
Тестирование PVS-Studio
Разработка анализаторов кода невозможна без их постоянного тщательного тестирования. При разработке PVS-Studio мы используем 7 различных методик тестирования:
- Статический анализ кода на машинах разработчиков. У всех разработчиков установлен PVS-Studio. Новый или изменённый код сразу проверяется с помощью механизма инкрементального анализа. Проверяется C++ и С# код.
- Статический анализ кода при ночных сборках. Если предупреждение не было замечено, то оно выявится на этапе ночной сборки на сервере. PVS-Studio проверяет C# и C++ код. Помимо этого, мы дополнительно используем компилятор Clang для проверки C++ кода.
- Юнит-тесты уровня классов, методов, функций. Не очень развитая система, так как многие моменты сложно тестировать из-за необходимости подготавливать для теста большой объем входных данных. Мы больше полагаемся на высокоуровневые тесты.
- Функциональные тесты уровня специально подготовленных и размеченных файлов с ошибками. Это наша альтернатива классическому юнит-тестированию.
- Функциональные тесты, подтверждающие, что мы корректно разбираем основные системные заголовочные файлы.
- Регрессионные тесты уровня отдельных сторонних проектов и решений (projects and solutions). Самый важный и полезный для нас вид тестирования. Сравнивая старые и новые результаты анализа, мы контролируем, что что-то не сломали и оттачиваем новые диагностические сообщения. Для его осуществления мы регулярно проверяем открытые проекты. C++ анализатор тестируется на 120 проектах под Windows (Visual C++), плюс дополнительно на 24 проектах под Linux (GCC). Анализатор C# пока тестируется чуть слабее. Тестовая база состоит из 54 проектов.
- Функциональные тесты пользовательского интерфейса расширения — надстройки, интегрируемой в среду Visual Studio.
Дополнительные материалы
Алгоритм отладки
-
Проверь гипотезу — если гипотеза проверку не прошла то п.3.
-
Убедись что исправлено — если не исправлено, то п.3.
Подробнее ознакомиться с ним можно в докладе Сергея Щегриковича «Отладка как процесс».
Чем искать ошибки, лучше не допускать ошибки. Прочитайте статью «Качество вместо контроля качества», чтобы узнать как это делать.
Azure DevOps Server

Azure DevOps Server — это система отслеживания ошибок, которая позволяет всем заинтересованным сторонам участвовать в процессе разработки через единый интерфейс.
- Когда речь идет об отслеживании ошибок, TFS уведомляет членов команды и отслеживает, кто несет ответственность за проблему.
- Поскольку TFS интегрируется с Active Directory, передача проблемных исправлений клиенту, который сообщил о проблеме, очень проста.
- Поддерживается совместная работа, контроль версий и Agile-планирование.
RedMine

RedMine — это программа отслеживания ошибок с интеграцией SCM (системы управления исходным кодом), которая является свободным источником.
- Отчетность ведется с помощью диаграмм Ганта и календарей, и она работает с различными платформами и базами данных.
- В данном проекте используется фреймворк Ruby on Rails.
- В нем есть онлайн-инструмент управления проектами.
- Предлагает удобный механизм отслеживания проблем.
- Имеет механизм управления доступом на основе ролей, который является достаточно универсальным.
- Поддерживает несколько различных языков.
- Управляет диаграммами Ганта и календарями, а также документами и данными.
- Этот инструмент отчетности об ошибках интегрируется с SCM.
- Поддерживает создание вопросов на основе электронной почты
- Программа отслеживания ошибок поддерживает несколько баз данных.
Trac

Trac — это веб-система управления проблемами с открытым исходным кодом на базе Python.
- Это более продвинутая версия вики, которая используется для отслеживания проблем в проектах по разработке программного обеспечения.
- Когда Trac и SCM объединены, вы можете пройтись по коду, изучить историю, посмотреть изменения и т.д.
- Он совместим с широким спектром операционных систем, включая Linux, Unix, Mac OS X, Windows и другие.
- Временная шкала показывает все текущие и предыдущие мероприятия проекта в хронологическом порядке, в то время как дорожная карта показывает предстоящие этапы.
QACoverage

QACoverage — это универсальный инструмент для оптимизации всех процедур тестирования, позволяющий создавать высококачественные продукты без ошибок. Это еще один лучший бесплатный инструмент для отслеживания ошибок.
- В нем есть интеграция с Jira, а также многое другое.
- Процесс отслеживания дефектов может быть адаптирован к потребностям клиента.
- Помимо дефектов, QACoverage предлагает возможность отслеживать риски, проблемы, обновления, предложения и рекомендации.
- Также включает в себя комплексные инструменты управления тестированием, включая управление требованиями, определение тестовых случаев, выполнение и отчетность.
- С помощью автоматических уведомлений он может создавать и применять процессы для улучшения видимости повторного тестирования.
- Может создавать графические отчеты на основе серьезности, приоритета, типа дефекта, категории дефекта, предполагаемой даты устранения и ряда других параметров.
- В нем есть функция управления дефектами, которая позволяет отслеживать проблемы с момента их выявления до момента их устранения.
- В виде вложений он передает различную информацию, связанную с дефектами.
- Полное программное обеспечение для управления тестированием можно приобрести всего за $11,99 в месяц.
- Вы можете управлять всем процессом для различных типов тикетов, таких как риски, проблемы, задачи и улучшения.
- Вы можете создать подробные метрики, которые помогут вам определить основные причины и уровни серьезности.
Мы надеемся, что это руководство было полезным, и теперь вы сможете принять обоснованное решение среди представленных лучших бесплатных инструментов отслеживания ошибок.
Marker

Marker.io — это визуальный инструмент отчетности об ошибках для агентств и команд разработчиков программного обеспечения.
- Просто установите виджет сайта и собирайте отзывы с изображениями, аннотациями и техническими метаданными в предпочитаемой платформе управления проектами, такой как Jira, Trello, Asana, GitHub, ClickUp и других.
- Поставляется с виджетом Веб-сайт.
- С его помощью можно делать снимки экрана и делать замечания.
- Позволяет собирать технические данные (браузер, ОС, URL, журналы консоли).
- Синхронизируется в обоих направлениях с Jira, Trello, Asana, GitHub и ClickUp (и не только).
- Поставляется в виде расширения для браузера, плагина для WordPress и JS-кода.
- Имеет свой собственный уникальный брендинг.
Ещё раз кратко о технологиях
Кратко резюмирую свой рассказ о используемых технологиях. PVS-Studio использует:
- Сопоставление с шаблоном (pattern-based analysis) на основе абстрактного синтаксического дерева: применяется для поиска мест в исходном коде, которые похожи на известные шаблоны кода с ошибкой.
- Вывод типов (type inference) на основе семантической модели программы: позволяет анализатору иметь полную информацию о всех переменных и выражениях, встречающихся в коде.
- Символьное выполнение (symbolic execution): позволяет вычислять значения переменных, которые могут приводить к ошибкам, производить проверку диапазонов (range checking) значений.
- Анализ потока данных (data-flow analysis): используется для вычисления ограничений, накладываемых на значения переменных при обработке различных конструкций языка. Например, какие значения может принимать переменная внутри блоков if/else.
- Аннотированние методов (method annotations): предоставляет больше информации об используемых методах, чем может быть получено путём анализа только их сигнатуры.
На основе этих технологий анализатор умеет выявлять следующие классы ошибок в программах на языках C, C++ и C#:
Вывод. Анализатор PVS-Studio является мощным инструментом поиска ошибок, использующим для этого современный арсенал методов для их выявления.

