
Даже если вы за компьютером ничего не делаете — в процессе работы ОС Windows записывает часть данных в спец. документы (их еще называют логами или системными журналами). Как правило, под-запись попадают различные события, например, включение/выключение ПК, возникновение ошибок, обновления и т.д. 👀
В общем, в этой заметке покажу азы работы с журналами событий в Windows (например, как найти ошибку и ее код, что несомненно поможет в диагностике).
Введение
Встроенный в Python модуль логирования разработан для того, чтобы дать вам детальное представление о приложениях с минимальными настройками. Начинаете ли вы работу или уже работаете, в руководстве вы увидите, как настроить этот модуль, чтобы помочь найти нужную строку кода.
В этом посте мы покажем вам, как:
Всем привет, тема стать как посмотреть логи windows. Что такое логи думаю знают все, но если вдруг вы новичок, то логи это системные события происходящие в операционной системе как Windows так и Linux, которые помогают отследить, что, где и когда происходило и кто это сделал. Любой системный администратор обязан уметь читать логи windows.
Примером из жизни может служить ситуация когда на одном из серверов IBM, выходил из строя диск и для технической поддержки я собирал логи сервера, для того чтобы они могли диагностировать проблему. За собирание и фиксирование логов в Windows отвечает служба Просмотр событий. Просмотр событий это удобная оснастка для получения логов системы.
Основы
У basicConfig() три основных параметра:
В следующем разделе мы покажем, как настроить его, чтобы включить метки времени и другую полезную информацию.
Поскольку по умолчанию пишутся только журналы WARNING и более высокого уровня, вам может не хватать логов с низким приоритетом. Кроме того, вместо StreamHandler или SocketHandler для потоковой передачи непосредственно на консоль или во внешнюю службу по сети, вам лучше использовать FileHandler, чтобы писать в один или несколько файлов на диске.
Если при передаче по сети возникнут проблемы, то у вас не будет свободного доступа к этим логам: они будут храниться на каждом сервере локально. Логирование в файл позволяет создавать разные типы логов и объединять их службой мониторинга.
Работа с журналом событий (для начинающих)
Как его открыть
Этот вариант универсальный и работает во всех современных версиях ОС Windows.
Актуально для пользователей Windows 10/11.
1) Нажать по значку с «лупой» на панели задач, в поисковую строку написать «событий» и в результатах поиска ОС Windows предоставит вам ссылку на журнал (см. скрин ниже). 👇

Windows 10 — события
2) Еще один способ: нажать сочетание — появится меню со ссылками на основные инструменты, среди которых будет и журнал событий.
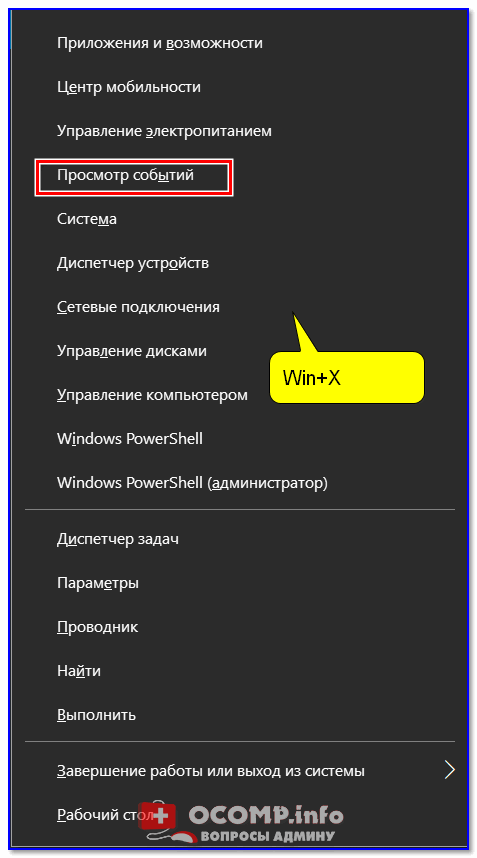
Win+X — вызов меню
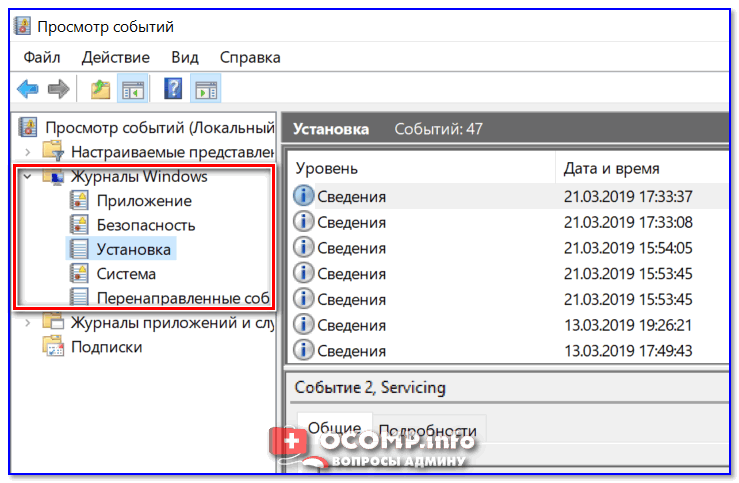
Наибольшую пользу (по крайней мере, для начинающих пользователей) представляет раздел (выделен на скрине выше). Довольно часто при различных неполадках приходится изучать как раз его.
