои строгие стандарты жизненного цикла программного обеспечения (SDLC). Разработчики среды автоматизации должны иметь тот же уровень компетенций, что и разработчики приложений. Потому, что возникает необходимость в процессах проверки кода, архитектуры, утверждении дизайна среды, тестировании, соблюдении стандартов кодирования, управлении кода и т. Если мы ожидаем качественный результат от автоматизации, разработанная среда автоматизации должна соответствовать всем практикам (best practices) SDLC.
Все это имеет цену и она может быть высокой. Риск провала проекта автоматизации высок, поскольку у организации всегда есть другие бизнес обязательства. Следовательно, бесплатное ПО и ПО с открытым исходным кодом не может быть «бесплатным» и существует риск неудачи, если оно не будет правильно разработано.
- Использовать best practices для разработки среды автоматизации, которым следуют разработчики бизнес приложений.
- Рассмотреть платные или менее дорогостоящие инструменты на рынке, которые обеспечат экономию средств.
7 Выбор неправильных инструментов автоматизации
Популярный инструмент может не подходить для нашей задачи. Следовательно, команда тестирования должна сосредотачиваться на сценарии использования при выборе инструмента для автоматизации.
- Определить для чего нужен инструмент автоматизации. Определить уровень в пирамиде тестирования. Подход к выбору инструмента может быть легче, если исходить из уровня тестирования.
- Применяя POC, использовать пробный период выбранного инструмента.
8 Выбор инструментов на основе навыков команды
Еще одна проблема заключается в выборе инструмента основываясь на навыках команды. Мир движется к no-code решениям и автоматизированное тестирования тоже. No-code инструменты автоматизации обеспечат более быструю работы без дополнительных навыков.
Решение проблемы — цель автоматизации не в улучшении навыков программирования команды, а скорее в сохранении средств ручного тестирования. Если первичная цель организации не в автоматизации тестирования, то лучше выбрать готовый инструмент, а не разрабатывать свой. Особенно для маленьких организаций лучше внедрить готовый инструмент, так как разработка и поддержка собственной среды автоматизации будет иметь низкую ROI, чем готовый платный инструмент.
Ошибки на этапе проектирования/разработки автоматизации
- Нет дизайна разрабатываемой системы.
- Нет обработки исключений.
- Неправильный механизм логирования.
- Нет стратегии управления кодом/ветками и управления выпуском.
1 Нет дизайна разрабатываемой системы
Классические проблемы с которыми сталкиваются при разработке приложений возникают и при разработке среды автоматизации. На самом деле, возможно, в большем масштабе чем разработчики приложений, потому что имеют более низкий уровень знаний. Отсутствие документации, в которой содержится информация о дизайне автоматизации приведет к некачественной разработке, потому что —
- Неструктурированные модули/монолитное приложение.
- Неправильные паттерны проектирования.
- Неприменение best practices.
- Нет процесса ревью кода.
- Низкая возможность переиспользование кода.
- Отсутствие модульности на функциональном уровне.
- Нет этапа тестирования самой среды автоматизации.
Нет обработки исключений
Часто ошибки, которые возникают в среде автоматизации необходимо исследовать и исправить в самом коде, потому что нет обработки исключений в самом коде в первую очередь. Следовательно, в отчете после выполнения нет удобных (изящных) исключений.
Решение проблемы — все типы исключений должны быть обработаны на каждом функциональном уровне. Код должен пройти процесс ревью для исключения отсутствия обработки исключений.
3 Неправильный механизм логирования
Среда автоматизации должна иметь эффективную систему логирования ошибок, с помощью которой осуществляется отслеживание и исправление дефектов без просмотра кода среды.
Решение проблемы — эффективный механизм логирования с указанием успешных шагов, ошибок и предупреждений должен интегрироваться в среду автоматизации.