Да, PVS-Studio это положительный супергерой мира программ.
Axosoft

Axosoft — это решение для отслеживания ошибок, которое может быть установлено на месте или размещено на хостинге.
- Инструмент управления проектами для команд Scrum. Руководители проекта и разработчики могут рассматривать каждую задачу, ее требования, дефекты и инциденты в системе на отдельных файловых карточках с помощью доски планирования Scrum.
- Axosoft позволяет вам управлять историями пользователей, проблемами и запросами в службу поддержки, обеспечивая при этом просмотр прогресса в режиме реального времени.
- Одна из самых эффективных программ на рынке по удалению багов.
- Поддерживается доска планирования Scrum и диаграммы сгорания Scrum.
- Поддерживается управление требованиями.
- Доступны визуализация данных, интеграция с SCM, отчетность, служба поддержки и отслеживание инцидентов.
Наши достижения
Для популяризации PVS-Studio мы регулярно проверяем различные открытые проекты и описываем в статьях найденные в них ошибки. На данный момент мы проверили около 270 проектов.
В процессе написания этих статей мы выявили уже более 10000 ошибок, о которых сообщили авторам проектов. Мы очень гордимся этим и сейчас я поясню почему.
Если разделить количество найденных ошибок на количество проектов, то получается не очень внушительное число: около 40 ошибок на проект. Поэтому я хочу выделить важный момент. Эти 10000 ошибок являются побочным эффектом. Мы никогда не ставили целью выявить как можно больше ошибок. Часто мы останавливаемся, когда нашли достаточное количество дефектов в проекте, чтобы написать статью.
Это очень хорошо демонстрирует удобство и возможности анализатора. Мы гордимся тем, что можно просто брать незнакомые проекты и почти без всякой настройки анализатора сразу находить в них ошибки. Если бы это было не так, мы бы не выявили 10000 ошибок просто как побочный результат от написания статей в блог.
DevTrack

Devtrack — это не обычный трекер дефектов, но он хорошо справляется со своей работой, если это все, что вам нужно. Он не предназначен для использования в качестве традиционного трекера ошибок.
- У нее много функций, но наиболее известна она как средство отслеживания дефектов.
- Его можно приобрести отдельно или как часть Agile Studio, DevTest studio или DevSuite.
- Как следует из названия, это комплексное решение для пути внедрения.
- Поддерживаются как гибкие, так и водопадные проекты.
- Платный. Также имеется пробная версия без риска.
IBM Rational ClearQuest

Еще один из лучших бесплатных инструментов отслеживания ошибок — Clear Quest. Это клиент-серверное онлайн-приложение, которое помогает в процессе управления дефектами.
- С помощью IBM ClearQuest вы можете отслеживать, регистрировать и управлять любой проблемой.
- Как и любой другой инструмент, IBM rational quest предоставляет вам все преимущества решения для отслеживания ошибок.
- HP-UX, Linux и Microsoft Windows входят в число поддерживаемых операционных систем.
- Может помочь в наглядности и управлении проектами по разработке программного обеспечения.
- Интегрируется с рядом инструментов автоматизации, что может считаться преимуществом.
- Поскольку это коммерческий продукт, он может показаться дорогим. Вы можете попробовать его бесплатно в течение 30 дней.
- Имеет специализированную сквозную систему отслеживания дефектов.
Какие технологии мы не используем в PVS-Studio
Прежде чем рассказывать о внутреннем устройстве PVS-Studio кратко отмечу, чего в PVS-Studio нет.
PVS-Studio не имеет ничего общего с Prototype Verification System (PVS). Это просто совпадение. Аббревиатура PVS образована от названия нашей компании Program Verification Systems.
PVS-Studio не использует непосредственно математический аппарат грамматик для поиска ошибок. Анализатор работает на более высоком уровне. Анализ выполняется на основании дерева разбора.
PVS-Studio не использует компилятор Clang для анализа C/C++ кода. Clang используется для выполнения шага препроцессирования. Подробнее про это рассказано в статье «Немного о взаимодействии PVS-Studio и Clang«. Для построения дерева разбора мы используем собственный парсер, который был основан на забытой сейчас библиотеке OpenC++. Впрочем, от кода той библиотеки почти ничего не осталось, и мы реализуем поддержку новых конструкция языка самостоятельно.
При работе с C# кодом мы опираемся на Roslyn. C# анализатор PVS-Studio проверяет непосредственно исходный код программы, что повышает точность анализа по сравнению с проверкой бинарного байт-кода (Common Intermediate Lanuage).
PVS-Studio не использует для поиска ошибок поиск подстрок (string matching) и регулярные выражения (regular expressions). Это тупиковый путь. У такого подхода так много недостатков, что на его основе невозможно сделать хоть сколько-нибудь качественный анализатор, а многие диагностики в принципе невозможно реализовать. Подробнее эта тема рассмотрена в моей статье «Статический анализ и регулярные выражения«.
Monday

Monday также является одним из лучших инструментов отслеживания ошибок, который позволяет отслеживать проблемы и управлять командой в одном месте.
- Поставляется с настраиваемой приборной панелью, которая позволяет легко визуализировать данные.
- У вас есть способность сотрудничать с другими людьми.
- Способен автоматизировать ваши ежедневные обязанности.
- Такие сервисы, как Mailchimp, Google Calendar, Gmail и другие, подключены.
- Вы можете отслеживать свой прогресс.
- Позволяет работать из любого места.
Unfuddle