В нем есть 5 вкладок, из которых 3 основных: «Приложение», «Безопасность», «Система». Именно о них пару слов подробнее:
Как найти и просмотреть ошибки (в т.ч. критические)
Надо сказать, что Windows записывает в журналы очень много различной информации (вы в этом можете убедиться, открыв любой из них). Среди стольких записей найти нужную ошибку не так просто. И именно для этого здесь предусмотрены спец. фильтры. Ниже покажу простой пример их использования.
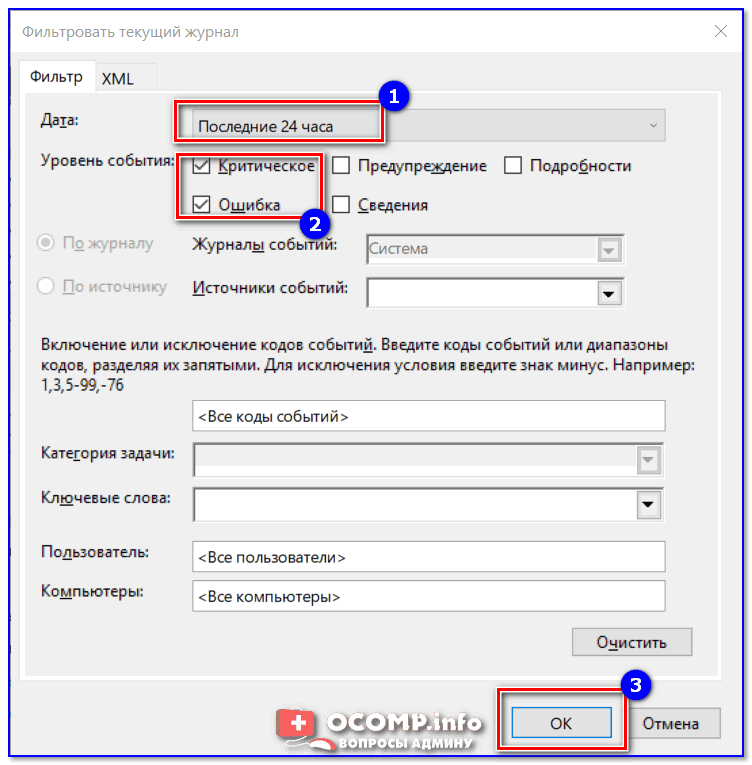
И так, сначала необходимо выбрать нужный журнал, далее кликнуть в правой колонке по инструменту «Фильтр текущего журнала».
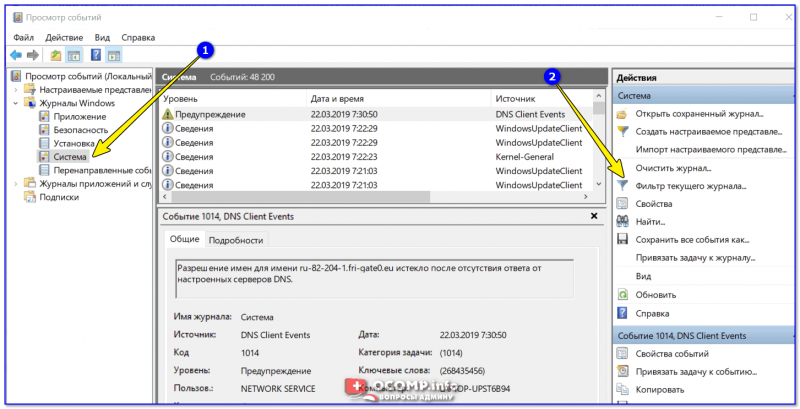
Система — фильтр текущего журнала / Кликабельно
После указать дату, уровень события (например, ошибки), и нажать OK.
В результате вы увидите отфильтрованный список событий. Ориентируясь по дате и времени вы можете найти именно ту ошибку, которая вас интересует.
Например, на своем подопытном компьютере я нашел ошибку из-за которой он перезагрузился (благодаря коду ошибки и ее подробному описанию — можно найти решение на сайте Microsoft).