4 Нет стратегии управления кодом/ветками и управления выпуском
Среда автоматизации содержит большое количество кода. Часто возникают конфликты в коде при работе над ним нескольких разработчиков. Это приводит к неструктурированному кода и неизбежным конфликтам в нем. При написании тестовых скриптов в среде автоматизации возникают сложности, которые заставить выпускать новые версии среды.
Решение проблемы — внедрение стратегии ветвления для среды автоматизации для совместной работы и увеличения функционала. Затем применять систему управления выпуском и использовать раздельно ветку разработки и выпуска.
Ошибки на этапе внедрения и выполнения автоматизации
- Отсутствие определения объема тестирования.
- Нет стратегии управления данными.
- Автоматизация больших потоков.
- Не проводится проверка тестов.
1 Отсутствие определения объема тестирования
Решение проблемы — перед запуском тестовых скриптов должен быть определен объем для покрытия автоматизацией. Объем регрессивного тестирования должен быть определен с целью последующей автоматизации.
Нет стратегии управления данными
Среда автоматизации должна иметь правильную стратегию управления данными. Хранение данных в файлах excels, csv и т. устарело и замедляет выполнение тестов. Также, переменные с тестовыми данными не должны храниться в коде скриптов.
Решение проблемы — среда автоматизации должна иметь возможность хранить и предоставлять тестовые данные в удобном формате JSON, XML и т.
3 Автоматизация длинной бизнес логики
Решение проблемы — разделение длинных скриптов на маленькие поможет повысить стабильность их выполнения. Скорость прохождения набора тестов увеличится, а ошибки будут корректно указываться в точках сбоя.
Не проводится проверка тестов
Часто автоматизированные скрипты не подвергаются проверки. Ручной тестировщик проверяет сценарии во время их выполнения, но автоматизаторы часто пропускают проверку фактического результата и ожидаемого в разработанных скриптах. Следовательно, ухудшают тестовое покрытие.
Решение проблемы — получить подтверждение правильности скриптов от заинтересованного лица. Заинтересованным лицом может быть бизнес аналитик или QA.
Ошибки на этапе поддержки и улучшения автоматизации
- Нет обновления кода скриптов при изменении функционала тестируемого приложения.
- Редкие запуски тестов.
- Зависимость от члена команды.
1 Нет обновления кода скриптов при изменении функционала тестируемого приложения
Изменения или улучшения функционала приводит к волновому эффекту. Не обновляя код тестовых скриптов приводит к их устареванию.
Решение проблемы — Среда автоматизации должна иметь возможность легко обновлять тестовые скрипты. Какая польза от среды автоматизации, если при каждом изменении функциональности приложения нужно вносить изменения в ее код для улучшения тестовых скриптов? Это худший дизайн среды автоматизации.
2 Редкие запуски тестов
Команда автоматизаторов должна иметь техническую возможность запускать тесты часто. Во время гибких методологий разработки, это становится наиболее важным. Редкий запуск тестов создает две проблемы:
- Не реализация потенциала автоматизации и недостаточное тестирование приложения.
- Мы не сможем понять насколько устарел наш тестовый скрипт относительно изменений функционала тестируемого приложения. Частый запуск тестов обеспечивает своевременную проверку актуальности тестов. Это также гарантирует, что мы постепенно обновляем скрипты, избегая их устаревания и неуправляемых изменений.
Решение проблемы — Запуск автоматизации на отдельно выделенной машине обеспечивает работу скриптов в любое время и без потери времени автоматизатора. Еще лучшим подходом является интеграция запуска тестов в CI/CD.
3 Зависимость от члена команды
Другой ошибкой является зависимость от конкретного сотрудника для запуска тестов или зависимость от его учетных данных. Это ненужная зависимость, которая уменьшает гибкость автоматизации.
Решение проблемы — Создать и использовать общие ID, предоставлять доступ к приложению по общему ID и запускать тесты используя общей ID.
Вот объединенный список частых ошибок, которые возникают во время планирования и внедрения в проекты у команд автоматизации.
Планирование автоматизации
- Формальные доказательства из программной архитектуры верифицированного микроядра можно недорого масштабировать на реальные системы.