Unfuddle — еще один из лучших бесплатных инструментов отслеживания ошибок для разработчиков (но все же система отслеживания ошибок), который интегрируется с Git и Subversion.
- Unfuddle позволяет разработчикам вносить исходный код.
- Может работать с большинством основных инструментов разработки программного обеспечения.
- Unfuddle обеспечивает превосходную защиту данных, поскольку использует серверы Amazon.
- Помогает отслеживать проблемы, запросы на функции и управлять тикетами.
- Он обрабатывает такие проблемы, как запросы, и предлагает веб-средство просмотра репозитория для проверки изменений файлов.
- Есть бесплатная пробная версия.
Автоматическое тестирование программ
9 мин
46K
Введение
Долгое время считалось, что динамический анализ программ является слишком тяжеловесным подходом к обнаружению программных дефектов, и полученные результаты не оправдывают затраченных усилий и ресурсов. Однако, две важные тенденции развития современной индустрии производства программного обеспечения позволяют по-новому взглянуть на эту проблему. С одной стороны, при постоянном увеличении объема и сложности ПО любые автоматические средства обнаружения ошибок и контроля качества могут оказаться полезными и востребованными. С другой – непрерывный рост производительности современных вычислительных систем позволяет эффективно решать все более сложные вычислительные задачи. Последние исследовательские работы в области динамического анализа такие, как SAGE, KLEE и Avalanche, демонстрируют, что несмотря на присущую этому подходу сложность, его использование оправдано, по крайней мере, для некоторого класса программ.
Динамический vs Статический анализ
В качестве более эффективной альтернативы динамическому анализу часто рассматривают статический анализ. В случае статического анализа поиск возможных ошибок осуществляется без запуска исследуемой программы, например, по исходному коду приложения. Обычно при этом строится абстрактная модель программы, которая, собственно, и является объектом анализа.
При этом следует подчеркнуть следующие характерные особенности статического анализа:
- Возможен раздельный анализ отдельно взятых фрагментов программы (обычно отдельных функций или процедур), что дает достаточно эффективный способ борьбы с нелинейным ростом сложности анализа.
- Возможны ложные срабатывания, обусловленные либо тем, что при построении абстрактной модели некоторые детали игнорируются, либо тем, что анализ модели не является исчерпывающим.
- При обнаружении дефекта возникают, во-первых, проблема проверки истинности обнаруженного дефекта (false positive) и, во-вторых, проблема воспроизведения найденного дефекта при запуске программы на определенных входных данных.
В отличие от статического анализа, динамический анализ осуществляется во время работы программы. При этом:
- Для запуска программы требуются некоторые входные данные.
- Динамический анализ обнаруживает дефекты только на трассе, определяемой конкретными входными данными; дефекты, находящиеся в других частях программы, не будут обнаружены.
- В большинстве реализаций появление ложных срабатываний исключено, так как обнаружение ошибки происходит в момент ее возникновения в программе; таким образом, обнаруженная ошибка является не предсказанием, сделанным на основе анализа модели программы, а констатацией факта ее возникновения.
Применение
Автоматическое тестирование в первую очередь предназначено для программ, для которых работоспособность и безопасность при любых входных данных являются наиважнейшими приоритетами: веб-сервер, клиент/сервер SSH, sandboxing, сетевые протоколы.
Fuzz testing (фаззинг)
Фаззинг – методика тестирования, при которой на вход программы подаются невалидные, непредусмотренные или случайные данные.
Основная идея такого подхода состоит в том, чтобы случайным образом “мутировать”, т.е. изменять ожидаемые программой входные данные в произвольных местах. Все фаззеры работают примерно одинаковым образом, позволяя задавать некоторые ограничения на мутирование входных данных определенными байтами или последовательностью байтов. В качестве примера можно упомянуть:zzuf (linux), minifuzz (Windows), filefuzz (Windows). Фаззеры протоколов: PROTOS(WAP, HTTP-reply, LDAP, SNMP, SIP) (Java), SPIKE (linux) . Фреймворки фаззеров: Sulley (фреймворк для создания сложных структур данных).
Fuzz testing – предтеча автоматического тестирования, метод “грубой силы”. Из преимуществ данного подхода выделяется только его простота. Очевидным же недостатком является то, что фаззер ничего не знает о внутреннем устройстве программы и, в конечном итоге, для полного покрытия кода вынужден перебирать астрономическое количество вариантов (как нетрудно догадаться, полный перебор растет экспоненциально от размера входных данных O(c^n),c>1).
Фаззеры нового поколения (обзор)
Логическим, но не таким простым продолжением идеи автоматического тестирования стало появление подходов и программ, позволяющих накладывать ограничения на мутируемые входные данные с учетом специфики исследуемой программы.
Отслеживание помеченных данных в программе
Вводится понятие символических или помеченных (tainted) данных – данных, полученных программой из внешнего источника (стандартный поток ввода, файлы, переменные окружения и т. д.). Распространенным решением этой задачи является перехват набора системных вызовов: open, close, read, write, lseek (Avalanche,KLEE).
Инструментация кода
Код исследуемой программы приводится к виду, удобному для анализа. Например, используется внутреннее независимое от аппаратной платформы представление valgrind (Avalanche) или анализируется удобный для разбора сам по себе llvm-байткод программы(KLEE).
Инструментированный код позволяет легко находить потенциально опасные инструкции (например, деление на ноль или разыменование нулевого указателя) и их операнды, а также инструкции ветвления, зависящие от помеченных данных. Анализируя инструкции, инструмент составляет логические условия на помеченные данные и передает запрос на выполнимость “решателю” булевских формул (SAT Solver).
Решение булевских ограничений
SAT Solvers – решают задачи выполнимости булевых формул. Отвечают на вопрос: всегда ли выполнена заданная формула, и если не всегда, то выдается набор значений, на котором она ложна. Результаты работы подобных решателей используется широким набором анализирующих программ, от theorem provers до анализаторов генетического кода в биоинформатике. Подобные программы интересны сами по себе и требуют отдельного рассмотрения. Примеры: STP, MiniSAT.
Моделирование окружения
Кроме перехвата системных вызовов, для автоматической генерации условий для “решателя” булевских формул, анализаторам необходимо формализовать задачу. Входной файл, набор регистров и адресное пространство (память) программы представляются c помощью массивов булевского “решателя”.
Перебор путей в программе
Получив ответ от “решателя”, инструмент получает условие на входные данные для инвертирования исследуемого условного перехода или выясняет, что оно всегда истинно или ложно. Каждый вариант условия создает новый независимый путь в программе, и программе приходится рассматривать каждый путь и условия для его выполнения независимо, т.е. пути “форкаются” на каждой инструкции ветвления, зависящей от входных данных. Новые входные данные могут открыть ранее не открытые базовые блоки исследуемой программы и так далее. Для исчерпывающего тестирования необходим полный перебор всех возможных путей в программе. Так как скорость роста количества путей хоть и значительно снизилась по сравнению с методом грубой силы (~O(2^n), где n – количество условных переходов, зависящих от входных данных), но все еще остается значительной. Анализаторы вынуждены использовать различные эвристики для приоритезации анализа некоторых путей. В частности, различают выбор пути, покрывающего наибольшее количество непокрытых (новых) базовых блоков (Avalanche, KLEE) и выбор случайного пути (KLEE).