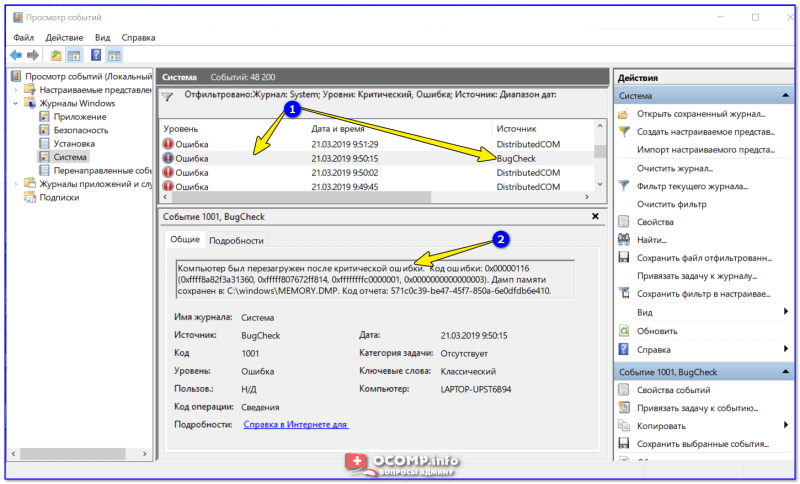
Представлены все ошибки по дате и времени их возникновения / Кликабельно
Т.е. как видите из примера — использование журнала событий очень даже помогает в решении самых разных проблем с ПК.
Можно ли отключить журналы событий
Можно! Только нужно ли? (хотя не могу не отметить, что многие считают, что на этом можно сэкономить толику дискового пространства, плюс система более отзывчива и меньше нагрузка на жесткий диск)
Для отключения журналов событий нужно:
На этом пока всё, удачи!

Если Вы хотя бы немного знакомы с программированием и пробовали запускать что-то «в продакшен», то вам наверняка станет больно от такого диалога:
— Вась, у нас там приложение слегло. Посмотри, что случилось?
Да, у Василия, судя по всему, не настроено логирование. И это ужасно, хотя бы по нескольким причинам:
Впрочем, последний пункт, наверно, лишний. Однако, одну вещь мы поняли наверняка:
Логирование — крайне важная штука в программировании.
В языке Python основным инструментом для логирования является библиотека logging. Так давайте вместе с IT Resume рассмотрим её подробней.
Что такое logging?
Модуль logging в Python — это набор функций и классов, которые позволяют регистрировать события, происходящие во время работы кода. Этот модуль входит в стандартную библиотеку, поэтому для его использования достаточно написать лишь одну строку:
Основная функция, которая пригодится Вам для работы с этим модулем — basicConfig(). В ней Вы будете указывать все основные настройки (по крайней мере, на базовом уровне).
У функции basicConfig() 3 основных параметра:
Давайте рассмотрим каждый из параметров более подробно.
Соответственно, чтобы не засорять логи лишней информацией, в basicConfig() Вы можете указать минимальный уровень фиксируемых событий.
По умолчанию фиксируются только предупреждения (WARNINGS) и события с более высоким приоритетом: ошибки (ERRORS) и критические ошибки (CRITICALS).
А далее, чтобы записать информационное сообщение (или вывести его в консоль, об этом поговорим чуть позже), достаточно написать такой код:
logging.debug(‘debug message’)
logging.info(‘info message’)
И так далее. Теперь давайте обсудим, куда наши сообщения попадают.
Отображение лога и запись в файл
За место, в которое попадают логи, отвечает параметр filename в basicConfig. По умолчанию все Ваши логи будут улетать в консоль.
Другими словами, если Вы просто выполните такой код:
То сообщение WOW придёт Вам в консоль. Понятно, что в консоли никому эти сообщения не нужны. Как же тогда направить запись лога в файл? Очень просто:
logging.basicConfig(filename = «mylog.log»)
Ок, с записью в файл и выбором уровня логирования все более-менее понятно. А как настроить свой шаблон? Разберёмся.
Кстати, мы собрали для Вас сублимированную шпаргалку по логированию на Python в виде карточек. У нас ещё много полезностей, не пожалеете 🙂
Форматирование лога
Итак, последнее, с чем нам нужно разобраться — форматирование лога. Эта опция позволяет Вам дополнять лог полезной информацией — датой, названием файла с ошибкой, номером строки, названием метода и так далее.
Сделать это можно, как все уже догадались, с помощью параметра format.
Например, если внутри basicConfig указать:
format = «%(asctime)s — %(levelname)s — %(funcName)s: %(lineno)d — %(message)s»
То вывод ошибки будет выглядеть так:
Вы можете сами выбирать, какую информацию включить в лог, а какую оставить. По умолчанию формат такой:
Важно помнить, что все параметры logging.basicConfig должны передаваться до первого вызова функций логирования.
Эпилог
Что же, мы разобрали все основные параметры модуля logging и функции basicConfig, которые позволят Вам настроить базовое логирование в Вашем проекте. Дальше — только практика и набивание шишек 🙂
Вместо заключения просто оставим здесь рабочий кусочек кода, который можно использовать 🙂
import logging
logging.basicConfig(
level=logging.DEBUG,
filename = «mylog.log»,
format = «%(asctime)s — %(module)s — %(levelname)s — %(funcName)s: %(lineno)d — %(message)s»,
datefmt=’%H:%M:%S’,
)
logging.info(‘Hello’)
Если хотите разобраться с параметрами более подробно, Вам поможет официальная документация (очень неплохая, кстати).

техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
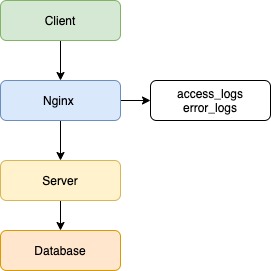
Логи доступны 2 типов:
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Фильтрация в просмотре событий
Предположим у вас в журнале Безопасность более миллиона событий, наверняка вы сразу зададите вопрос есть ли фильтрация, так как просматривать все из них это мазохизм. В просмотре событий это предусмотрели, логи windows можно удобно отсеять оставив только нужное. Справа в области Действия есть кнопка Фильтр текущего журнала.
Вас попросят указать уровень событий:
Все зависит от задачи поиска, если вы ищите ошибки, то смысла в других типах сообщение нету. Далее можете для того чтобы сузить границы поиска просмотра событий укзать нужный источник событий и код.
Так что как видите разобрать логи windows очень просто, ищем, находим, решаем. Так же может быть полезным быстрая очистка логов windows:
Сколько должно быть логов?
Существует очевидное соотношение между объемом логов и их полезностью. Чем более содержательные логи, тем легче реконструировать переходы состояний. Вы можете воспользоваться двумя способами контроля количества логов:
Логирование в JSON
Со временем поиск лога станет сложной задачей, особенно если логи распределены между серверами, сервисами и файлами. Если вы централизовали логи с помощью, то будете знать, где искать, а не входить вручную на каждый сервер.
JSON — лучшая практика для централизации с помощью сервиса управления: компьютеры легко анализируют этот стандартный структурированный формат. В JSON логах легко обращаться с атрибутами: не нужно обновлять конвейеры обработки при их добавлении или удалении.
Сообщество Python разработало библиотеки, конвертирующие логи в JSON. Используем python-json-logger. Установка:
pip install python-json-logger
Консольные логи по-прежнему соответствуют simpleFormatter для удобства чтения, но логи, созданные логгером lowermodule, теперь пишутся в JSON.
При включении pythonjsonlogger.jsonlogger.JsonFormatter в конфигурацию функция fileConfig() должна иметь возможность создавать JsonFormatter, пока выполняется код из среды, где импортируется pythonjsonlogger.
Если вы не используете файловую конфигурацию, нужно импортировать python-json-logger, а также определить обработчик и модуль форматирования, как описано в документации:
from pythonjsonlogger import jsonloggerlogger = logging.getLogger()logHandler = logging.StreamHandler()formatter = jsonlogger.JsonFormatter()logHandler.setFormatter(formatter)logger.addHandler(logHandler)
Почему JSON предпочтительнее, особенно когда речь идёт о сложных или подробных записях? Вернёмся к примеру многострочной трассировки:
Этот лог легко читать в файле или в консоли. Но если он обрабатывается платформой управления и правила многострочного агрегирования не настроены, то каждая строка может отображаться как отдельный лог. Это затруднит точное восстановление событий. Теперь, когда мы логируем трассировку исключений в JSON, приложение создаёт единый журнал:
Сервис логирования может легко интерпретировать этот JSON и показать всю информацию о трассировке, включая exc_info:
Используйте уровни логов
Что, если X все еще слишком большой даже после оптимизации? На помощь приходят уровни логов. Если X намного больше, чем 1, то можно поместить логи на уровень DEBUG, тем самым снизив X уровня INFO. В процессе устранения неполадок программа может временно выполняться на этом уровне для предоставления дополнительной информации.
Базовый пример
В следующем примере используется basicConfig(), чтобы сконфигурировать приложение для логирования DEBUG и выше на диск, и указывается на наличие даты, времени и серьёзности в строке лога:
import loggingdef word_count(myfile): logging.basicConfig(level=logging.DEBUG, filename=’myapp.log’, format=’%(asctime)s %(levelname)s:%(message)s’) try: # считаем слова, логируем результат. with open(myfile, ‘r’) as f: file_data = f.read() words = file_data.split(» «) num_words = len(words) logging.debug(«this file has %d words», num_words) return num_words except OSError as e: logging.error(«error reading the file»)
Если на входе будет недоступный файл, в лог запишется это:
2019-03-27 10:49:00,979 DEBUG:this file has 44 words2019-03-27 10:49:00,979 ERROR:error reading the file
Благодаря новой конфигурации сообщения отладки не фильтруются и, кроме сообщения об ошибке, дают информацию о дате, местном времени и уровне важности:
Здесь информация о стандартных атрибутах. В примере выше логирование не включает трассировку, затрудняя определение источника проблемы. Ниже мы покажем логирование трассировки исключений.