- Возможны и желательны разные уровни безопасности и надёжности в рамках одной системы. Необязательно обеспечивать максимальную надёжность всего кода.
- Достаточно умеренного редизайна и рефакторинга, чтобы поднять существующие системы до уровня высоконадёжного кода.
В этой статье объясняются эти изменения и технология, которая сделала их возможными. Речь идёт о технологии, разработанной в рамках программы HACMS, направленной на обеспечение безопасной работы критических систем во враждебной киберсреде — в данном случае, нескольких автономных транспортных средств. Технология основана на формальной верификации программного обеспечения — это программы с автоматически проверенными математическими доказательствами, которое работает в соответствии со своей спецификацией. Хотя статья не посвящена самим формальным методам, она объясняет, как использовать верификацию артефактов для защиты реальных систем на практике.
Возможно, самый впечатляющий результат HACMS — что технологию можно распространить на существующие реальные системы, значительно улучшив их защиту от кибератак. Этот процесс называется «сейсмической модернизацией безопасности» (seismic security retrofit) по аналогии с сейсмической модернизацией зданий. Более того, большая часть реинжиниринга сделана инженерами компании «Боинг», а не специалистами по формальной верификации.

«Птичка» во время беспилотного испытательного полёта
Далеко не весь софт на вертолёте построен на математических моделях и доказательствах. Область формальной верификации ещё не готова к такому масштабу. Тем не менее, программа HACMS продемонстрировала, что стратегическое применение формальных методов к наиболее важным частям общей системы значительно улучшает защиту. Подход HACMS работает для систем, в которых желаемое свойство безопасности может быть достигнуто посредством чисто принудительного применения на уровне архитектуры. В его основе — наше верифицированное микроядро sel4, о котором поговорим ниже. Оно гарантирует изоляцию между подсистемами, за исключением чётко определённых каналов связи, на которые распространяется политика безопасности системы. Эта изоляция гарантируется на уровне архитектуры с помощью верифицированного фреймворка CAmkES для системных компонентов. С помощью предметно-ориентированных языков от Galois Inc. платформа CAmkES интегрируется с инструментами анализа архитектуры от Rockwell Collins и университета Миннесоты, а также с высоконадёжными программными компонентами.
Достижения HACMS основаны на старом верном друге инженера-программиста — модуляризации. Инновация в том, что формальные методы доказывают наблюдаемость интерфейсов и инкапсуляцию внутренностей модулей. Это гарантированное соблюдение модульности позволяет инженерам, которые не являются экспертами по формальным методам (как в компании «Боинг»), создавать новые или даже модернизировать существующие системы и достигать высокой устойчивости. Хотя инструменты пока не обеспечивают полного доказательства безопасности системы.
Формальная верификация
Доказательства математической корректности программ восходят, по крайней мере, к 1960-м годам, но долгое время их реальная польза для разработки программного обеспечения была ограничена масштабом и глубиной. Однако в последние годы произошёл ряд впечатляющих прорывов в формальной верификации на уровне кода реальных систем, от верифицированного компилятора C CompCert до верифицированного микроядра seL4 (см. научные статьи о нём), верифицированной системы конференц-связи CoCon, верифицированного ML-компилятора CakeML, верифицированных программ для доказательства теорем Milawa и Candle, верифицированной файловой системы с защитой от сбоев FSCQ, верифицированной распределённой системы IronFleet и верифированного фреймворка параллельного ядра CertiKOS, а также важных математических теорем, в том числе проблемы четырёх красок, автоматического доказательства гипотезы Кеплера и теоремы Фейта — Томпсона о нечётном порядке. Всё это настоящие системы. Например, CompCert — коммерческий продукт, микроядро seL4 используется в аэрокосмической и беспилотной авиации, в качестве платформы Интернета вещей, а система CoCon использовалась на многочисленных крупных научных конференциях.