Avalanche
Avalanche – инструмент обнаружения программных дефектов при помощи динамического анализа. Avalanche использует возможности динамической инструментации программы, предоставляемые Valgrind, для сбора и анализа трассы выполнения программы. Результатом такого анализа становится либо набор входных данных, на которых в программе возникает ошибка, либо набор новых тестовых данных, позволяющий обойти ранее не выполнявшиеся и, соответственно, еще не проверенные фрагменты программы. Таким образом, имея единственный набор тестовых данных, Avalanche реализует итеративный динамический анализ, при котором программа многократно выполняется на различных, автоматически генерированных тестовых данных, при этом каждый новый запуск увеличивает покрытие кода программы такими тестами.
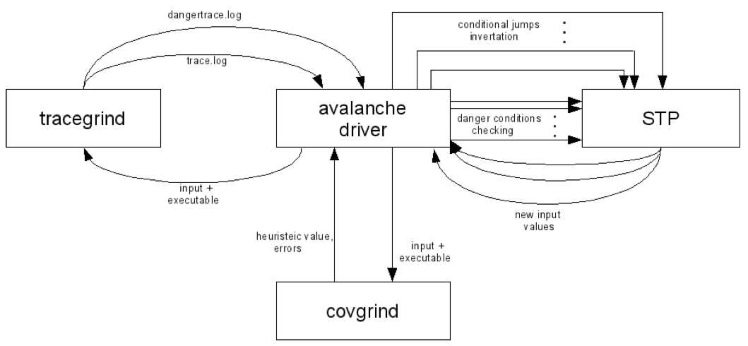
Общая схема работы
Инструмент Avalanche состоит из 4 основных компонент: двух модулей расширения (плагинов) Valgrind – Tracegrind и Covgrind, инструмента проверки выполнимости ограничений STP и управляющего модуля.
Tracegrind динамически отслеживает поток помеченных данных в анализируемой программе и собирает условия для обхода ее непройденных частей и для срабатывания опасных операций. Эти условия при помощи управляющего модуля передаются STP для исследования их выполнимости. Если какое-то из условий выполнимо, то STP определяет те значения всех входящих в условия переменных (в том числе и значения байтов входного файла), которые обращают условие в истину.
- В случае выполнимости условий для срабатывания опасных операций программа запускается управляющим модулем повторно (на этот раз без какой-либо инструментации) с соответствующим входным файлом для подтверждения найденной ошибки.
- Выполнимые условия для обхода непройденных частей программы определяют набор возможных входных файлов для новых запусков программы. Таким образом, после каждого запуска программы инструментом STP автоматически генерируется множество входных файлов для последующих запусков анализа.
- Далее встает задача выбора из этого множества наиболее “интересных” входных данных, т.е. в первую очередь должны обрабатываться входные данные, на которых наиболее вероятно возникновение ошибки. Для решения этой задачи используется эвристическая метрика – количество ранее не обойденных базовых блоков в программе (базовый блок здесь понимается в том смысле, как его определяет фреймворк Valgrind). Для измерения значения эвристики используется компонент Covgrind, в функции которого входит также фиксация возможных ошибок выполнения. Covgrind гораздо более легковесный модуль, нежели Tracegrind, поэтому возможно сравнительно быстрое измерение значения эвристики для всех полученных ранее входных файлов и выбор входного файла с ее наибольшим значением.
Ограничения
- один помеченный входной файл или сокет
- анализ ошибок ограничен разыменованием нулевого указателя и делением на ноль.
Результаты
Эффективность поиска ошибок при помощи Avalanche была исследована на большом числе проектов с открытым исходным кодом.
- qtdump (libquicktime-1.1.3). Три дефекта связаны с разыменованием нулевого указателя, один – с наличием бесконечного цикла, еще в одном случае имеет место обращение по некорректному адресу (ошибка сегментации). Часть дефектов исправлена разработчиком.
- flvdumper (gnash-0.8.6). Непосредственное возникновение дефекта связано с появлением исключительной ситуации в используемой приложением библиотеке boost (один из внутренних указателей библиотеки boost оказывается равен нулю). Поскольку само приложение не перехватывает возникшее исключение, выполнение программы завершается с сигналом SIGABRT. Дефект исправлен разработчиком.
- cjpeg (libjpeg7). Приложение читает из файла нулевое значение и без соответствующей проверки использует его в качестве делителя, что приводит к возникновению исключения плавающей точки и завершению программы с сигналом SIGFPE. Дефект исправлен разработчиком.
- swfdump (swftools-0.9.0). Возникновение обоих дефектов связано с разыменованием нулевого указателя.
KLEE
KLEE несколько отличается от Avalanche тем, что не ищет подозрительные места, а пытается покрыть как можно больше кода и провести исчерпывающий анализ путей в программе. По общей схема KLEE аналогичен Avalanche, но использует другие базовые инструменты для решения задачи, что накладывает свои ограничения и дает свои преимущества.
- Вместо инструментации valgrind’а, которую использует Avalanche, KLEE анализурует программы в llvm-байткоде. Соответственно, это позволяет анализировать программу на любом языке программирования, для которого есть llvm-бэкэнд.
- Для решения задачи булевских ограничений KLEE так же использует STP.
- KLEE так же перехватывает около 50 системных вызовов, позволяя выполняться множеству виртуальных процессов параллельно, не мешая друг другу.
- Оптимизация и кэширование запросов к STP.
KLEE представляет собой символическую виртуальную машину, где параллельно выполняются символические процессы (в рамках терминологии KLEE: states), где каждый процесс представляет собой один из путей в исследуемой программе. Эффективная реализация форков таких процессов (не средствами системы) на каждом ветвлении в программе, позволяет анализировать большое количество путей одновременно.
Для каждого уникального пройденного пути KLEE сохраняет набор входных данных, необходимых для прохождения по этому пути.
Возможности KLEE позволяют с малыми затратами (предоставляется обширный API) проверить эквивалентность любых двух функций (проверка идентичной функциональности по работающему прототипу, рефакторинг) на всем диапазоне заданных входных данных.
Следующий пример иллюстрирует данную функциональность:
unsigned mod_opt(unsigned x, unsigned y) {
if((y & −y) == y) // power of two?
return x & (y−1);
else
return x % y;
}
unsigned mod(unsigned x, unsigned y) {
return x % y;
}
int main() {
unsigned x,y;
make symbolic(&x, sizeof(x));
make symbolic(&y, sizeof(y));
assert(mod(x,y) == mod_opt(x,y));
return 0;
}
Запустив KLEE на данном примере, можно убедится в эквивалентности двух функций во всем диапазоне входных значений (y!=0). Решая задачу на невыполнение условия в ассерте, KLEE на основе перебора всех возможных путей приходит к выводу об эквивалентности двух функций на всем диапазоне значений.
Результаты
Для получения реальных результатов тестирования авторы проанализировали весь набор программ пакета coreutils 6.11. Средней процент покрытия кода составил 94%. Всего программа сгенерировала 3321 набор входных данных, позволяющих покрыть весь указанный процент кода. Так же было найдено 10 уникальных ошибок, которые были признаны разработчиками пакета как реальные дефекты в программах, что является очень хорошим достижением, так как этот набор программ разрабатывается более 20 лет и большинство ошибок было устранено.
Ограничения
- нет поддержки многопоточных приложений, символических данных с плавающей точкой (ограничение STP), ассемблерные вставки.
- тестируемое приложение должно быть собрано в llvm-байт код (так же как и его библиотеки!).
- для эффективного анализа нужно править код.
Предварительные выводы
Безусловно, динамический анализ найдет свою нишу среди инструментов помогающих отдельным программистам и командам программистов решать поставленную задачу, т.к. является эффективным способом нахождения ошибок в программах, а так же доказательством их отсутствия! В в некоторых случаях подобные инструменты просто жизненно необходимы (Mission critical software: RTOS, системы управления производством, авиационное программное обеспечение и так далее).
Заключение
Планируется продолжение тематики статьи (результаты некоторого опыта работы с avalanche и KLEE, а также сравнение KLEE и Avalanche, обзор S2E (https://s2e.epfl.ch) (Selection Symbolic Execution)) при условии положительной обратной связи с читателями Хабра.
Статья содержит фрагменты следующих работ: avalanche_article, KLEE, Применение fuzz-тестирования.
SpiraTeam