Отладка
Отладка — это мысленная реконструкция переходов состояний. Разработчики проигрывают в уме сценарий программы: как она принимает вводные данные, проходит через ряд изменений состояний и осуществляет вывод, а затем определяют, что пошло не так. Во время разработки этот мыслительный процесс подкрепляется использованием отладчика. Однако в продакшене делать это уже гораздо сложнее, поэтому на данном этапе чаще прибегают к помощи логов.
Установите соотношение между логами и рабочей нагрузкой
Для контроля объема логов сначала важно его правильно измерить. Большинство программ имеют 2 типа рабочей нагрузки:
В большинстве случаев процесс логирования запускается рабочей нагрузкой: чем больше ее у программы, тем больше логов она записывает. Могут быть и другие логи, не связанные с рабочей нагрузкой, но они становятся малозначимыми, когда программа начинает работу. Разработчики должны сохранять соотношение # логов и # рабочих элементов линейным. Иначе говоря:
# логов = X * # рабочих элементов+ константы
где X можно определить, изучив код. Разработчики должны иметь хорошее представление об X-факторах для своих программ и приводить их в соответствие с возможностями логирования и бюджетом. Вот еще несколько типичных случаев X:
Что записывать в лог ?
Понимая суть процесса отладки, мы с легкостью ответим на этот вопрос:
Логи должны содержать информацию, необходимую для реконструкции переходов состояний.
Невозможно, да и не нужно, фиксировать все состояния во все отрезки времени. Например, полиции достаточно лишь нескольких точных набросков, а не видеоклона, для поимки преступника. Тоже самое относится и к логам: разработчикам нужно только внести в них информацию о том, когда происходит переход в критическое состояние. Кроме того, логи должны содержать ключевые характеристики текущего состояния и причину перехода.
FileConfig
fileConfig и dictConfig позволяют реализовать более гибкое логирование на основе файлов или словаря. Оно используется в Django и Flask. В файле конфигурации должны быть три секции:
Документация рекомендует прикреплять каждый обработчик к одному логу, прописывать основные настройки в корневом (root) логе и уточнять их в дочерних, а не дублировать одно и то же в дочерних логах. Подробнее в документации. В этом примере мы указали в root настройки для обоих логов, что избавило нас от дублирования кода.
Вместо logging.basicConfig(level=logging.DEBUG, format=’%(asctime)s %(name)s %(levelname)s:%(message)s’) в каждом модуле мы можем сделать так:
import logging.configlogging.config.fileConfig(‘/path/to/logging.ini’, disable_existing_loggers=False)logger = logging.getLogger(__name__)
Этот код отключает существующие не корневые логгеры, включенные по умолчанию. Не забудьте импортировать logging.config. Кроме того, посмотрите в документацию логирования на основе словаря.
Пользовательские атрибуты
Еще одно преимущество — добавления атрибутов, анализируемых внешним сервисом управления автоматически. Ранее мы настроили formatдля стандартных атрибутов. Можно логировать пользовательские атрибуты, используя поле python-json-logs. Ниже мы создали атрибут, отслеживающий продолжительность операции в секундах:
# lowermodule.pyimport logging.configimport tracebackimport time
В системе управления атрибуты анализируются так:
Если вы используете платформу мониторинга, то можете построить график и предупредить о большом run_duration. Вы также можете экспортировать этот график на панель мониторинга, когда захотите визуализировать его рядом с производительностью:
Используете вы python-json-logger или другую библиотеку для форматирования, вы можете легко настроить логи для включения информации, анализируемой внешней платформой управления.
Программа как уровни абстракции
Большинство грамотно созданных программ подобны пирамиде с уровнями абстракции. Классы/функции верхних уровней разбивают сложную задачу на подзадачи, тогда как классы/функции нижних уровней абстрагируют реализацию подзадач, таких как черные ящики, и предоставляют интерфейсы для вызова верхним уровнем. Эта парадигма облегчает программирование, поскольку каждый уровень сосредоточен на своей логике, не беспокоясь о всевозможных деталях.
Например, веб-сайт может состоять из следующих уровней: бизнес-логика, HTTP и TCP/IP. Реагируя на URL-запрос, уровень бизнес-логики решает, какую веб-страницу показать, и отправляет ее контент на уровень HTTP, где он превращается в HTTP-ответ. Следующий уровень TCP/IP преобразует HTTP-ответ в пакеты TCP и рассылает их.
После такой централизации вы можете начать изучать логи вместе с распределенными трассировками запросов и метриками инфраструктуры. Такие службы, как Datadog, могут соединять журналы с метриками и данными мониторинга производительности, чтобы помочь вам увидеть полную картину.
Если вы обновите формат для включения dd.trace_iddd.span_id, система управления автоматически сопоставит журналы и трассировки каждого запроса. Это означает, что при просмотре трассировки вы можете просто щелкнуть вкладку “логи” в представлении трассировки, чтобы просмотреть все логи, созданные во время конкретного запроса:
Можно перемещаться в другом направлении: от журнала к трассировке создавшего журнал запроса. Смотрите нашу документацию для получения более подробной информации об автоматической корреляции логов и трассировок для быстрого устранения неполадок.