Эти проекты верификации требуют значительных усилий. Чтобы сделать формальные методы общедоступными, эти усилия необходимо сократить. Здесь мы демонстрируем, как стратегическое сочетание формальных и неформальных методов, частичная автоматизация формальных методов и тщательная разработка программного обеспечения для максимизации преимуществ изолированных компонентов позволили нам значительно повысить надёжность систем, общий размер и сложность которых на порядки больше, чем у упомянутых выше.
Обратите внимание, мы применяем формальную верификацию в первую очередь для кода, от которого зависит безопасность системы. Но есть и другие преимущества. Например, доказательства корректности кода делают предположения о контексте, в котором он выполняется (например, о поведении оборудования и конфигурации программного обеспечения). Формальная верификация делает эти предположения явными, что помогает разработчикам сфокусироваться на других средствах верификации, таких как тестирование. Кроме того, во многих случаях система включает и проверенный, и непроверенный код. Во время код-ревью, тестирования и отладки формальная верификация действует как объектив, фокусируя внимание на критическом непроверенном коде системы.
SeL4
Начнём с фундамента для построения доказуемо надёжных систем — ядра операционной системы (ОС). Это наиболее важная часть, которая экономически эффективно гарантирует надёжность всей системы.
Микроядро seL4 предоставляет формально верифицированный минимальный набор механизмов для реализации защищённых систем. В отличие от стандартных ядер, оно целенаправленно универсально и поэтому подходит для реализации ряда политик безопасности и системных требований.
Одна из основных целей разработки seL4 заключается в обеспечении сильной изоляции между взаимно не доверяющими друг другу компонентами, которые работают поверх ядра. Поддерживается его работа в качестве гипервизора, например, для целых операционных систем Linux, сохраняя при этом их изолированными от критичных для безопасности компонентов, которые могут работать вместе, как показано на рисунке 1. В частности, эта функция позволяет разработчикам систем использовать устаревшие компоненты со скрытыми уязвимостями рядом с высоконадёжными компонентами.
Рис. Изоляция и контролируемые коммуникации в seL4
Ядро seL4 занимает особое положение среди микроядер общего назначения. Мало того, что оно обеспечивает лучшую производительность в своем классе, его 10 000 строк кода C прошли более тщательную формальную верификацию, чем любое другое общедоступное программное обеспечение в истории человечества с точки зрения не только строк доказательства, но и прочности доказанных свойств. В основе лежит доказательство «функциональной корректности» реализации ядра на C. Оно гарантирует, что любое поведение ядра предсказывается его формальной абстрактной спецификацией: см. онлайн-приложение для представления о том, как выглядят эти доказательства. Следуя этой гарантии, мы добавили дополнительные доказательства, которые объясним после введения в основные механизмы ядра.
SeL4 API
Ядро seL4 предоставляет минимальный набор механизмов для реализации защищённых систем: потоки, управление «способностями», виртуальные адресные пространства, межпроцессное взаимодействие (IPC), сигнализация и доставка прерываний.
Ядро сохраняет своё состояние в «объектах ядра». Например, для каждого потока в системе существует «объект потока», хранящий информацию о шедулинге, выполнении и управлении доступом. Программы пользовательского пространства могут ссылаться на объекты ядра только косвенно через так называемые «способности» или «возможности» (capabilities), которые объединяют ссылку на объект с набором прав доступа к нему. Например, поток не может запустить или остановить другой поток, если не имеет «способности» для соответствующего объекта потока.