SpiraTeam — это комплексное решение для управления жизненным циклом приложений (ALM) со встроенной функцией отслеживания ошибок. Это также один из лучших бесплатных инструментов отслеживания ошибок.
- В нем есть поля инцидентов, которые могут быть полностью настроены, например, статусы, приоритеты, типы дефектов и уровни серьезности.
- SpiraTeam позволяет управлять всем процессом тестирования, от требований до тестов, проблем и вопросов, благодаря встроенной сквозной отслеживаемости.
- Обладает следующими возможностями прямо из коробки:
- Во время выполнения тестового сценария он позволяет автоматически создавать новые инциденты.
- Может связывать происшествия (ошибки) с другими артефактами и инцидентами.
- Отчеты, поиск и сортировка — все это надежные функции, так же как и журнал аудита, отслеживающий изменения.
- Отображаются оповещения по электронной почте, вызванные изменениями состояния рабочего процесса, которые были настроены.
- Есть возможность отправки по электронной почте сообщений о проблемах и ошибках.
BugZilla

BugZilla — известный трекер ошибок. Эти инструменты являются программным обеспечением с открытым исходным кодом и обладают рядом фантастических возможностей, включая такие как:
- Отчеты и графики.
- В комплект входят средства просмотра патчей.
- Дубликаты ошибок автоматически обнаруживаются с помощью этого приложения для отслеживания ошибок.
- Когда в коде происходят изменения, он отправляет вам электронное письмо.
- Список дефектов можно составлять в различных формах. Отчеты следует планировать на ежедневной, ежемесячной и еженедельной основе.
- Клиенты участвуют в определении приоритетов в работе над ошибками.
- Прогнозирует, когда ошибка будет исправлена.
Дебаг и поиск ошибок

Для опытных разработчиков информация статьи может быть очевидной и если вы себя таковым считаете, то лучше добавьте в комментариях полезных советов.
По опыту работы с начинающими разработчиками, я сталкиваюсь с тем, что поиск ошибок порой занимает слишком много времени. Не из-за того, что они глупее более опытных товарищей или не разбираются в процессах, а из-за отсутствия понимания с чего начать и на чём акцентировать внимание. В статье я собрал общие советы о том где обитают ошибки и как найти причину их возникновения. Примеры в статье даны на JavaScript и .NET, но они актуальны и для других платформ с поправкой на специфику.
Какие технологии мы используем в PVS-Studio
Для обеспечения высокого качества результатов статического анализа мы используем передовые методы анализа исходного кода программы и её графа потока управления (control flow graph). Давайте ознакомимся с ними.
Примечание. Далее в качестве примеров будут рассмотрены некоторые диагностики и кратко описаны принципы их работы. Важно отметить, что я сознательно опускаю описание случаев, когда диагностика не должна срабатывать, чтобы не перегружать статью деталями. Это примечание я пишу для тех, кто не сталкивался с разработкой анализаторов: не думайте, что всё так просто, как будет написано ниже. Сделать диагностику — это только 5% работы. Ругаться на подозрительный код не сложно, намного сложнее не ругаться на корректный код. 95% времени при разработке диагностики уходит на обучение анализатора выделять различные приемы программирования, которые хотя и выглядят подозрительно для диагностики, на самом деле корректны.
Pattern-based analysis
Применяется для поиска мест в исходном коде, которые похожи на известные шаблоны кода с ошибкой. Шаблонов очень много, при этом сложность их выявления крайне разнится. Более того, некоторые диагностики для выявления опечаток прибегают к эмпирическим алгоритмам.