Подробности
Что делать, когда приложение разрастается? Вам нужна надёжная, масштабируемая конфигурация и имя логгера как часть каждого лога. В этой части мы:
Ключевые характеристики
Логирование состояний напоминает создание эскизов программы только с учетом ключевых характеристик основ бизнес-логики. Если есть информация закрытого характера, например персональные данные, то ее также нужно записать в лог, но в завуалированном виде.
Например, когда HTTP-сервер переходит из состояния ожидания запроса в состояние получения запроса, он должен зафиксировать в логе HTTP-метод и URL, так как они описывают основы HTTP-запроса. Остальные его элементы (заголовки или часть тела сообщения) записываются в том случае, если их значения влияют на бизнес-логику. Например, если поведение сервера сильно отличается между состояниями Content-Type:application/json и Content-Type:multipart/form-data, заголовок следует записать.
Ведите логи только на правильных уровнях
Как следствие абстракции, разные уровни имеют разные степени понимания выполняемой задачи. В предыдущем примере уровень HTTP не владел данными ни о количестве отправляемых пакетов TCP, ни о намерении пользователей в момент URL-запроса. Предпринимая попытку логирования, разработчикам следует выбрать правильный уровень, который содержит полную информацию о переходах состояний и причинах.
Вернемся к нашему примеру проверки корректности номера социального страхования. Допустим, что логика его проверки обернута в класс Validator следующим образом:
Есть еще другая функция, которая проверяет запрос, обновляющий информацию о пользователе, и вызывает проверку номера социального страхования.
Однако это вовсе не означает, что логирование на нижних уровнях программы совершенно необязательно, особенно когда они не раскрывают ошибки верхним уровням. Например, сетевой уровень может иметь встроенную логику повторных попыток, из чего следует, что верхние уровни не замечают проблем с прерывающимися соединениями. В общем, нижние уровни могут вести логи больше на уровне DEBUG, чем на INFO, в целях сокращения многословности. При необходимости разработчики могут настроить уровень лога для получения большего количества деталей.
Посмотреть логи windows PowerShell
Было бы странно если бы PowerShell не умел этого делать, для отображения log файлов открываем PowerShell и вводим вот такую команду
Get-EventLog -Logname ‘System’
В итоге вы получите список логов журнала Система
Тоже самое можно делать и для других журналов например Приложения
Get-EventLog -Logname ‘Application’
небольшой список абревиатур
Например, для того чтобы в командной оболочке вывести события только со столбцами «Уровень», «Дата записи события», «Источник», «Код события», «Категория» и «Сообщение события» для журнала «Система», выполним команду:
Если нужно вывести более подробно, то заменим Format-Table на Format-List
Как видите формат уже более читабельный.
Так же можно пофильтровать журналы например показать последние 20 сообщений
Get-EventLog –Logname ‘System’ –Newest 20
Или выдать список сообщение позднее 1 ноября 2014
Get-EventLog –LogName ‘System’ –After ‘1 ноября 2014’
Программа как переходы состояний
Программа — это серия переходов между состояниями.
Состояния — это вся информация, которую программа хранит в своей памяти в определенный момент времени, а код программы определяет то, как она переходит от одного состояния к другому. Разработчики, использующие императивные языки программирования, такие как Java, зачастую акцентируют больше внимания на самом процессе (коде), чем состояниях. Однако понимание того, что программа является серией состояний, очень важно, поскольку они существенно ближе к тому, что должна делать программа, а не как.
Допустим, есть робот, задача которого — заполнить бензобак машины. Если мы рассмотрим выполняемые им действия как переходы состояний, то ему необходимо перейти от состояния (бак пустой, в наличии 50 $) к состоянию (бак полный, в наличии 15 $). Если же мы описываем его как процесс, то он должен найти заправку, доставить туда машину и заплатить. Конечно же, процесс имеет большое значение, но состояния дают более точную оценку правильности программы.
Дополнительные продукты
Так же вы можете автоматизировать сбор событий, через такие инструменты как:
Так что вам выбирать будь то просмотр событий или PowerShell для просмотра событий windows, это уже ваше дело. Материал сайта pyatilistnik.org
Кто должен записывать логи?
Типичная ошибка, которую многие допускают, связана с тем, “кто” должен фиксировать информацию. Ведение логов не теми функциями оборачивается дублированием или дефицитом информации.
Переход в критическое состояние
Не все переходы состояний стоит записывать в лог. Важно рассмотреть программу как серию изменяемых состояний, разделить их на фазы и затем сосредоточиться на времени, когда выполнение переходит от одной фазы к другой.