Потоки взаимодействуют и синхронизируются путём отправки сообщений через объекты «конечная точка» (endpoint) межпроцессного взаимодействия. Один поток со способностью отправки на соответствующую конечную точку может отправить сообщение другому потоку, имеющему способность получения на эту конечную точку. Объекты «уведомление» (notification) обеспечивают синхронизацию через наборы двоичных семафоров. Виртуальное преобразование адресов управляется объектами ядра, которые представляют каталоги страниц, таблицы страниц и объекты фреймов или тонкие абстракции над соответствующими объектами процессорной архитектуры. У каждого потока есть определённая способность “VSpace”, которая указывает на корень дерева объектов преобразования адресов потока. Сами возможности управляются ядром и хранятся в объектах ядра “CNodes”, расположенных в структуре графа, который сопоставляет ссылки на объекты с правами доступа, аналогично сопоставлению виртуальных таблиц страниц с физическими адресами в памяти. У каждого потока своя способность идентификации корневого CNode. Набор способностей, доступных из этого корня, мы называем «CSpace потока». Способности могут передаваться через конечные точки с передачей работы, а также их можно объявлять общими с помощью общих CSpace. Рисунок 2 демонстрирует эти объекты ядра.
Рис. Объекты ядра в системе на seL4 с двумя потоками, взаимодействующими через конечную точку
Доказательства безопасности
Благодаря своей универсальности API-интерфейсы ядра seL4 работают на низком уровне и поддерживают высокодинамичные системные архитектуры. Поэтому прямые доказательства для этих API проблематично получить.
Высокоуровневая концепция политик управления доступом абстрагируется от отдельных объектов и возможностей ядра, захватывая вместо этого конфигурацию управления доступом системы с помощью набора абстрактных «субъектов» (компонентов) и полномочий, которые каждый из них имеет над другими (например, для чтения данных и отправки сообщений). В примере на рис. 2, компоненты A и B получили полномочия над конечной точкой.
В работе Сьюэлла с коллегами доказано, что политики контроля доступа seL4 гарантируют соблюдение двух основных свойств безопасности: ограничение полномочий и целостность.
Ограничение полномочий означает, что политика контроля доступа является статическим (неизменным) безопасным приближением конкретных возможностей и объектов ядра в системе для любого будущего состояния. Это свойство подразумевает, что независимо от того, как развивается система, ни один компонент никогда не получит больше полномочий, чем предсказывает политика контроля доступа. На рисунке 2 политика для компонента B не содержит доступа на запись к компоненту A. Таким образом, компонент B никогда не сможет получить этот доступ в будущем. Это свойство подразумевает, что рассуждения на уровне политики являются безопасным приближением к рассуждениям о конкретном состоянии контроля доступа в системе.
Целостность означает, что независимо от того, что делает компонент, он никогда не сможет изменять данные в системе (включая любые системные вызовы, которые он может выполнять), которые ему явно не разрешает изменять политика контроля доступа. Например, на рис. 2 единственным компонентом полномочий A над другим компонентом является право отправки данных на конечную точку, откуда получает информацию компонент B. Это означает, что компонент А способен изменять только своё состояние, состояние потока B и состояние буфера сообщений. Он не может изменять другие части системы.
Побочный эффект целостности — это конфиденциальность, когда компонент не способен без разрешения прочитать информацию из другого компонента: это доказанное сильное свойство нетранзитивного невмешательства seL4. То есть в должным образом настроенной системе (с более жёсткими ограничениями, чем просто для целостности) ни один из компонентов не сможет без разрешения узнать информацию о другом компоненте или его исполнении. Доказательство выражает это свойство в терминах политики информационного потока, которую можно извлечь из политики управления доступом, используемой в доказательстве целостности. Информация будет передаваться только тогда, когда это явно разрешено политикой. Доказательство охватывает явные информационные потоки, а также потенциальные каналы скрытого хранения в ядре. Но каналы синхронизации находятся вне его области и должны обрабатываться иными средствами.
Дальнейшие доказательства в seL4 включают расширение функциональной корректности и, следовательно, теорем безопасности до бинарного уровня для архитектуры ARMv7 и профиль худшего времени выполнения для ядра (1, 2), необходимый для систем реального времени. Ядро seL4 доступно для разных архитектур: ARMv6, ARMv7 ARMv7a, ARMv8, RISC-V, Intel x86 и Intel x64. На данный момент оно прошло машинную проверку на архитектуре ARMv7 для всего стека верификации, а также на ARMv7a с расширениями гипервизора для функциональной корректности.