Для начала давайте рассмотрим два самых простых случая, выявляемых с помощью паттерного анализа. Первый простой случай:
if ((*path)[0]->e->dest->loop_father != path->last()->e->....)
{
delete_jump_thread_path (path);
e->aux = NULL;
ei_next (&ei;);
}
else
{
delete_jump_thread_path (path);
e->aux = NULL;
ei_next (&ei;);
}Предупреждение PVS-Studio: V523 The ‘then’ statement is equivalent to the ‘else’ statement. tree-ssa-threadupdate.c 2596
В независимости от условия, всегда выполняется один и тот же набор действий. Думаю, здесь всё настолько просто, что не требуются специальные пояснения. Кстати, этот фрагмент кода я встретил не в курсовой работе студента, а в коде компилятора GCC. С результатами проверки компилятора GCC можно ознакомиться в статье «Находим ошибки в коде компилятора GCC с помощью анализатора PVS-Studio«.
Второй простой случай (код взят из проекта FCEUX):
if((t=(char *)realloc(next->name,strlen(name+1))))Предупреждение PVS-Studio: V518 The ‘realloc’ function allocates strange amount of memory calculated by ‘strlen(expr)’. Perhaps the correct variant is ‘strlen(expr) + 1’. fceux cheat.cpp 609
Анализируется следующий ошибочный паттерн. Программисты знают, что когда они выделяют память для хранения строки, то должны дополнительно выделить память для одного символа, где будет храниться признак конца строки (терминальный ноль). Другими словами, программисты знают, что должны обязательно дописать +1 или +sizeof(TCHAR). Но делают это иногда небрежно. В результате они прибавляют 1 не к значению, которое возвращает функция strlen, а к указателю.
Именно так и произошло в нашем случае. Вместо strlen(name+1) должно быть написано strlen(name)+1.
Из-за такой ошибки памяти выделяется чуть меньше, чем требуется. Далее произойдет выход за границу выделенного буфера и последствия будут непредсказуемы. Более того, программа может делать вид что корректно работает, если благодаря везению два байта после выделенного буфера не используются. При ещё более плохом сценарии, такой дефект может давать наведённые ошибки, которые будут проявлять себя совсем в другом месте.
Теперь рассмотрим анализ среднего уровня сложности.
Диагностика формулируется так: предупреждаем, если после использования оператора as на null проверяется исходный объект вместо результата оператора as.
Рассмотрим фрагмент кода из проекта CodeContracts:
public override Predicate JoinWith(Predicate other)
{
var right = other as PredicateNullness;
if (other != null)
{
if (this.value == right.value)
{Предупреждение PVS-Studio: V3019 Possibly an incorrect variable is compared to null after type conversion using ‘as’ keyword. Check variables ‘other’, ‘right’. CallerInvariant.cs 189
Обратите внимание, что на равенство null проверяется переменная other, а вовсе не right. Это явная ошибка, ведь потом работают именно с переменной right.
И под конец — сложный паттерн, связанный с использование макросов.
Макрос разворачивается так, что приоритет операции внутри макроса выше приоритета операции вне макроса. Пример:
#define RShift(a) a >> 3
....
RShift(a & 0xFFF) // a & 0xFFF >> 3Для разрешения проблемы нужно поместить в макросе аргумент a в скобки (а лучше и весь макрос тоже в скобки), то есть написать так:
#define RShift(a) ((a) >> 3),Тогда макрос корректно развернётся в:
RShift(a & 0xFFF) // ((a & 0xFFF) >> 3)Описание паттерна выглядит простым, но на практике реализация диагностики весьма сложна. Недостаточно анализировать только «#define RShift(a) a >> 3». Если выдавать предупреждения на все такие строки, будет слишком много срабатываний. Надо смотреть, как макрос раскрывается в конкретном случае, и пытаться отделить ситуации, когда это специальная задумка, а когда действительно не хватает скобок.
Рассмотрим эту ошибку на примере кода реального проекта FreeBSD:
#define ICB2400_VPINFO_PORT_OFF(chan) \
(ICB2400_VPINFO_OFF + \
sizeof (isp_icb_2400_vpinfo_t) + \
(chan * ICB2400_VPOPT_WRITE_SIZE))
....
off += ICB2400_VPINFO_PORT_OFF(chan - 1);Предупреждение PVS-Studio: V733 It is possible that macro expansion resulted in incorrect evaluation order. Check expression: chan — 1 * 20. isp.c 2301
Type inference
Вывод типов на основе семантической модели программы позволяет анализатору иметь полную информацию о всех переменных и выражениях, встречающихся в коде.

Другими словами, анализатор должен знать, является токен Foo именем переменной, названием класса или функцией. Анализатор во многом повторяет работу компилятора, которому также требуется точно знать тип того или иного объекта и всю сопутствующую информацию о типе: размер, знаковый/беззнаковый тип, если класс, то от кого он наследуется и так далее.
Именно по этой причине анализатор PVS-Studio требует препроцессировать *.c/*.cpp файлы. Только анализируя препроцессированный файл можно собрать всю информацию о типах. Без такой информации многие диагностики осуществлять невозможно, или они будут давать много ложных срабатываний.
Примечание. Если кто-то заявляет, что их анализатор умеет проверять *.c/*.cpp файлы как текстовый документ, без полноценного препроцессирования, то знайте, это просто баловство. Да, такой анализатор может что-то находить, но в целом — это несерьезная игрушка.
Итак, информация о типах нужна как для выявления ошибок, так и для того, чтобы, наоборот, не выдавать ложные предупреждения. Особенно важна информация о классах.
Давайте рассмотрим на примерах, как используется информация о типах.
Первый пример демонстрирует, что информация о типе нужна, чтобы выявить ошибку при работе с функцией fprintf (код взят из проекта Cocos2d-x):
WCHAR *gai_strerrorW(int ecode);
....
#define gai_strerror gai_strerrorW
....
fprintf(stderr, "net_listen error for %s: %s",
serv, gai_strerror(n));Предупреждение PVS-Studio: V576 Incorrect format. Consider checking the fourth actual argument of the ‘fprintf’ function. The pointer to string of char type symbols is expected. ccconsole.cpp 341
Функция frintf ожидает в качестве четвертого аргумента указатель типа char *. Случайно получилась так, что фактическим аргументом является строка типа wchar_t *.
Чтобы выявить эту ошибку надо знать тип, который возвращает функция gai_strerrorW. Если этой информации не будет, то и выявить ошибку не представляется возможным.
Теперь рассмотрим пример, когда знание информации о типе препятствует выдаче ложного предупреждения.
Код вида «*A = *A;» однозначно считается анализатором подозрительным. Однако, анализатор промолчит, если встретит следующую ситуацию:
volatile char *ptr;
....
*ptr = *ptr; // <= Нет срабатывания V570Спецификатор volatile подсказывает, что это не ошибка, а специальная задумка программиста. Разработчику зачем-то надо «потрогать» ячейку памяти. Зачем ему это нужно — мы не знаем, но раз он так делает, то в этом есть смысл и выдавать предупреждение не следует.
Теперь давайте рассмотрим пример, как можно выявлять ошибку, основываясь на знаниях о классе.
Пример кода взят из проекта CoreCLR:
struct GCStatistics : public StatisticsBase {
....
virtual void Initialize();
virtual void DisplayAndUpdate();
....
GCStatistics g_LastGCStatistics;
....
memcpy(&g_LastGCStatistics, this, sizeof(g_LastGCStatistics));Предупреждение PVS-Studio: V598 The ‘memcpy’ function is used to copy the fields of ‘GCStatistics’ class. Virtual table pointer will be damaged by this. cee_wks gc.cpp 287.
Копировать один объект в другой с помощью функции memcpy вполне допустимо, если объекты являются POD-структурами. Однако здесь в классе присутствуют виртуальные методы, а значит имеется и указатель на таблицу виртуальных методов. Копировать этот указатель из одного объекта в другой крайне опасно.
Итак, диагностика стала возможна благодаря тому, что мы знаем, что переменная g_LastGCStatistics — это экземпляр класса, и что этот класс не является POD-типом.
Symbolic execution
Символьное выполнение позволяет вычислять значения переменных, которые могут приводить к ошибкам, производить проверку диапазонов (range checking) значений. В наших статьях мы иногда называем это механизмом вычисления виртуальных значений: см., например, статью «Поиск ошибок с помощью вычисления виртуальных значений«.