Предположим, что существуют 3 фазы запуска приложения:
Запуск приложения с точки зрения переходов состояний
Было бы очень разумно вести логи в начале и конце каждой фазы. Если бы произошла ошибка на этапе подключения к зависимостям и приложение бы зависло, то логи отчетливо показали бы, что после загрузки настроек оно вошло во вторую фазу процесса, не завершив его. Располагая этой информацией, разработчики смогли бы быстро определить проблему.
Как осуществляется процесс отладки?
Прежде чем начать разговор о логах, необходимо ответить на два вопроса:
Рассмотрим простой пример для обобщения всего сказанного. Предположим, что сервер получает некорректный номер социального страхования, и разработчик намерен внести в лог информацию об этом событии.
Вот несколько анти-шаблонов логов, в которых отсутствуют ключевые характеристики состояния и причины:
Все они содержат определенную информацию, но ее недостаточно для ответов на вопросы, которые могут возникнуть у разработчиков в процессе поиска ошибки. Какой запрос не смог обработать сервер? Почему номер социального страхования был отклонен? Какой пользователь столкнулся с этой ситуацией? Грамотный и полезный для отладки лог будет выглядеть так:
Перехват необработанных исключений
Вы не можете предвидеть и обработать все исключения, но можете логировать необработанные исключения, чтобы исследовать их позже.
Если ничего не встретилось, исключение становится необработанным. Интерпретатор вызывает sys.excepthook с тремя аргументами: класс исключения, его экземпляр и трассировка. Эта информация обычно появляется в sys.stderr, но если вы настроили свой лог для вывода в файл, traceback не логируется.
Вы можете использовать стандартную библиотеку traceback для форматирования трассировки и её включения в лог. Перепишем word_count() так, чтобы она пыталась записать количество слов в файл. Неверное число аргументов в write() вызовет исключение:
# lowermodule.pyimport logging.configimport tracebacklogging.config.fileConfig(‘logging.ini’, disable_existing_loggers=False)logger = logging.getLogger(__name__)def word_count(myfile): try: # считаем слова, логируем результат. with open(myfile, ‘r+’) as f: file_data = f.read() words = file_data.split(» «) final_word_count = len(words) logger.info(«this file has %d words», final_word_count) f.write(«this file has %d words», final_word_count) return final_word_count except OSError as e: logger.error(e, exc_info=True) except: logger.error(«uncaught exception: %s», traceback.format_exc()) return Falseif __name__ == ‘__main__’: word_count(‘myfile.txt’)
При выполнении этого кода возникнет TypeError, не обрабатываемое в try-except. Однако оно логируется благодаря коду, включенному во второе выражение except:
# исключение не обрабатывается, но логируется.2019-03-28 15:22:31,121 lowermodule — ERROR:uncaught exception: Traceback (most recent call last): File «/home/emily/logstest/lowermodule.py», line 23, in word_count f.write(«this file has %d words», final_word_count)TypeError: write() takes exactly one argument (2 given)
Логирование трассировки обеспечивает критическую видимость ошибок в реальном времени. Вы можете исследовать, когда и почему они произошли.
Многострочные исключения легко читаются, но если вы объединяете свои журналы с внешним сервисом, то далее можно преобразовать их в JSON, чтобы гарантировать корректный анализ. Теперь мы покажем, как использовать для этого python-json-logger.
Конфигурирование
Следуя лучшим практикам, используем метод получения имени лога модуля:
__name__ ссылается на полное имя модуля, из которого вызван метод getLogger. Это вносит ясность. Например, приложение включает lowermodule.py, вызываемый из uppermodule.py. Тогда getLogger(__name__) выведет имя ассоциированного модуля. Пример с форматом лога, включающим его имя:
# lowermodule.pyimport logginglogging.basicConfig(level=logging.DEBUG, format=’%(asctime)s %(name)s %(levelname)s:%(message)s’)logger = logging.getLogger(__name__)import loggingimport lowermodule logging.basicConfig(level=logging.DEBUG, format=’%(asctime)s %(name)s %(levelname)s:%(message)s’)logger = logging.getLogger(__name__)def record_word_count(myfile): logger.info(«starting the function») try: word_count = lowermodule.word_count(myfile) with open(‘wordcountarchive.csv’, ‘a’) as file: row = str(myfile) + ‘,’ + str(word_count) file.write(row + ‘
‘) except: logger.warning(«could not write file %s to destination», myfile) finally: logger.debug(«the function is done for the file %s», myfile)
Последовательный запуск uppermodule.py для существующего и не существующего файлов даст такой вывод:
Имя модуля логгера следует сразу за временной меткой. Если вы не использовали getLogger, имя модуля отображается как root, затрудняя определение источника. uppermodule.py отображается как __main__ (основной) потому, что это модуль верхнего уровня.
Сейчас два лога настраиваются двумя вызовами basicConfig. Далее мы покажем, как настроить множество логов с одним вызовом fileConfig.