Зная предполагаемые значения переменных, можно выявлять такие ошибки как:
- утечки памяти;
- переполнения;
- выход за границу массива;
- разыменование нулевых указателей в C++ / доступ по нулевой ссылке в C#;
- бессмысленные условия;
- деление на 0;
- и так далее.
Рассмотрим, как используя знания о возможных значениях переменных можно находить различные ошибки. Начнём с фрагмента кода, взятого из проекта QuantLib:
Handle md0Yts() {
double q6mh[] = {
0.0001,0.0001,0.0001,0.0003,0.00055,0.0009,0.0014,0.0019,
0.0025,0.0031,0.00325,0.00313,0.0031,0.00307,0.00309,
........................................................
0.02336,0.02407,0.0245 }; // 60 элементов
....
for(int i=0;i<10+18+37;i++) { // i < 65
q6m.push_back(
boost::shared_ptr(new SimpleQuote(q6mh[i])));
Предупреждение PVS-Studio: V557 Array overrun is possible. The value of ‘i’ index could reach 64. markovfunctional.cpp 176
Здесь анализатор знает следующие данные:
- массив q6mh содержит 60 элементов;
- счетчик массива i будет принимать значения [0..64].
Теперь рассмотрим ситуацию, где может возникнуть деление на 0. Код взят из проекта Thunderbird:
static inline size_t UnboxedTypeSize(JSValueType type)
{
switch (type) {
.......
default: return 0;
}
}
Minstruction *loadUnboxedProperty(size_t offset, ....)
{
size_t index = offset / UnboxedTypeSize(unboxedType);Функция UnboxedTypeSize возвращает различные значения, в том числе и 0. Не проверяя, что результат работы функции может быть 0, её используют как знаменатель. Потенциально это может привести к делению переменной offset на 0.
Предыдущие примеры касались диапазона целочисленных значений. Однако, анализатор оперирует и со значениями других типов данных, например, со строками и указателями.
Рассмотрим пример неправильной работы со строками. В данном случае анализатор хранит информацию о том, что вся строка была преобразована в верхний или нижний регистр. Это позволяет выявлять следующие ситуации:
string lowerValue = value.ToLower();
....
bool insensitiveOverride = lowerValue == lowerValue.ToUpper();Предупреждение PVS-Studio: V3122 The ‘lowerValue’ lowercase string is compared with the ‘lowerValue.ToUpper()’ uppercase string. ServerModeCore.cs 2208
Программист хотел проверить, что все символы в строке являются заглавными. Код явно содержит какую-то логическую ошибку, так как ранее все символы этой строки были преобразованы в нижний регистр.
Продолжать описывать диагностики, построенные на знаниях о значении переменных, можно долго. Я приведу только ещё один пример, связанный с указателями и утечкой памяти.
Код взят из проекта WinMerge:
CMainFrame* pMainFrame = new CMainFrame;
if (!pMainFrame->LoadFrame(IDR_MAINFRAME))
{
if (hMutex)
{
ReleaseMutex(hMutex);
CloseHandle(hMutex);
}
return FALSE;
}
m_pMainWnd = pMainFrame;Предупреждение анализатора: V773 The function was exited without releasing the ‘pMainFrame’ pointer. A memory leak is possible. Merge merge.cpp 353
Если не удалось загрузить фрейм, то функция завершает свою работу. При этом не разрушается объект, указатель на который хранится в переменной pMainFrame.
Диагностика работает следующим образом. Анализатор запоминает, что указатель pMainFrame хранит адрес объекта, созданного с помощью оператора new. Анализируя граф потока управления, анализатор встречает оператор return. При этом объект не разрушался и указатель продолжает ссылаться на созданный объект. Это значит, что в этой точке возникает утечка памяти.
Method annotations
Аннотирование методов предоставляет больше информации об используемых методах, чем может быть получено путём анализа только их сигнатуры.

Мы проделали большую работу по аннотированию функций:
- C/C++. На данный момент проаннотировано 6570 функций (стандартные библиотеки C и C++, POSIX, MFC, Qt, ZLib и так далее).
- C#. На данный момент проаннотировано 920 функций.
Рассмотрим, как в ядре C++ анализатора проаннотирована функция memcmp:
C_"int memcmp(const void *buf1, const void *buf2, size_t count);"
ADD(REENTERABLE | RET_USE | F_MEMCMP | STRCMP | HARD_TEST |
INT_STATUS, nullptr, nullptr, "memcmp",
POINTER_1, POINTER_2, BYTE_COUNT);Краткие пояснения по разметке:
- C_ — вспомогательный механизм контроля аннотаций (юнит-тесты);
- REENTERABLE – повторный вызов с теми же аргументами даст тот же результат;
- RET_USE – результат должен быть использован;
- F_MEMCMP – запуск определённых проверок выхода за границы буфера;
- STR_CMP – при равенстве функция возвращает 0;
- HARD_TEST – особая функция: некоторые библиотеки определяют собственные идентичные функции в своих namespace и поэтому следует игнорировать namespace;
- INT_STATUS – результат нельзя явно сравнивать с 1 или -1;
- POINTER_1, POINTER_2 – указатели должны быть не нулевыми и разными;
- BYTE_COUNT – параметр задает количество байт и должен быть больше 0.
Данные аннотации используются многими диагностиками. Рассмотрим некоторые ошибки, которые мы обнаружили в коде приложений благодаря приведенной выше разметке для функции memcmp.
Пример использования разметки INT_STATUS. Проект CoreCLR:
bool operator()(const GUID& _Key1, const GUID& _Key2) const
{
return memcmp(&_Key1, &_Key2, sizeof(GUID)) == -1;
}Такой код может работать, но в целом он неверен. Функция memcmp возвращает значения 0, больше нуля и меньше нуля. Важно:
- «больше нуля», это не обязательно 1
- «меньше нуля», это не обязательно -1
Таким образом, нет никакой гарантии в работоспособности написанного кода. В любой момент сравнение может начать работать неправильно. Это может произойти при смене компилятора, изменении настроек оптимизации и так далее.
Флаг INT_STATUS помогает выявить ещё один вид ошибки. Код проекта Firebird:
SSHORT TextType::compare(ULONG len1, const UCHAR* str1,
ULONG len2, const UCHAR* str2)
{
....
SSHORT cmp = memcmp(str1, str2, MIN(len1, len2));
if (cmp == 0)
cmp = (len1 < len2 ? -1 : (len1 > len2 ? 1 : 0));
return cmp;
}PVS-Studio. V642 Saving the ‘memcmp’ function result inside the ‘short’ type variable is inappropriate. The significant bits could be lost breaking the program’s logic. texttype.cpp 3
Вновь неаккуратно работают с результатом, который возвращает функция memcmp. Ошибка в том, что происходит усечение размера типа: результат помещают в переменную типа short.
Некоторые могут подумать, что мы придираемся. Ничуть. Такой неаккуратный код может легко стать причиной самой настоящей уязвимости.
Одна такая ошибка послужила причиной серьезной уязвимости в MySQL/MariaDB до версий 5.1.61, 5.2.11, 5.3.5, 5.5.22. Причиной стал следующий код в файле ‘sql/password.c’:
typedef char my_bool;
....
my_bool check(...) {
return memcmp(...);
}Пример использования разметки BYTE_COUNT. Проект GLG3D:
bool Matrix4::operator==(const Matrix4& other) const {
if (memcmp(this, &other, sizeof(Matrix4) == 0)) {
return true;
}
....
}Предупреждение PVS-Studio: V575 The ‘memcmp’ function processes ‘0’ elements. Inspect the ‘third’ argument. graphics3D matrix4.cpp 269
Третий аргумент функции memcmp помечен как BYTE_COUNT. Считается, что такой аргумент не должен быть равен 0. В приведённом фрагменте кода третий фактический параметр как раз равен 0.
Ошибка заключается в том, что не там поставлена скобка. В результате третьим аргументом является выражение sizeof(Matrix4) == 0. Результат этого выражения false, т.е. 0.
Пример использования разметки POINTER_1 и POINTER_2. Проект GDB:
static int
psymbol_compare (const void *addr1, const void *addr2,
int length)
{
struct partial_symbol *sym1 = (struct partial_symbol *) addr1;
struct partial_symbol *sym2 = (struct partial_symbol *) addr2;
return (memcmp (&sym1->ginfo.value, &sym1->ginfo.value,
sizeof (sym1->ginfo.value)) == 0
&& .......Предупреждение PVS-Studio: V549 The first argument of ‘memcmp’ function is equal to the second argument. psymtab.c 1580
Первый и второй аргументы размечены как PONTER_1 и POINTER_2. Во-первых, это означает, что они не должны быть равны NULL. Но в данном случае нам интересно второе свойство разметки: эти указатели не должны совпадать, о чем говорят суффиксы _1 и _2.
Из-за опечатки в коде буфер &sym1->ginfo.value сравнивается сам с собой. PVS-Studio, опираясь на разметку, легко обнаруживает эту ошибку.
Пример использования разметки F_MEMCMP.
Данная разметка включает ряд специальных диагностик для таких функций, как memcmp и __builtin_memcmp. В результате может быть выявлена вот такая ошибка в проекте Haiku:
dst_s_read_private_key_file(....)
{
....
if (memcmp(in_buff, "Private-key-format: v", 20) != 0)
goto fail;
....
}Предупреждение PVS-Studio: V512 A call of the ‘memcmp’ function will lead to underflow of the buffer ‘«Private-key-format: v»’. dst_api.c 858
Строка «Private-key-format: v» состоит из 21 символа, а не из 20. Таким образом, сравнивается меньше байт чем требуется.
Пример использования разметки REENTERABLE. Если честно, слово «reenterable» не совсем верно отражает суть данного флага. Однако, все разработчики в нашей команде к нему привыкли и не хочется делать изменений в коде ради красоты.
Суть разметки в следующем. Функция не имеет состояния и никаких побочных эффектов: не меняет память, не печатает что-то на экран, не удаляет файлы на диске. Благодаря этому анализатор может отличать правильные конструкции от неправильных. Например, вот такой код вполне законен:
if (fprintf(f, "1") == 1 && fprintf(f, "1") == 1)Анализатор не будет выдавать предупреждений. Мы записываем две единицы в файл и код нельзя сократить до:
if (fprintf(f, "1") == 1) // неправильноА вот такой код избыточен и насторожит анализатор, так как функция cosf не имеет состояния и никуда ничего не записывает:
if (cosf(a) > 0.1f && cosf(a) > 0.1f)Вернемся теперь к функции memcmp и посмотрим, какую ошибку удалось обнаружить с помощью рассмотренной разметки в проекте PHP:
if ((len == 4) /* sizeof (none|auto|pass) */ &&
(!memcmp("pass", charset_hint, 4) ||
!memcmp("auto", charset_hint, 4) ||
!memcmp("auto", charset_hint, 4)))Как видите, с помощью разметки можно находить много интересных ошибок. Часто анализаторы предоставляют возможности пользователям самостоятельно аннотировать функции. В PVS-Studio эти возможности развиты слабо. В нем есть всего несколько диагностик, для которых можно что-то проаннотировать. Например, это диагностика V576 для поиска ошибок использования функций форматного вывода (printf, sprintf, wprintf и так далее).
Мы сознательно не развиваем механизм пользовательских аннотаций. На это есть две причины:
- В большом проекте никто не станет тратить время на разметку функций. Это просто нереально, когда у вас 10 миллионов строк кода, а ведь анализатор PVS-Studio как раз ориентирован на средние и большие проекты.
- Если не размечены функции из какой-то известной библиотеки, то лучше написать нам и мы сами проаннотируем их. Во-первых, мы сделаем это быстрее и лучше, а во-вторых, результаты разметки станут доступны всем нашим пользователям.
Lighthouse

Lighthouse — один из лучших бесплатных инструментов отслеживания ошибок и веб-трекер проблем.
- Он прост, хорошо структурирован и удобен для мобильных устройств.
- Он также интегрируется с рядом полезных сторонних сервисов, таких как Airbrake, Github, Exceptional, Beanstalk и другими.
- Всего несколькими щелчками мыши вы можете начать управлять проблемами с помощью сообщений фиксации или превратить исключения приложений в проблемы маяков.
- Lighthouse также позволяет сохранить проектный документ в режиме онлайн сразу же из пользовательского интерфейса, что является ценным инструментом.
- Lighthouse предоставляет все инструменты, необходимые для управления этой проблемой, включая настраиваемые состояния, отличную систему тегов, сложный поиск, поиск по магазинам и инструмент массового редактирования.
- Это коммерческий продукт, но Lighthouse предлагает бесплатную пробную версию.
Kualitee

Kualitee предназначен для команд разработчиков и специалистов по обеспечению качества, которые хотят делать больше, чем просто назначать и отслеживать проблемы.
- Помогает создавать высококачественное программное обеспечение, уменьшая количество проблем, ускоряя циклы QA и обеспечивая больший контроль над сборками.
- Разрешения, поля и отчеты можно настраивать.
- Полный пакет, включающий все возможности комплексной системы управления дефектами, легко интегрирует тестовые случаи и методы выполнения тестов.
- Вам не придется переключаться между множеством инструментов; вместо этого вы сможете проводить все свои тесты в одном месте.
- Способен создавать, назначать и отслеживать дефекты.
- Предлагает простой и удобный в использовании пользовательский интерфейс.
- Его стоимость составляет от 15 долларов США в месяц на одного пользователя. Через Kualitee также доступна бесплатная 7-дневная пробная версия.
- Между проблемами, требованиями и тестами существует взаимосвязь.
- Дефекты, тестовые случаи и циклы тестирования можно использовать повторно.
- Предлагает приборную панель, которая является одновременно интерактивной и обучающей.
- Имеет REST API и интерфейсы сторонних производителей.