Логирование исключений
Чтобы logging.error перехватывала трассировку, установите sys.exc_info в True. Ниже пример с включенным и отключенным параметром:
# lowermodule.pylogging.config.fileConfig(‘/path/to/logging.ini’, disable_existing_loggers=False)logger = logging.getLogger(__name__)
Вывод для несуществующего файла:
Первая строка — вывод без трассировки, вторая и далее — с трассировкой. Кроме того, с помощью logger.exception вы можете логировать определённое исключение без дополнительных вмешательств в код.
Унификация
В этом разделе мы покажем, как форматировать журналы в JSON, добавлять пользовательские атрибуты, а также централизовывать и анализировать данные.
Удаленный просмотр логов
Далее вы выбираете вкладку «События», выбираете нужный журнал, в моем примере я хочу посмотреть все логи по системе. С моей точки зрения тут все просматривать куда удобнее, чем из просмотра событий. Плюсом будет, то что вы это можете сделать из любого телефона или планшета. В правом углу есть удобная форма поиска
Если нужно произвести более тонкую фильтрацию логов, то вы можете воспользоваться кнопкой фильтра.
Тут вы так же можете выбрать уровень события, например оставив только критические и ошибки, задать временной диапазон, код событий и источник.
Вот пример фильтрации по событию 19.
Указываем имя другого компьютера, в моем примере это будет SVT2019S01
Если все хорошо и нет блокировок со стороны брандмауэра или антивируса, то вы попадете в удаленный просмотр событий .если будут блокировки, то получите сообщение по типу, что не пролетает трафик COM+.
Так же хочу отметить, что есть целые системы агрегации логов, такие как Zabbix или SCOM, но это уже другой уровень задач. На этом у меня все, с вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Как открыть в просмотр событий
Зайти в оснастку Просмотр событий можно очень просто, подойдет для любой версии Windows. Нажимаете волшебные кнопки
Win+R и вводите eventvwr.msc
Откроется у вас окно просмотр событий windows в котором вам нужно развернуть пункт Журналы Windows. Пробежимся по каждому из журналов.
Журнал Приложение, содержит записи связанные с программами на вашем компьютере. В журнал пишется когда программа была запущена, если запускалась с ошибкоу, то тут это тоже будет отражено.
Журнал аудит, нужен для понимания кто и когда что сделал. Например вошел в систему или вышел, попытался получить доступ. Все аудиты успеха или отказа пишутся сюда.
Пункт Установка, в него записывает Windows логи о том что и когда устанавливалось Например программы или обновления.
Самый важный журнал Это система. Сюда записывается все самое нужное и важное. Например у вас был синий экран bsod, и данные сообщения что тут заносятся помогут вам определить его причину.
Так же есть логи windows для более специфических служб, например DHCP или DNS. Просмотр событий сечет все :).
Причина перехода состояния
Логирование причины перехода состояния чрезвычайно полезно для отладки. Логи должны кратко охватывать содержание предыдущих и следующих состояний, а также объяснять их причины. Они помогают разработчикам получить общую картину и ориентироваться в процессе реконструкции (отладки) выполнения программы.
Профессиональный подход к ведению логов
Логи можно сравнить с уликами на месте преступления, а разработчиков — с криминалистами. Роль логов трудно переоценить, ведь когда необходимо найти баг или причину сбоя, сразу обращаются к ним. Подобно тому, как отсутствие улик приводит к нераскрытым делам, отсутствие содержательных логов осложняет диагностику и устранение ошибок, превращая их в затянувшийся или вовсе невыполнимый процесс. Мне приходилось наблюдать, как люди мучились с такими инструментами, как Strace и tcpdump, или развертывали новый код в продакшене во время сбоя лишь затем, чтобы получить больше лог-файлов для выявления проблемы.
Как говорится: “Хорошо подготовиться — половину дела сделать”, так что каждому профессиональному разработчику следует научиться эффективно вести логи и быть готовым к работе с ними. В данной статье мы не только рассмотрим список полезных практик логирования в приложении, но и разберем теоретические основы данного процесса: что записываем, когда и кто этим должен заниматься.
Краткие выводы
Чтобы профессионально писать логи, следует рассматривать программу как серию переходов состояний с уровнями абстракции. Владея теоретическими знаниями, можно ответить на ключевые вопросы о логировании в приложении:
1.Когда писать логи? В момент перехода в критическое состояние.
2.Что записывать в лог? Ключевые характеристики текущего состояния и причину перехода состояния.
3.Кто должен записывать логи? Логирование должно происходить на правильном уровне, содержащем достаточно информации.
4.Каким должно быть количество логов? Определите X-фактор (по формуле # логов = X * # рабочих элементов+ константы) и настройте его экономно, но выгодно.
Читайте нас в телеграмме, vk и Яндекс.Дзен
Заключение
Мы рассмотрели рекомендации по настройке стандартной библиотеки логирования Python для создания информативных логов, их маршрутизации и перехвата трассировок исключений. Также мы увидели, как централизовать и анализировать логи в JSON с помощью платформы управления логами.